概要
由於營運商有成本、SLA 考量,需要在佈建環境前預測 NF 的效能,或需要知道相關參數的修改會對整體系統效能造成多少影響,而前人的預測雖有考慮到 NF 間競爭同個硬體資源的情形,不過所使用的指標略少。
透過簡單實驗可以發現當多個 NF 同時執行,在不同的元件(LLC、DDIO、Cache)上會有不同的資源競爭情況發生,作者歸納出各個元件資源競爭的關鍵要素,使用 scikit-learn 機器學習技術來分析統計,進而提出了 SLOMO 框架,可以在 NF 組態差異不大的情況下進行資源競爭、效能預測。
1. 介紹
為了方便理解,作者循著架構框架的藍圖:
- 記錄在共用同個硬體時,相互競爭 NF 們的壓力
- NF 效能容易受到其他 NF 影響的敏感度
該藍圖有三個關鍵技術挑戰:
- 找出合適的競爭指標
- 使用硬體計數器(針對 CPU-socket, server-level 粒度)
- 評估量測敏感度的模型
- 由於多個影響因子,使得 NF 整體的敏感度不是線性、也不是連續的函數
- 可以將函數分段對應到不同的線性模型來處理,使用機器學習的 ensemble 技術
- 確保競爭指標的可組合性
- 透過簡單的方法如:累加、平均
作者採用數據驅動(data driven)的方式來進行,也就是先求得實驗數據,再深入分析探討已解決問題。
2. 背景
NFV 與 競爭
營運商可能向不同的廠商購買 VNF,並且配置其偏好的組態。
下圖為讓NF 獨立運作時的效能表現:

下圖為當這些 NF 彼此競爭共享硬體資源時的效能表現:
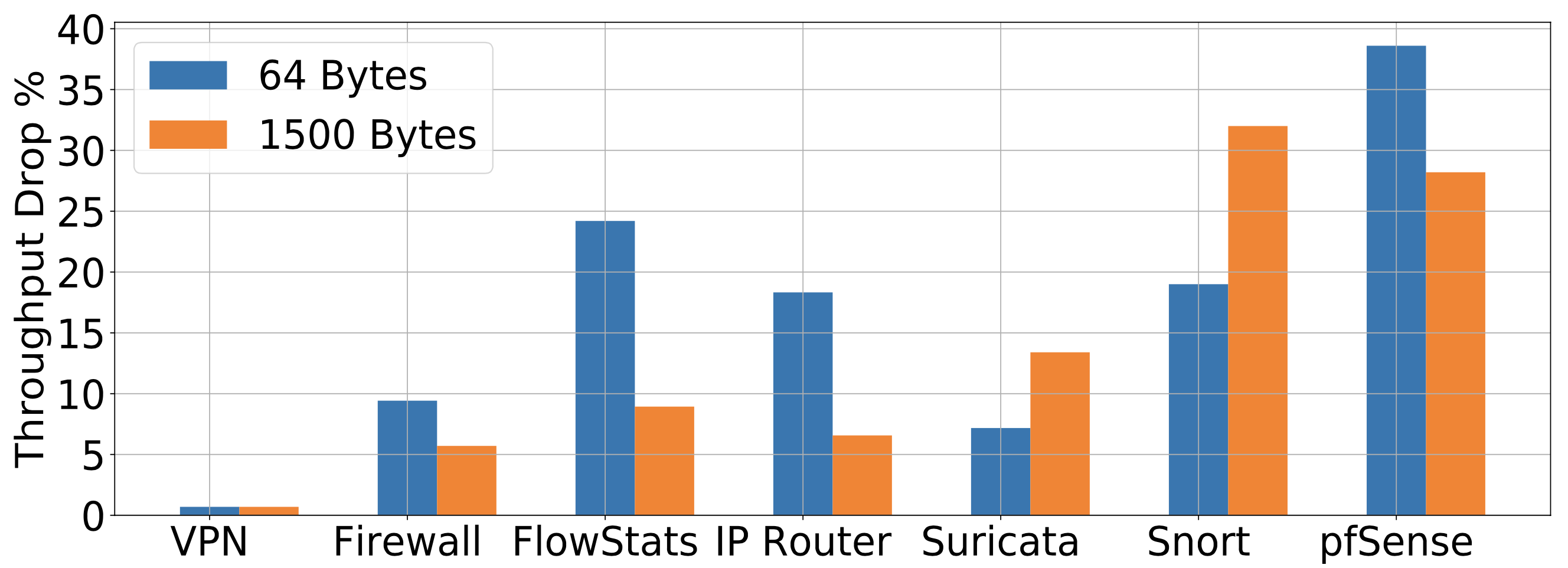
圖1. 競爭導致的吞吐量下降
這些數據的量測都是在 NF 各自佔用獨立 CPU core 的情況與相同的資源,可以看到最高有 35% 的效能影響。
預測問題:
- 輸入NFs: $S={NF_i}$
- 目標: $NF_{target} \in S$ ,預估效能下降目標
- 競爭工作負載:$Comp_j = {S \backslash NF_{target}}$,跟目標同時競爭的其他 NFs
- 硬體配置:$Arch_k$
一般來說工作負載可以有許多面向:記憶體容量、儲存裝置頻寬、CPU 資源(計算單元)、CPU socket 連接網路。然而在 NFV 的情況下通常是 NF process 獨立運作在指定的 CPU 核心上(CPU affinity),因此效能瓶頸會是在 memory subsystem 上。由於 NFV 的特殊性使得在快取的操作上非常頻繁,其中資料結構的重用(reuse)率非常高(像是一些規則、路由表),封包資料重用率則是非常低。
現有方法
現有解決競爭導致效能下降的方法有透過「效能預測」、「硬體資源隔離」:
效能預測
- 在 Dobrescu 的論文 Toward Predictable Performance in Software Packet-Processing Platforms 中,指出記憶體的競爭是導致 NF 效能下降主因。作者將記憶體視為 monolithic 的競爭源頭,透過單一的 cache access rate (CAR) 來當作指標。
- 上者呼應了 BubbleUp 作品,其為一個通用型的框架,也是替記憶體競爭進行建模,將 working set size of competing work loads 當作單一競爭指標。
- 下圖為這兩者的預測錯誤率:
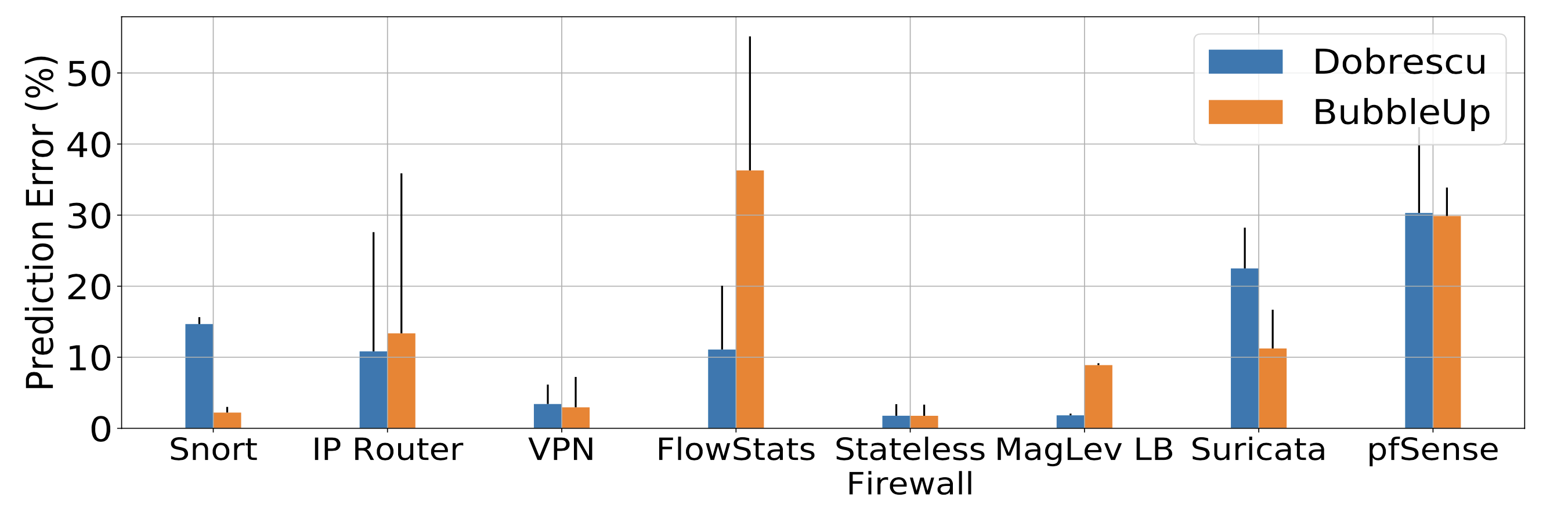
效能隔離(Performance Isolation)
- ResQ 中主張隔離共享資源以避免競爭導致的效能下降,其利用了 Intel Cache Allocation Technology (CAT) 與 DPDK packet buffer sizeing 以提供專屬、不重疊的 LLC 分區給共享資源的 NFs。
- 但是本文作者發現,使用隔離技術來避免競爭導致的效能下降是一個不夠全面的解法,因為分區工具(像是 CAT)並無法完全隔離所有競爭資源,且隔離會導致資源利用率不足!
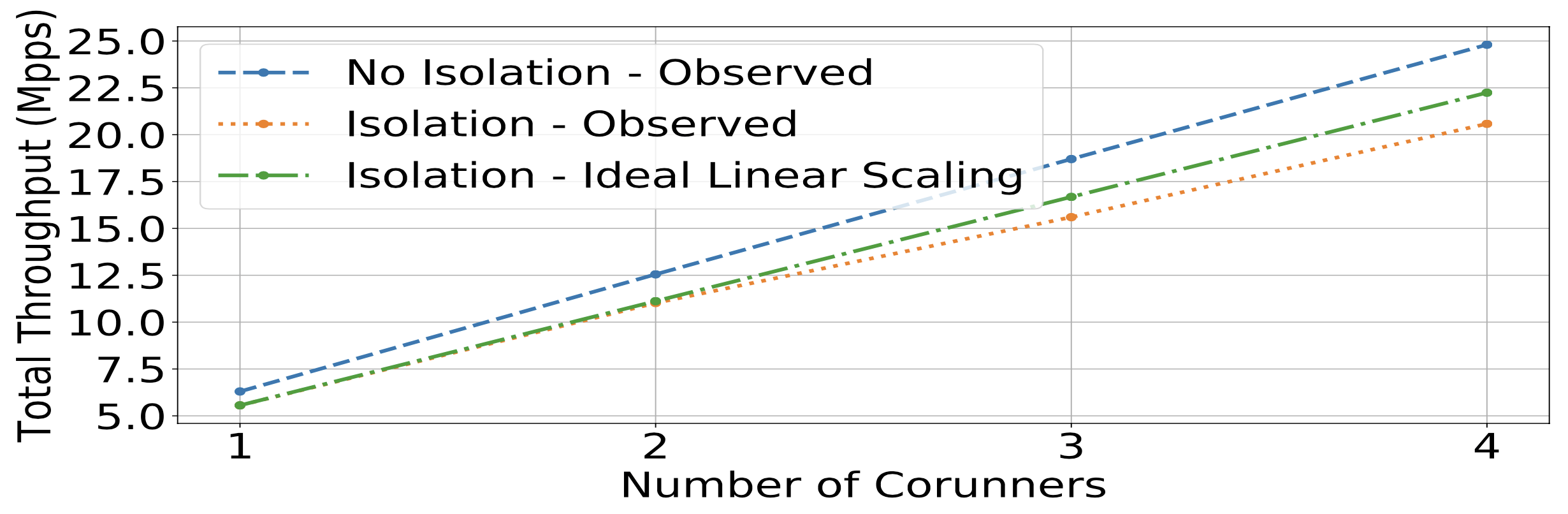
上圖顯示了 LLC 分區會導致資源利用率不足,且無法消除效能下降問題。這代表縱使 LLC 完美的隔離了,依舊無法隔離所有可能的資源競爭。
編按:ideal linear scaling 應該是從前兩個 Isolation - Observed 線性推敲而來。
3. 競爭的資源
雖然前人指出 memory subsystem 是主要競爭的源頭,但是作者使用現代機器實驗所得結果顯示,來源有許多種。為了釐清,作者觀察了封包的生命週期:
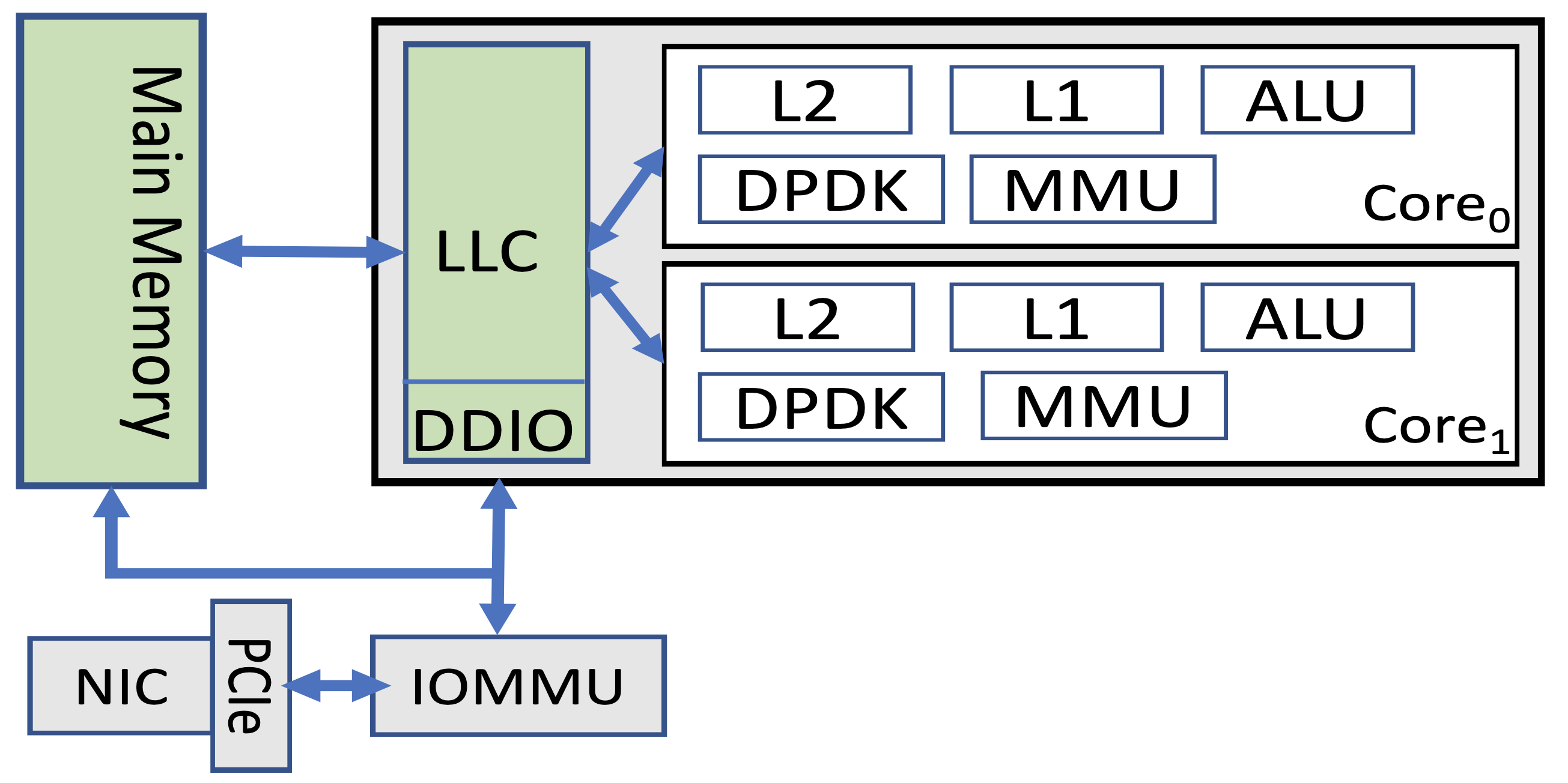
在封包到達網卡時,會經過 PCIe 匯流排,再經由 DMA 機制到達 memory 或是 LLC(取決於是否有 DDIO 機制)。不同的 NF 會對封包有不同的處理,有些會需要從記憶體中載入輔助用的資料結構。最後封包從反向路徑回到網卡。
沿著這條資料路徑,可以看到有三種獨立的競爭資源:
- LLC 資源
- 競爭使得用於封包處理的輔助用資料結構被迫離開快取
- DDIO 資源
- 競爭使得封包在網卡與 LLC 中的傳輸變慢
- 記憶體頻寬
- 競爭使得 LLC miss 後的延遲增加
環境設置:
- 兩台主機
- Intel Xeon E5-2620 v4 (Broadwell)
- Intel XL710-40Gbps * 2
- Intel Xeon Silver 4110 (Skylake)
- Mellanox MT27700-100Gbps * 2
- Intel Xeon E5-2620 v4 (Broadwell)
- 使用 SR-IOV 對 NFs 共享資源
測試用的 NF:
接著要來測試不同競爭資源所造成的影響,需要注意的是這些影響因子可能不是獨立的,而是會相互影響的,例如「增加整體請求頻率的話,會增加 cache 存取率、記憶體頻寬」。
LLC 的競爭
前人對記憶體競爭的建模僅專注於 LLC 而已,Dobrescu 的作品與 BubbleUp 專注於這種競爭,但卻使用不同的指標。
- Dobrescu 量測競爭 NF 的 cache access rate (CAR)
- BubbleUp 量測競爭 NF 的 working set size 或是 cache 佔用量
在作者的伺服器上,這兩個指標都對效能降低提供了非常明確的指引。
觀察 1:LLC 競爭取決於「cache 佔用量」、「cache access rate」。
在實驗當中,為了確保沒有受到其他干擾,作者沒有使用 DDIO,也讓不同 NF 分別使用獨立的記憶體通道。
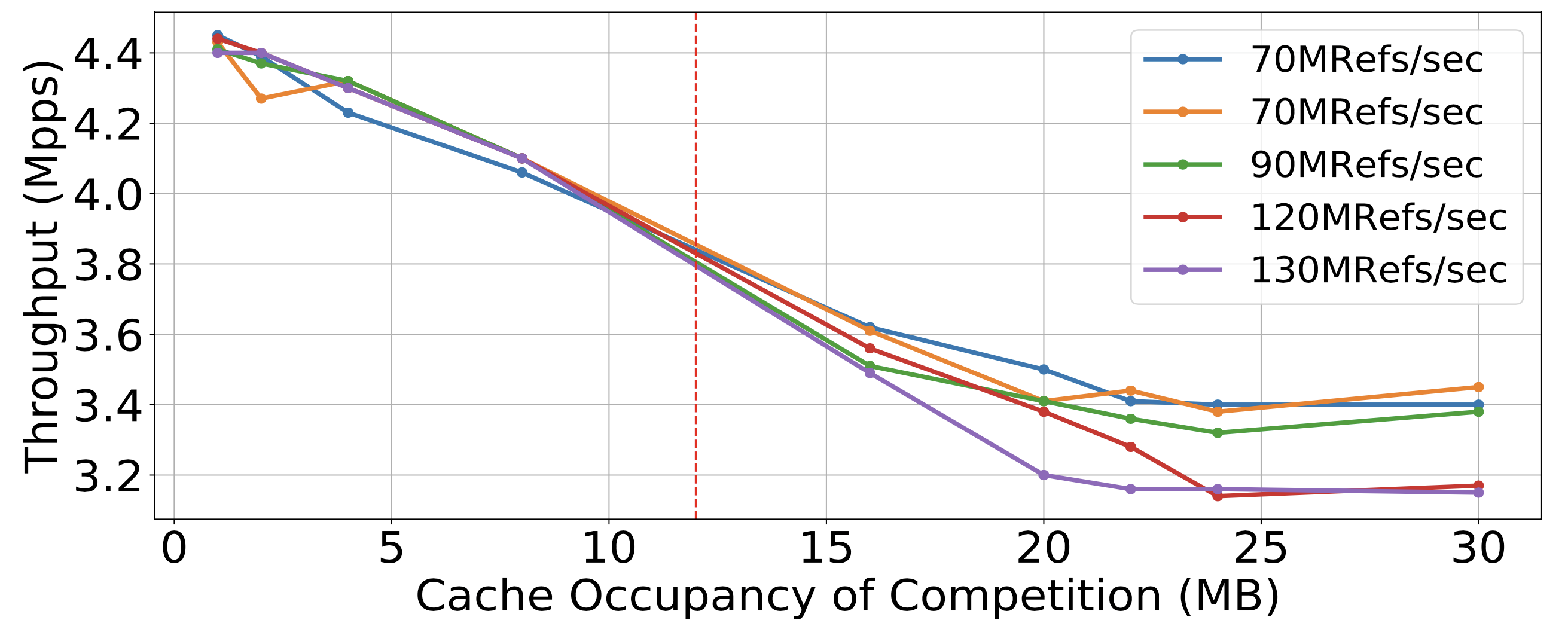
上圖紅色虛線表示 LLC 總容量。
- 沒有超過時,佔用率是最佳的效能預測指標
- 超過時,CAR 是最佳的效能預測指標
封包 IO 的競爭
現代的 Intel CPU 有提供 DDIO 功能,其會將 LLC 切成 primary cache 與 I/O cache 兩塊。在 NF 啟動期間,會指定一塊 I/O cache 用來儲存封包。
競爭發生在同時間封包總數超過 I/O cache 的大小,就算 LLC 尚未超載也一樣。
編按:可是每個 NF 固定大小的話,怎麼會影響到其他 NF 呢?
因此,針對 DDIO 專屬 cache 競爭的問題,必須要從 LLC 競爭問題中獨立出來建模。
觀察 2:DDIO 競爭取決於「競爭者的 DDIO 空間使用」、「存取頻率」
作者發現並不是所有 NF 都對 DDIO 競爭一樣敏感(跟封包大小、分配 buffer 大小無關),但都會因此受到效能上的影響。
下圖中,無狀態防火牆在上(分配 524KB buffer),L2 forwarder 在下(分配 3 MB buffer)。
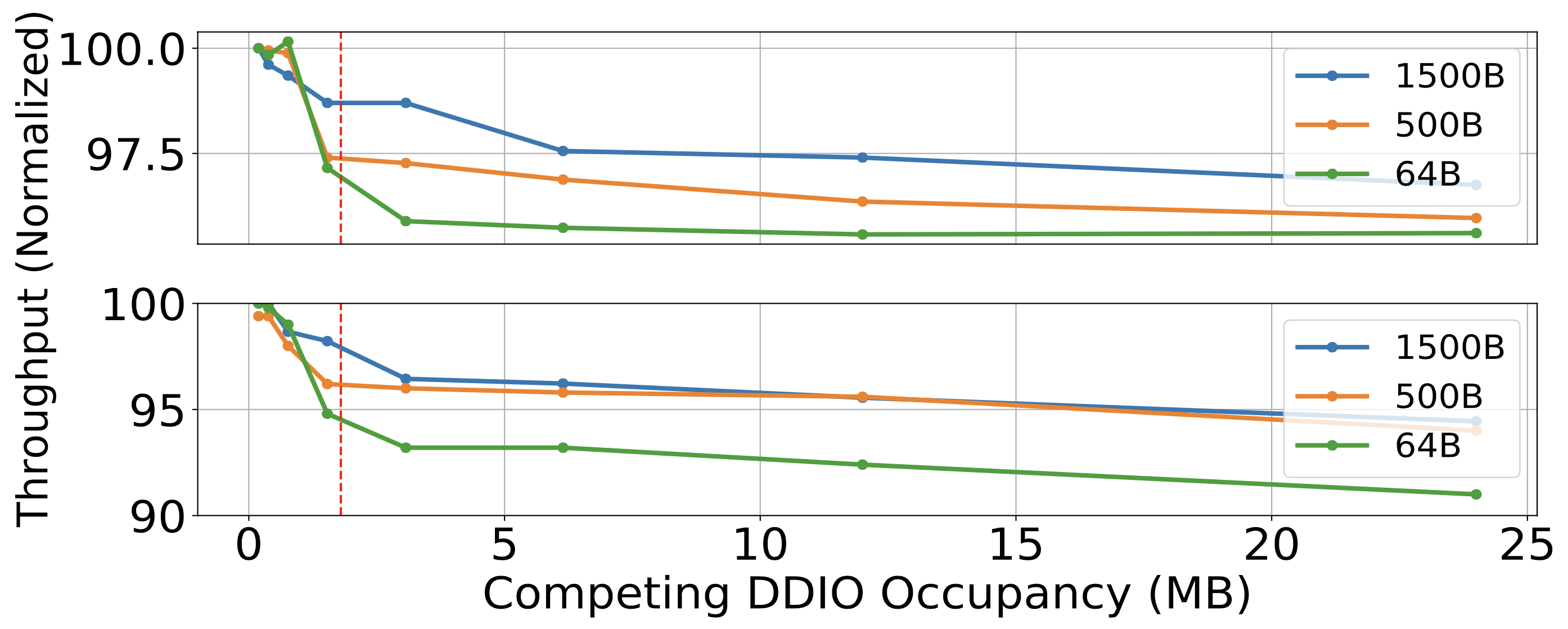
競爭的 L2 forwarder 有確保讓 DDIO 之外的 LLC 競爭降到最低,並且用到最高 100Gbps 流量。
在 L2 forwarder 中作者透過調整「不同大小的 buffer allocated (occpuancy)」以及「送到 L2 forwarder 的封包大小」,以控制封包到達速率、記憶體存取次數。
其結果如同 LLC 競爭的圖,作者觀察到快取的 I/O slice 效能降低的函數是由「occupancy」與「access rate」構成的。
因此為了準確預測,我們除了需要量測 LLC 的「access rate」與「occupancy」,也需要量測 I/O slice 的「access rate」與「occupancy」。
記憶體頻寬競爭
到目前為止,我們已經看到 NF 效能下降的原因有資料結構從 LLC 中逐出、封包從快取的 I/O slice 中逐出。接著我們要討論當競爭者增加快取與記憶體間頻寬使用時開銷有多高。
觀察 3:主記憶體延遲取決於競爭 NFs 的整體頻寬消耗
作者發現在實驗當中因為主記憶體頻寬的競爭會導致高達 18% 的吞吐量下降。
為了確保競爭量測實驗僅限於主記憶體頻寬使用,作者使用了 CAT 技術來切割 LLC,目標 NF 分配 2MB(維持對主記憶體定量存取),競爭者們用 18 MB(並且有大量 cache miss,造成對主記憶體大量存取)。
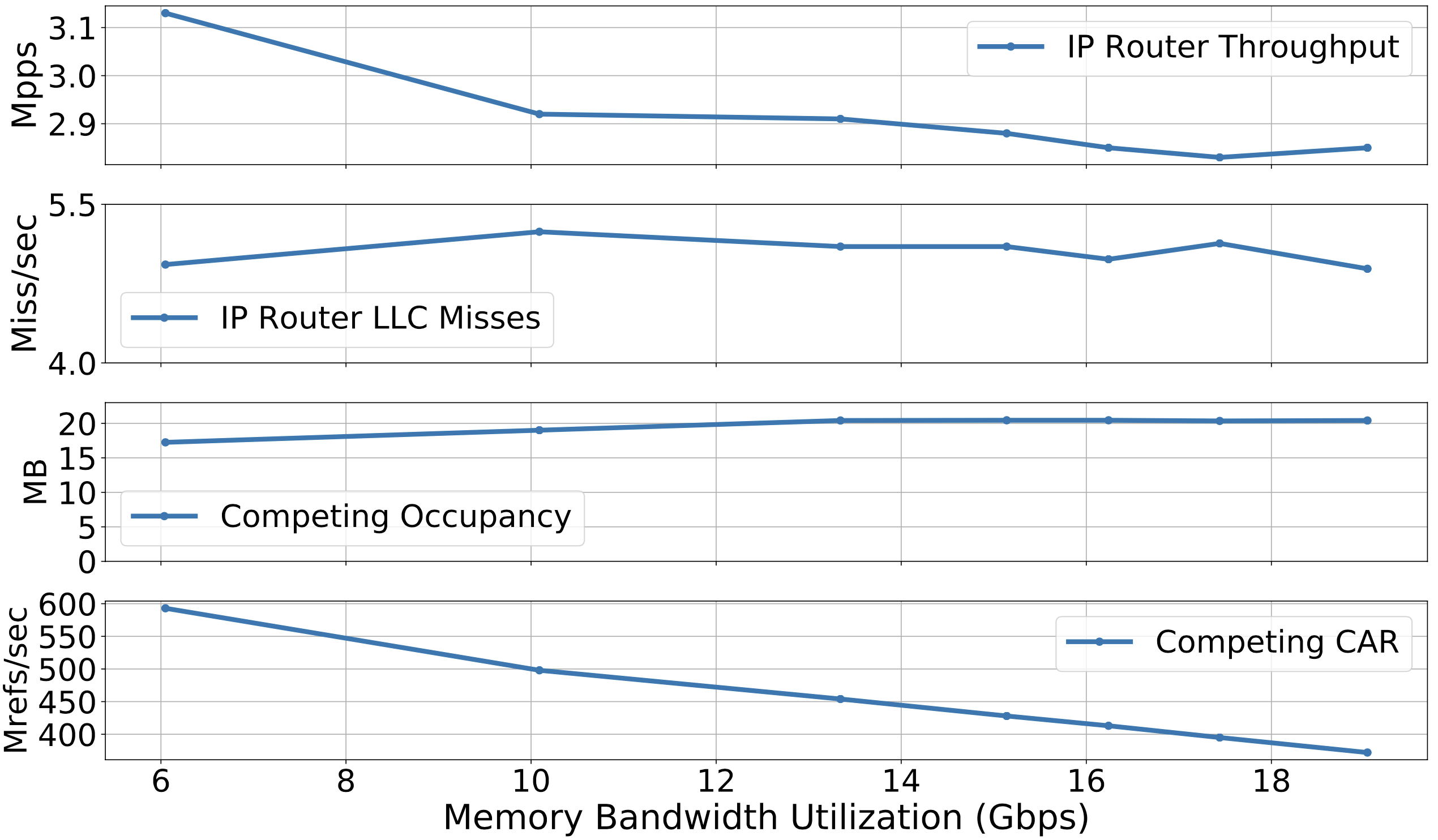
上圖可以看到 IP Router 並不會因為 cache access 的競爭導致 cache miss rate 有所變動(CAT)的關係,但是吞吐量就有明顯下降了。
編按:圖中標籤 Mrefs 是指 memory reference。但 X 軸代表什麼哩?🤔
4. SLOMO 概觀
概念上可以分為兩部份:
- 離線版:替所有 NF instance 描繪出競爭因子、對敏感度進行建模
- 線上版:對給定的 NF instance 進行效能預估,同時考量到現實競爭者
離線分析
- $S = {NF_i…}$,NF 集合
- $Arch_k$,伺服器架構
- $(NF_i, Arch_k)$,競爭元組(contentiousness tuple)
- $V_x$,不同 synthetic 設定檔 x 的競爭向量
- $P_i^x$,不同設定檔下的 $NF_i$ 效能表現
- $M_i: V \rightarrow P$ ,敏感度模型
- ${V_i^x}$,不同設定檔底下 $NF_i$ 的競爭(壓力)指數
給定 NF 集合 $S$ 與伺服器架構 $Arch_k$,SLOMA 會分析出「敏感度」與「競爭元組」。
為了得到這些數據,營運商會準備多種 tunable synthetic workload 設定檔,並且調整不同的系統壓力以測試 $NF_i$。
為了分析敏感度,作者為每個架構量測不同設定檔下的效能表現 $P_i^x$,並使用資料集 ${(V_x,P_i^x), …}$ 來訓練敏感度模型來預測在真實競爭環境下 NF 的效能表現。
這些資料集專注於:
- 特定 NF 種類
- 設定檔
- 流量負載
- 伺服器架構
實務上,典型的叢集只會使用少數幾款伺服器架構,且不太會頻繁改變。不過卻很常在部署後因為一些需求而調整 NF 的設定檔,或是流量可能會改變。
雖然與前人(Dobrescu、BubbleUp)的 workflow 相像,但是前人只用單一指摽的線性模型來進行敏感度、競爭判斷。而本文作者採用多變數、多指標的模型來達成。
線上預測
兩個 NF 預測:
在最基礎的環境底下,假設有兩個 NF: $NF_A, NF_B$ 同時運行,如果要預測 $NF_A$ 的吞吐量,那營運商會將 $NF_B$ 的競爭向量 $V_B$ 放到 $NF_A$ 的敏感度模型 $M_A$ 中以產生效能表現 $P_A^B$。
三個 NF 預測:
假設有 $NF_A, NF_B, NF_C$ ,則 SLOMO 會使用 composition 函數 $CF: V_B,V_C \rightarrow V_{B,C}$ 來離線計算 $V_{B,C}$ 。接著就可以用兩個 NF 預測的方式來計算出預測結果。
5. 深入 SLOMO
有了三個關鍵元件:競爭描繪(contentiousness characterization)、敏感度建模、競爭組成(contentiousness composition),我們可以開始使用 data-driven 方式來設計這些元件。
- 將敏感度建模是 模型擬合過程(model fitting process)
- 挑選競爭因此是 特徵挑選過程(feature seelction process)
- 競爭組成是 迴歸建模問題(regression modelling problem)
候選競爭因子:
作者根據 Intel Performance Counter Monitor (PCM) 來挑,因為 PCM vector 包含主記憶體流量、LLC hit rate 等資料,可惜的是沒有深入網卡的相關資訊。
合成的競爭(synthetic competition):(只用在離線分析)
為了產生競爭向量,作者在每個 NF 上施加可控的合成流量(synthetic workload),並將 NF 可能產生的競爭值都取樣。
作者使用 Click 為基礎的 NF 來實驗,施加壓力的對象有:
- I/O datapath(藉由給定的 packet buffer)
- Packet-processing datapath(藉由改變存在 LLC 的資料結構大小以改變記憶體操作次數)
同時透過改變流量特徵如:速率、封包大小、流量數、同時運行的 instance 數。
因此 SLOMO 會針對每個 NF 進行至少 1000 種不同的設定檔實驗,其結果包含:
- 合成流量 與 NF 各自單獨運行時 PCM 的值
- 合成流量、NF 一起運行時時 PCM 的值
- 合成競爭對手(synthetic competitor)、NF 一起運行時 NF 的效能表現
NF 部署時的假設:
SLOMO 遵循前人建立的最佳實務來最佳化軟體封包處理器的效能穩定性。
特別的是,作者將每個 NF 運行在獨立且隔離的 CPU 核心上,且使用 local memory 與 NIC(NUMA affinity),並且關閉 CPU 省電模式,也停用了 transparent huge page。
競爭指標的選擇
為了避免 PCM vector 中(共約 600 項)不相干的指標影響到整體模型預測的正確性,因此作者有挑選幾個重要指標來進行訓練。
由於沒有相關的 model 可以使用,作者選擇用 model-free 的方式來進行。在許多可取得的技術當中,如:Pearson correlation coefficient、information gain、PCA 中,作者選擇了 Pearson correlation coefficient 來分析「多個 PCM 指標」與「觀察到的效能」在統計上的相依性。
觀察 4:在 CPU socket 與系統層級上的 PCM 指標粒度充分的擷取了整體競爭
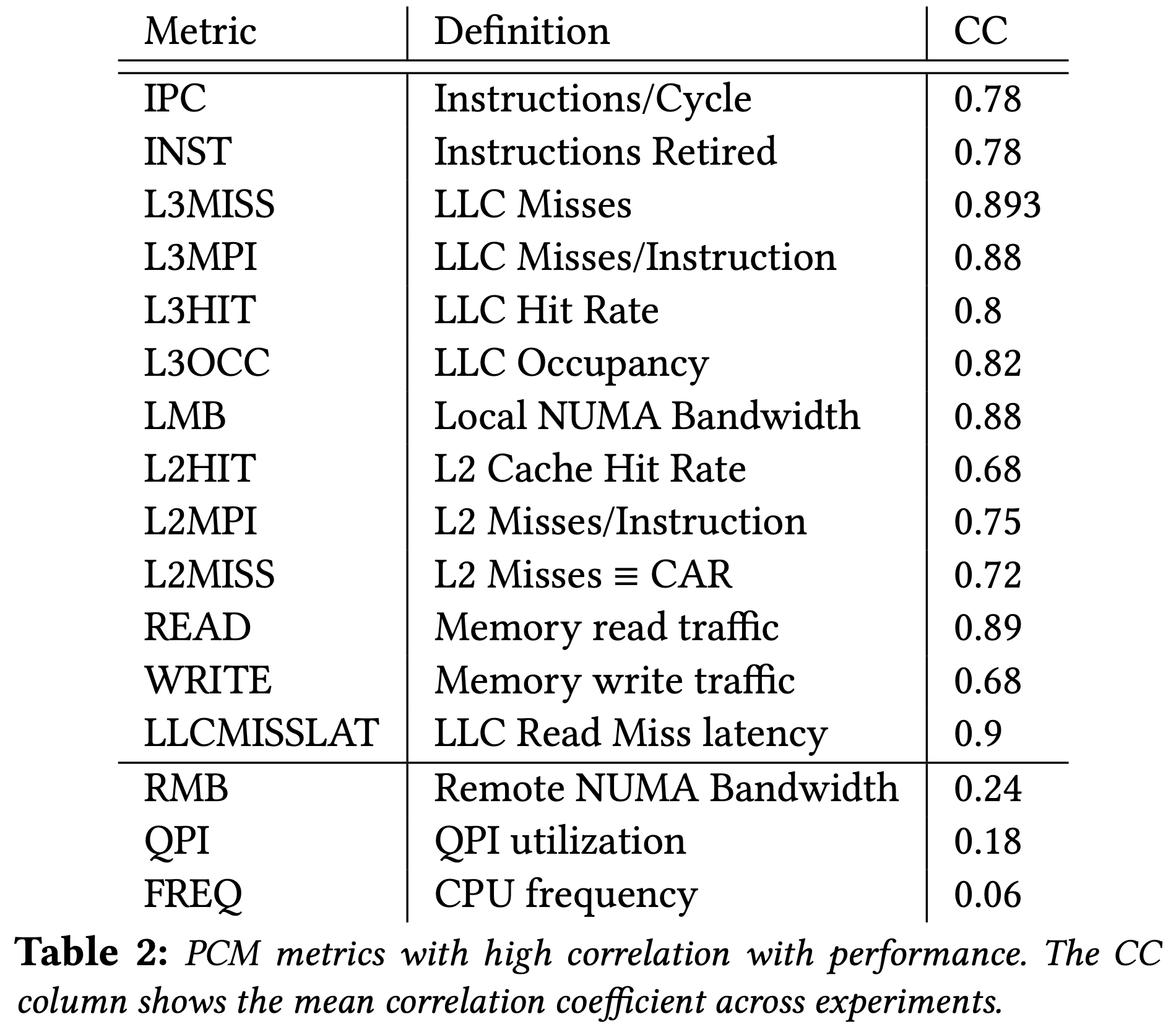
上圖列出了在所有實驗中與效能表現相關的指標,可以觀察到是 CPU socket 與系統層級上的粒度,而不是 core 層級,這是因為效能降低原因是競爭共同資源的關係。
同時也觀察到並沒有特別突出的數值,代表效能降低的原因有很多種可能。
觀察 5:不同的資源其競爭指標也不太相同,然而這都會對 NF 有效能上的影響。
DDIO 競爭:可以觀察到主要是在記憶體頻寬用量上。當 DDIO 操作由 socket 上的 DMA 引擎管理時,封包 buffer 驅逐(eviction)並不會被 LLC utilization 指標擷取到。
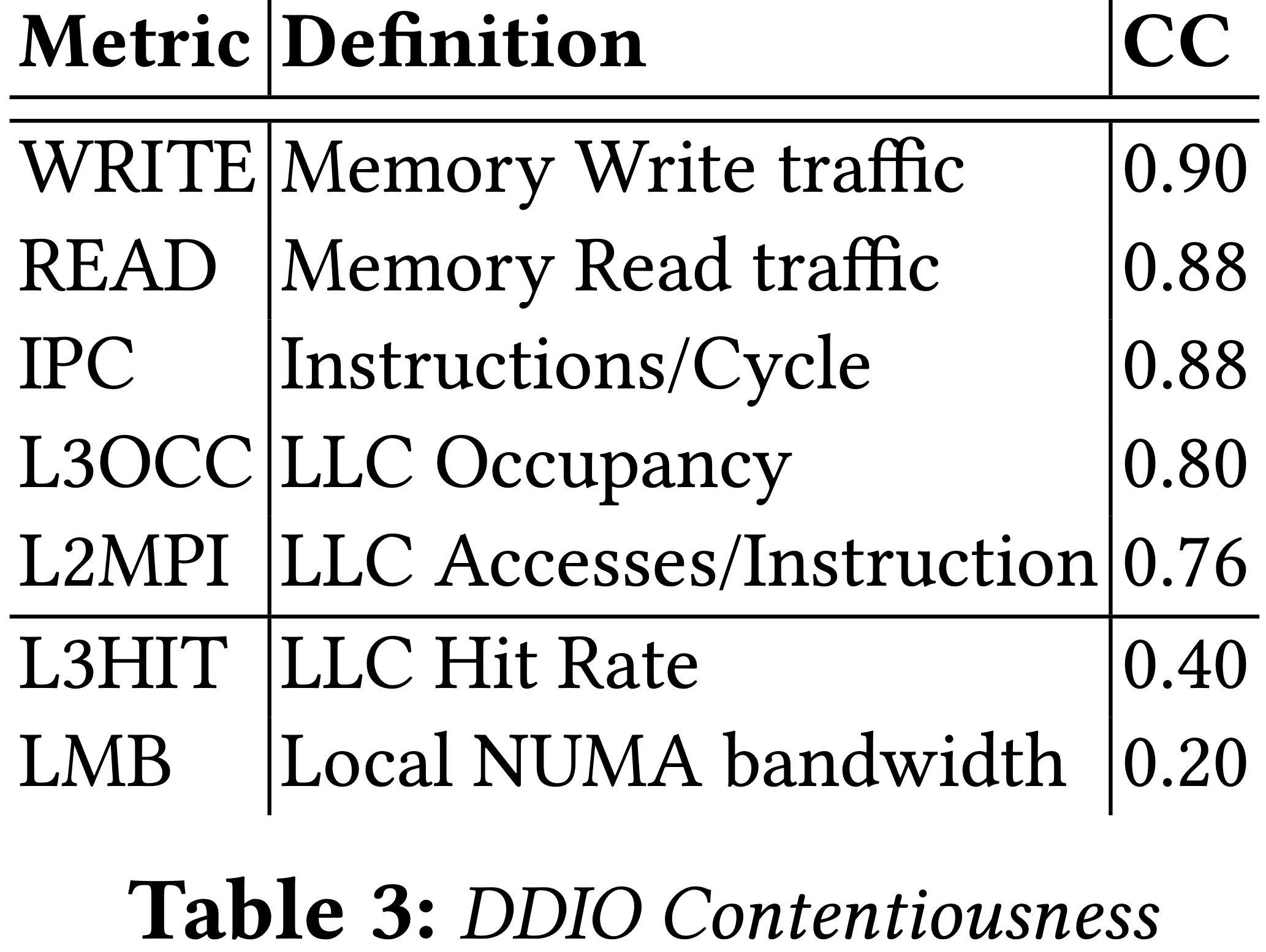
LLC 競爭:與 DDIO 競爭相反的是,LLC 競爭幾乎是由 LLC utilization 相關的指標擷取到。
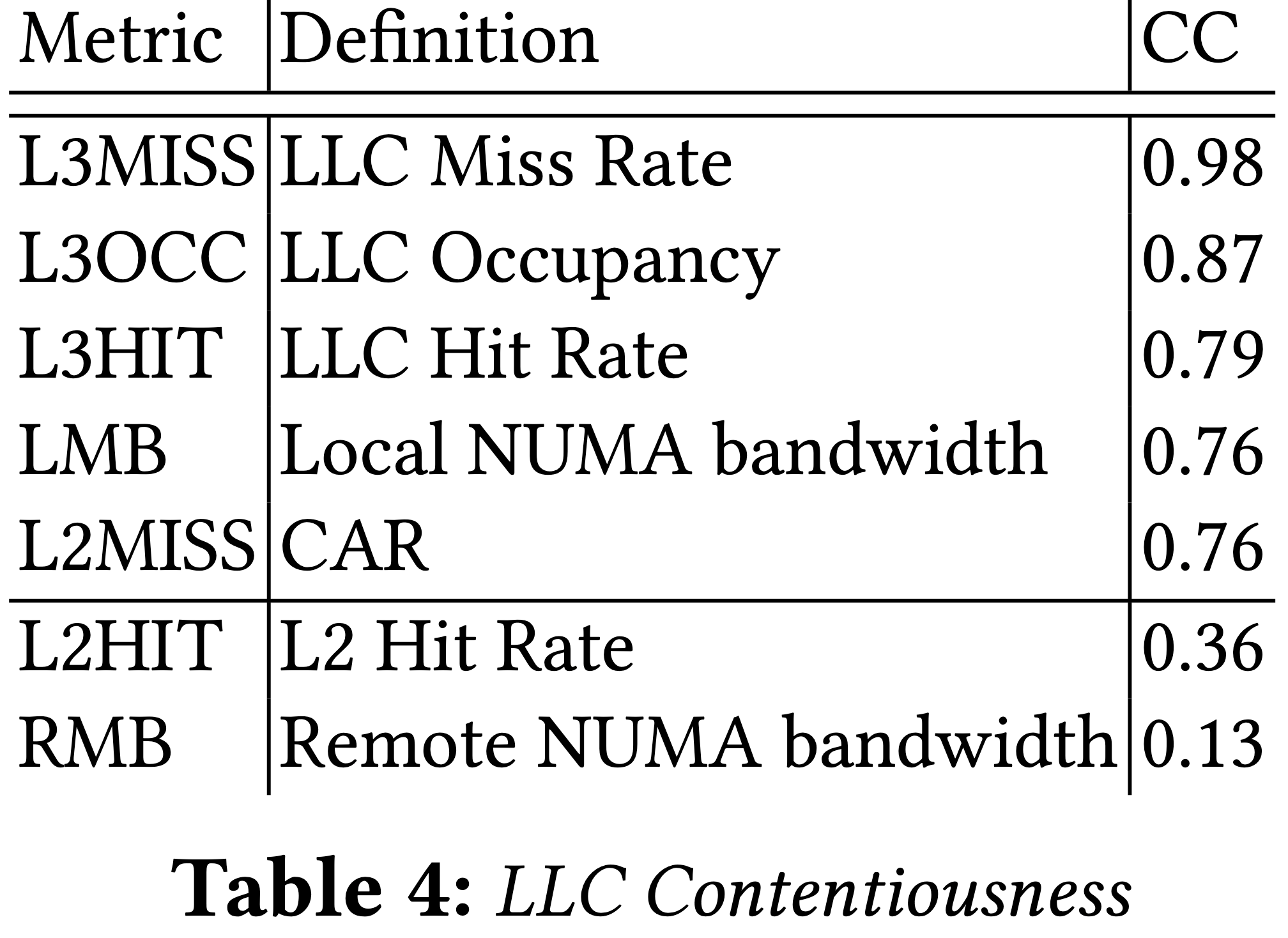
記憶體頻寬:最相關的指標當然是記憶體頻寬用量相關的指標。
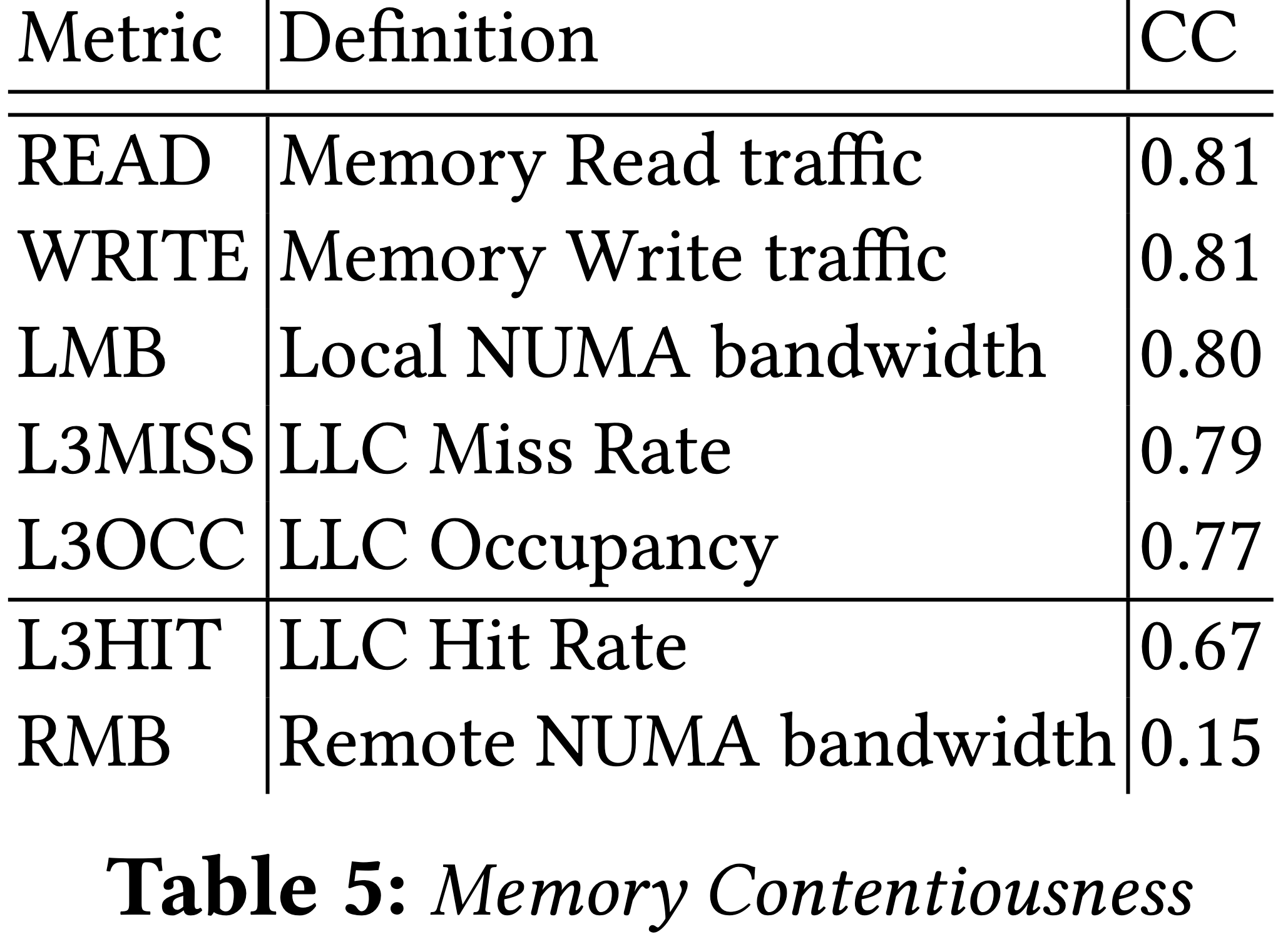
因此,作者從約 600 項 PCM 指標中,挑出最重要的 15 項可以用來顯示競爭狀況的指標。
敏感度建模
敏感度擷取了競爭狀況與 NF 效能表現間的關係,因此敏感度建模可以視為迴歸問題:其輸入(contentiousness of the competition)、輸出(目標 NF 的效能表現)皆為連續變數。
作者的第一個發現是敏感度必須要對每個 NF 建模,因為不同 NF 對各種指標有不同的反應結果。
- 在訓練模型時,使用合成、特定於 NF 的競爭因此(上面提到的)
- 在執行期間,合成輸入(synthetic inputs) 改成實際競爭者的整體競爭(aggregate contentiousness of the real competitors)。
- 在測試時,替不同 NF、架構產生真實實驗的測試集,也就是多個 NF 一起運行,且有多重組合(共 150 種不同的競爭者組合)。
觀察 6:敏感度可以是不能被簡單迴歸模型擷取到的函數
作者發現敏感度是多元輸入 非線性、非連續的函數,因此無法被迴歸(線性、多項式等等)、決策樹、簡單神經網路 精確的建模。
編按:怎麼發現?
儘管如此,常用來偵測敏感度函數的模式還有 相變(phase transitions),像是有個給定大小的競爭 CAR,低 LLC 佔用量自然會驅逐較少的 NF 資料,一但超過某個特定閾值則驅逐量會大增。
觀察 7:敏感度可以依照其輸入分段(piecewise)建模。梯度提升迴歸(Gradient Boosting Regression)是一種集成學習(ensemble modeling)技術,可使得敏感度更加準確。
將敏感度視為一個關於競爭指標的 piecewise 的函數,我們可以將敏感度不同的子空間(sub-spaces)分別進行建模,接著將產出的模型結合成一個更大、更完整的模型,而作者選擇了梯度提升迴歸技術。
綜合來說,作者的方法擷取了錯綜複雜的敏感度函數,且改善了前人的線性模型。
測量競爭
在 4.2 節有提到三個 NF 競爭問題,這邊來談談 $(V_B,V_C)$ 的量測細節、如何離線計算他們的綜合競爭性 $V_{B,C}$。
測量 $NF_i$ 的競爭
- 讓 $NF_i$ 單獨在伺服器上運行,然後記錄其 PCM,這樣的做法是不準確的(沒考慮到競爭)
- 在多種競爭者 $NF_x$ 的情況下量測 $NF_i$ 的競爭狀況多次,每次 $NF_i$ 都會是在不同 $V_x$ 的狀況下,以得到多組潛在 $V_i$。
- 接著將 $V_i^x$ 依照有多少個一同運行的 NF(也就是用了幾顆核心)進行分組,接著將所有資料取平均的值便是 $V_B^C$。
因此,在分析階段對每個 NF 產生多筆競爭向量,對每個設定檔都做競爭向量的量測,在執行階段也是,接著根據競爭者的個數來選擇這些量測最適合的子集。
組成
根據定義累加或是平均計算這些 per-core 指標(例如每個 CPU socket 的 CAR 是其內部所有核心的總和)是可行的,在後續實驗中顯示此預測方法誤差控制在 5% 內。
編按:什麼定義?
6. 敏感度外推
編按:「在數學中,外推(英語:extrapolation)是指從已知數據的孤點集合中構建新的數據的方法。與內插類似,但其所得的結果意義更小,而且更加受不確定性影響。」— 維基百科
到目前為止,我們已經考慮到相對嚴格的 $NF_i$ 定義,包含其種類(如:防火牆、IDS)、設定檔、流量分析。然而 $NF_i$ 可能會在其生命週期中發生一些改變(跨主機遷移、設定改變、流量改變),當這些改變發生後我們就會將其視為不同的 NF instance ─ $NF_i’$。
所幸,SLOMO 有提供一個還算快的外推方式來對付 $NF_i’$,就不用再次進行速度緩慢的離線分析,其採用原先 $NF_i$ 的既有分析資訊來進行預估,可以節省不少時間。
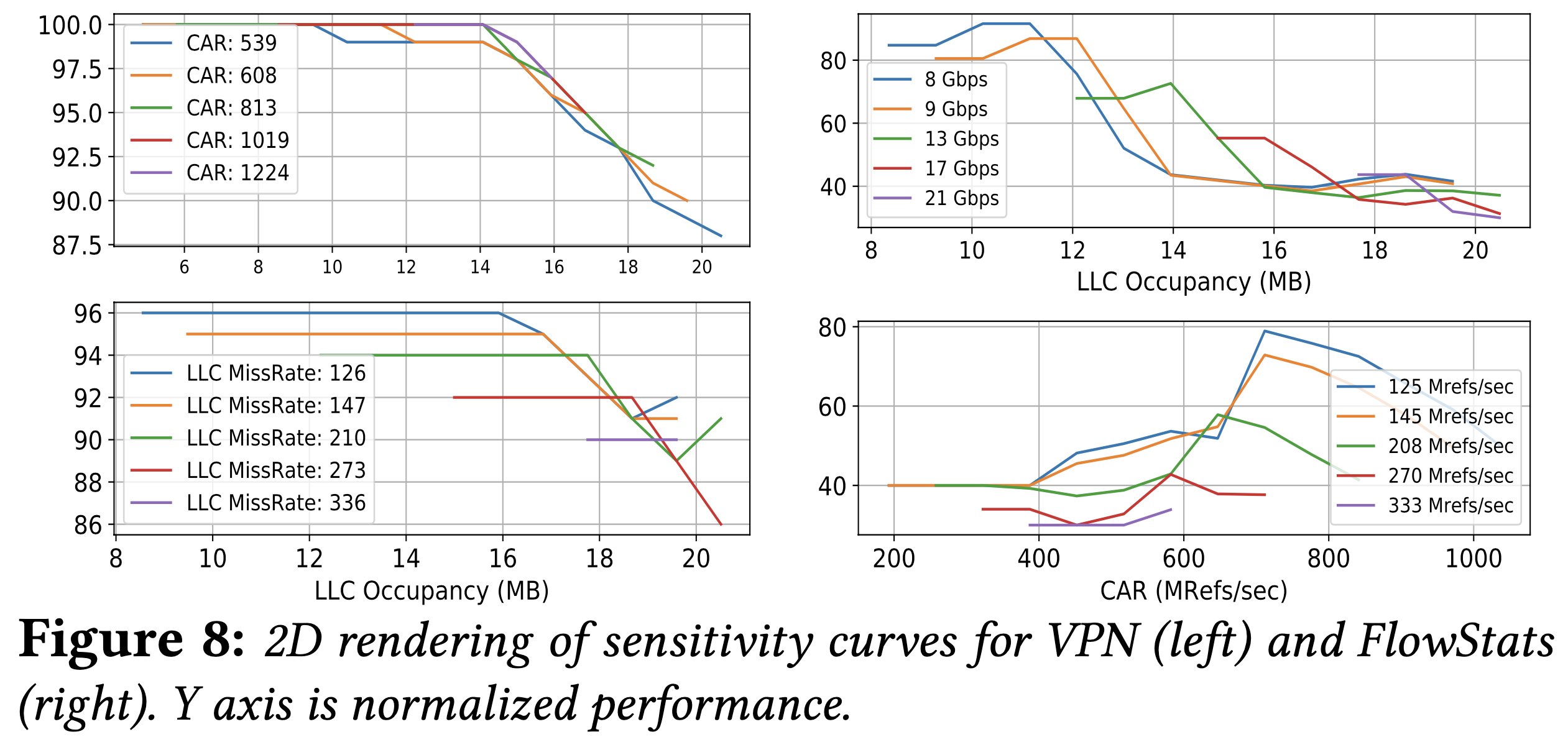
作者用 FlowStats 做了一個小實驗,其對記憶體競爭相當敏感,尤其是改變獨立流數目時。因此在其他參數保持不變的狀況下,從 400K 的流數每次減少 50K 去量測,可以發現「對於相同競爭的敏感度下降」、「吞吐量增加」,反之則相反。這是因為減少並行的流可以減少雜湊表的大小,因此減少了 LLC 中的競爭。在其他 NF 中也有類似的觀察。
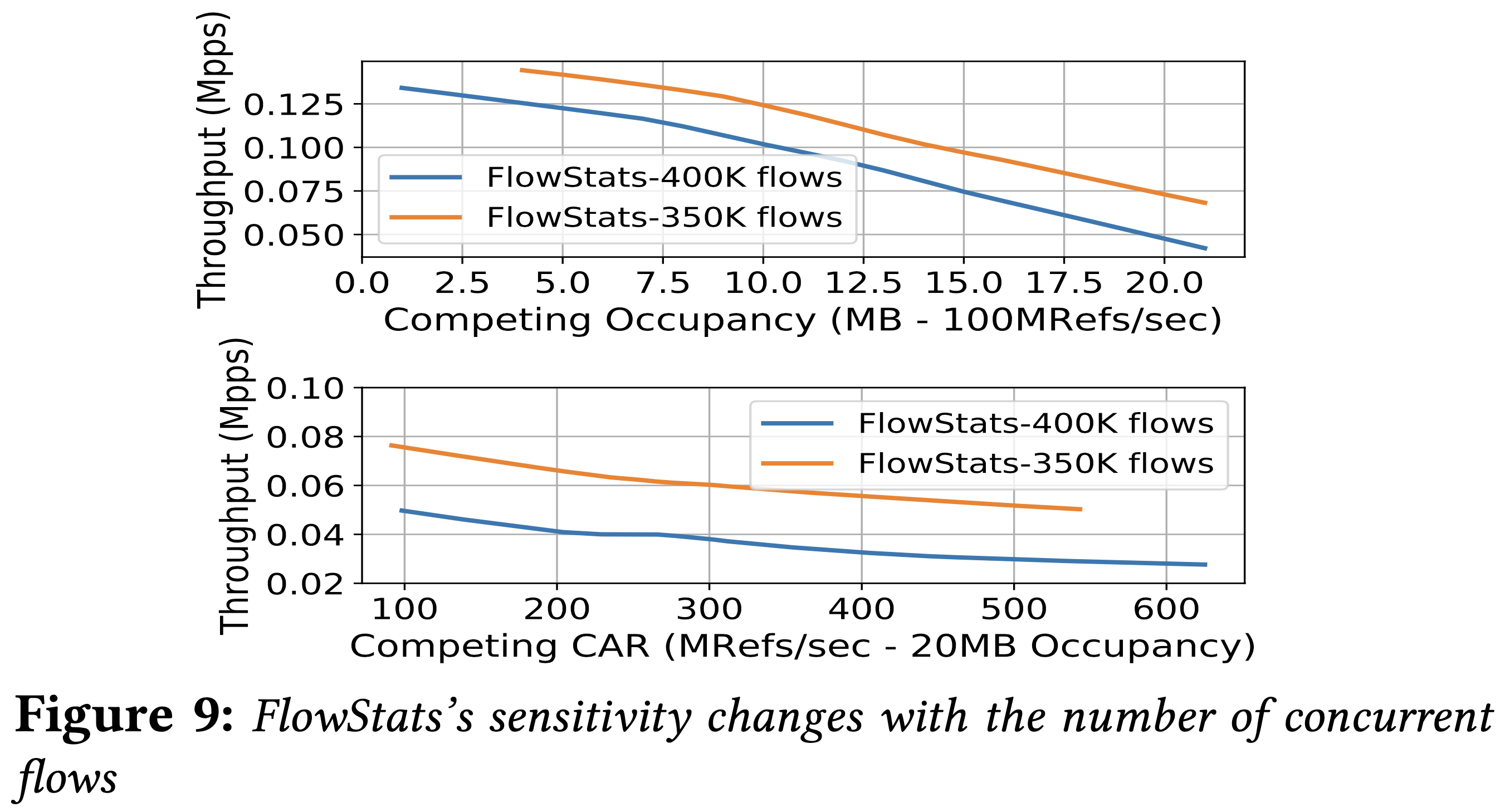
觀察 8:改變 $NF_i$ 的流量設定會導致其對共享記憶體的依賴關係及敏感度跟著改變。
回想到 5.2 節,作者使用了線性模型的集成學習來當作預測函數,不論是因為流量或是 NF 規則,有了這個洞察,便可以調整每個線性模型以符合 LLC 的使用狀況。
符合 CAR 的斜率
鑑於前面的實驗結果,可以知道目標 NF 的 LLC 佔用量會影響到效能。
作者預期當目標 LLC 佔用量下降時,cache eviction (miss rate) 也會跟著下降。
假設初始模型的 競爭者們的 CAR 與 目標吞吐量 的斜率為 $\alpha$,當目標的快取佔用量改變時其值會變成:
$$\alpha’ = \frac {OCC_{target}^{new}} {OCC_{target}^{old}} \alpha$$
符合佔用量的 X-shift
鑑於前面的實驗結果,可以知道整體 LLC 佔用量會影響到效能,而敏感度曲線的轉捩點是在當目標 NF 與競爭者的整體佔用量高於可用 LLC 時發生。
如果目標 NF 的 LLC 佔用量減少,可以預期這是在高處的轉捩點,因此我們可以沿著 x 軸(競爭的佔用量)移動敏感度函數來表達在不同佔有率下的關係。(參考圖 9)
$$\delta = OCC_{target}^{new} - OCC_{target}^{old}$$
符合單獨效能表現的 Y-shift
當目標 NF 的佔用量改變,其吞吐量可能會有所不同,將沿著 y 軸(效能表現)移動:
$$\beta = SoloPerf_{target}^{new} - SoloPerf_{target}^{old}$$
外推範圍
到目前為止,討論到的外推啟發是基於 $NF_i$ 的變動很小的前提下,因此 $NF_i$ 與 $NF_{i’}$ 在敏感度分析上有些重疊。
編按:什麼重疊?
如果設定檔、流量分析變動很大的話(如防火牆規則 1 vs 10k),就無法準確預估了,原因是敏感度分析重疊性太少。
7. 評估
這個章節中作者評估了其方法,並且呈現:
- SLOMO 是準確的,平均預測錯誤率為 5.4%,比起 Dobrescu 的方法(12.72%)降低了 58% ,比起 BubbleUp 方法(15.2%)降低了 64%。 (§ 7.1)
- SLOMO 的預測在各種運行條件下都很可靠 (§ 7.1)
- SLOMO 設計上的每個元件都對改善準確度有幫助 (§ 7.2)
- SLOMO 是高效率的,且可在 NFV 叢集中啟用智慧排程決策 (§ 7.3)
- SLOMO 是可擴展的,可為了 NF 的流量、設定檔改變而作出準確的敏感度外推函數 (§ 7.4)
實驗設定
- 所有實驗都會在兩種架構下面跑:Broadwell, Skylake
- 六種流量設定(例如:封包大小 64/1500B X 流量 40K/400K/4M,對 destination IP 是連續均勻分布)
- 讓 NF 處理盡可能大量的流量直到其核心滿載
- 使用基於 Click (v.2.1) 的 IP Router、無狀態防火牆(Snort),同時實驗 2 種設定檔大小(高/低)
準確度
SLOMO 的準確度如何?
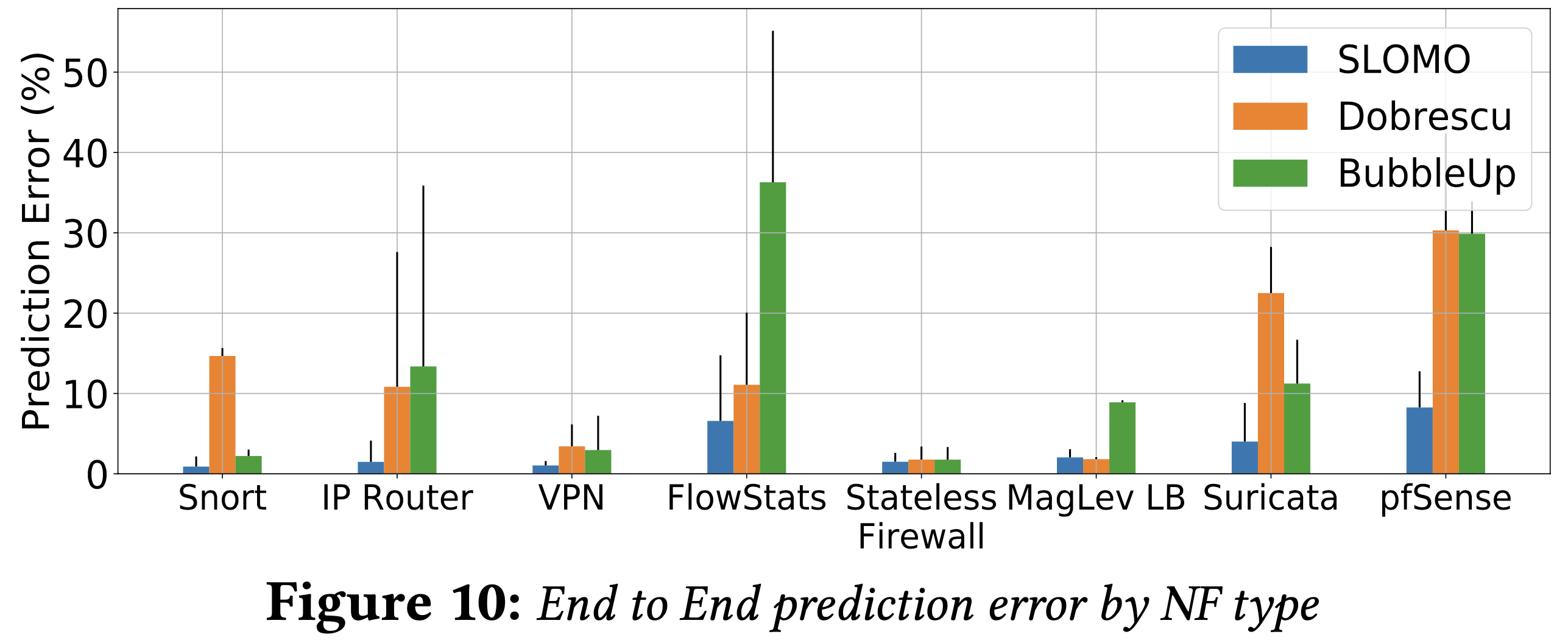
下圖可以看到 SLOMO 的平均預測錯誤率、錯誤變異數皆低於另外兩者。
然而,有些案例的數值卻非常接近,如 VPN, stateless firewall, Maglev,這是因為他們跟記憶體子系統沒有高度相依性。(§ 7.1 中 [預測有多可靠?] 會提到)
- VPN 是 CPU bound
- Stateless firewall 的 規則集 記憶體佔用量不高
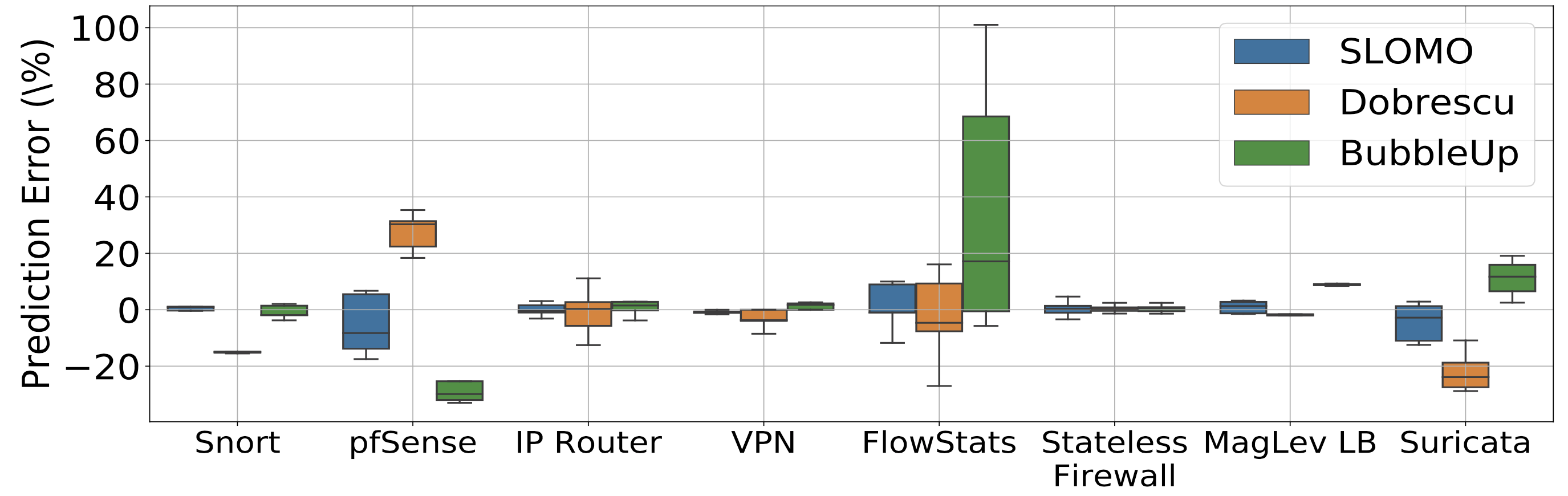
是否會高估/低估效能表現?
無明顯差異。
但若單純用基於 CAR 的模型,則會高估效能降低的數值。
預測有多可靠?
為了評估可靠度,作者觀察有號、無號的預測錯誤隨著關鍵資料的維度改變:
預測錯誤會隨著競爭的 NF 增加而上升,作者將其歸因於錯誤因子的累加。
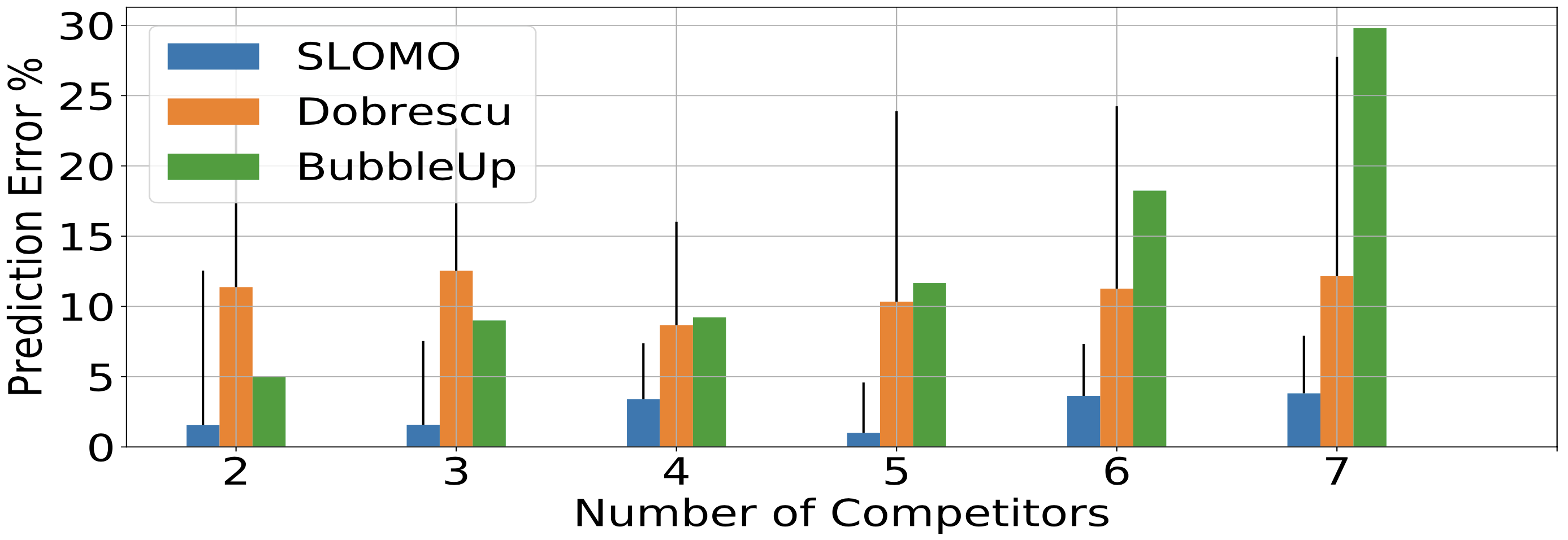
如果對記憶體敏感的 NF(如 IP Router,FlowStats)與多於兩個競爭者同時運行,SLOMO 有時會過度地預測效能下降(但依舊比 CAR-based 的模型好)。作者將其歸因於在模型訓練時沒有把較低的競爭因子考慮進來。
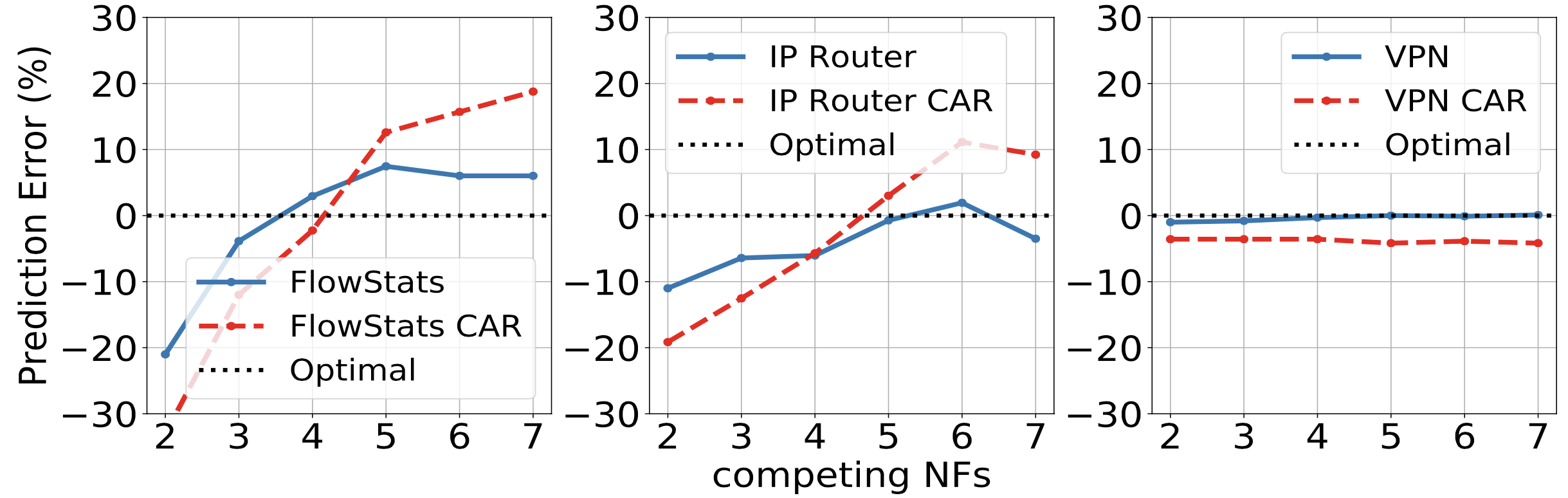
當獨立的流量數增加時,預測錯誤也會增加,這是因為會導致目標 NF 的輔助資料結構增加。這同時也解釋了 FlowStats 與 IP Router 的預測錯誤變異數偏小的原因。
編按:這問題應該能在 model 訓練時解決吧?🤔 可是圖中 4M 時反而下降?
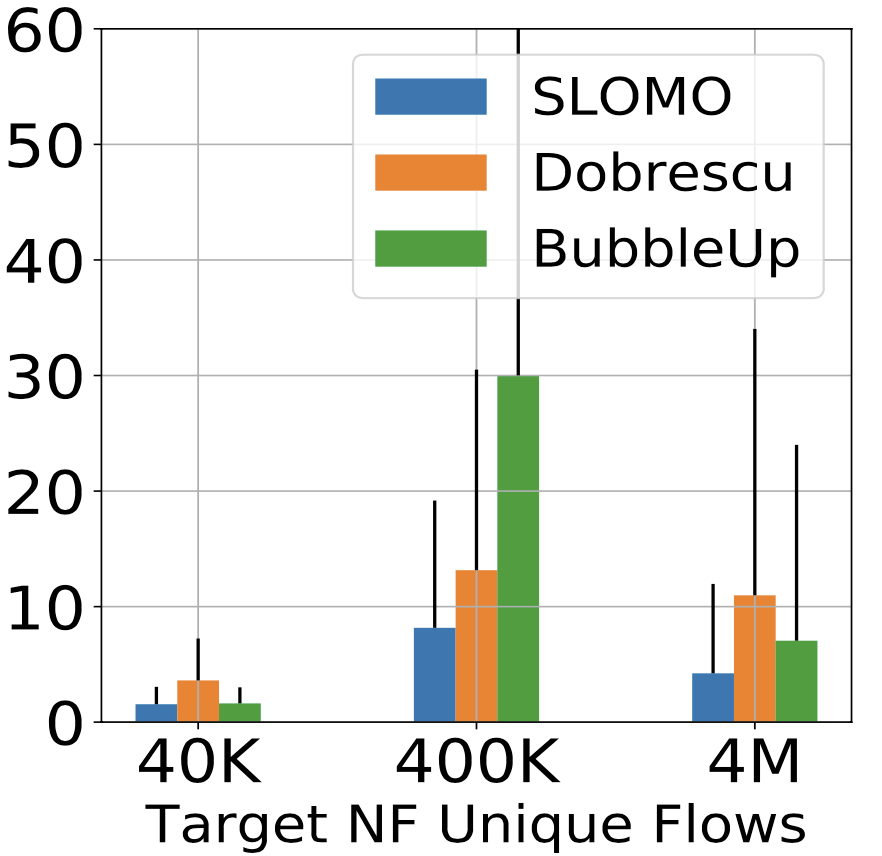
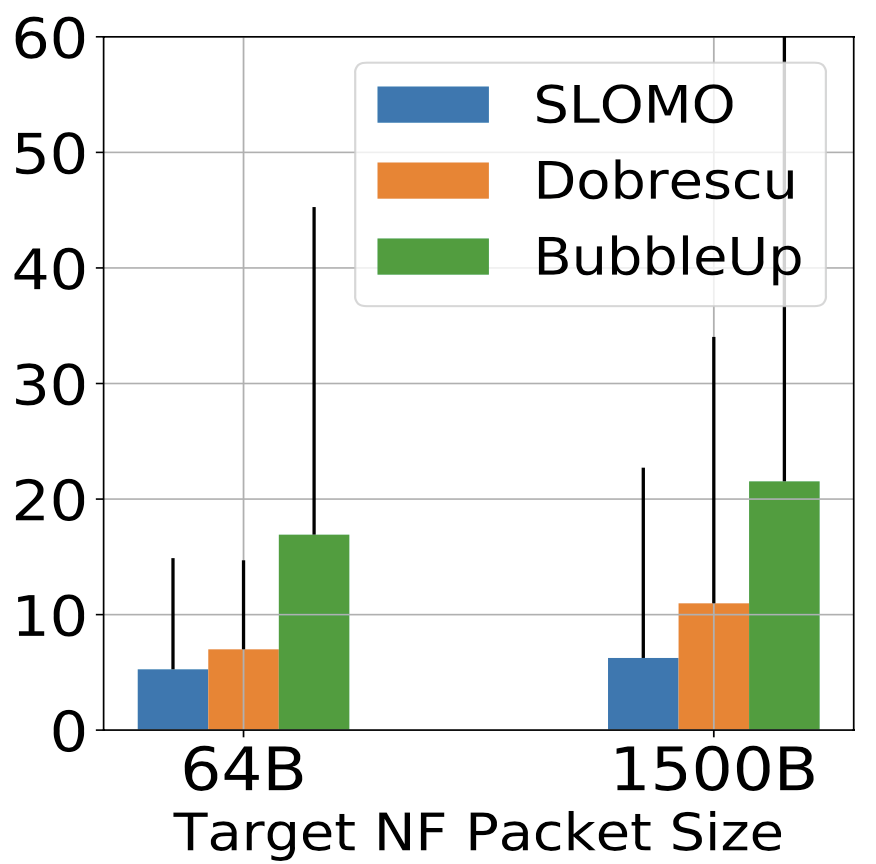
預測錯誤率不會隨著封包大小而改變
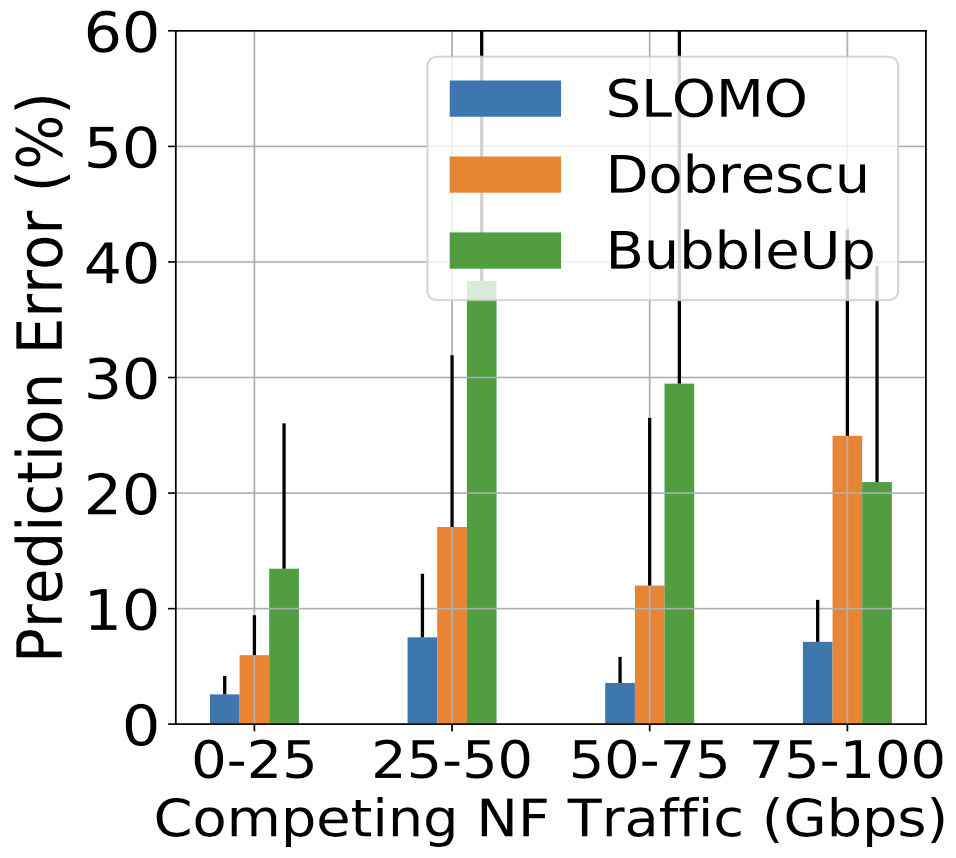
預測錯誤率不會隨著競爭流量(traffic rate)改變。且凸顯出 SLOMO 的設計可以適應不同類型的競爭者,這些競爭者對共享資源有不同的使用率。
編按:這結論是為什麼?
因子分析
這裡會檢驗 SLOMO 設計所選的元件。
競爭指標如何影響準確性?
作者分別用單一指標去訓練模型,並且量測錯誤率。
Top 1 跟 Top 3 分別是最好的 1 個及前 3 個指標所得的準確率,可以看到使用 3 個指標會比 1 個來得好。
同時又分成只跟 LLC 相關、只跟記憶體相關的參數,這兩種都比單一指標來得好,結合起來就是 SLOMO 會更好。
編按:FlowStats 的 LLC 跟 Mem 怎麼都比 SLOMO 來得低?
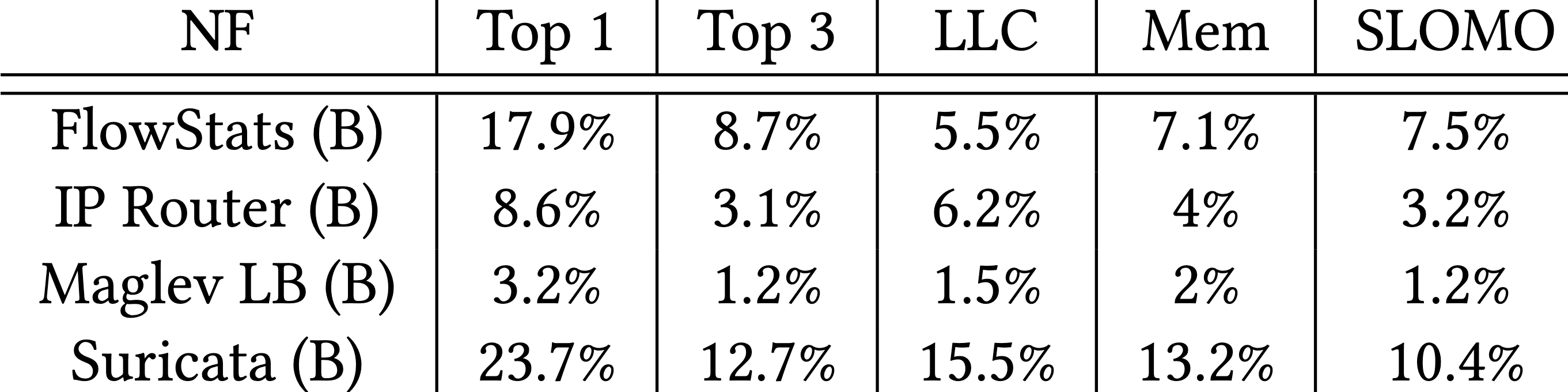
關鍵競爭指標在不同架構間有何不同?
作者在兩種架構(Broadwell, Skylake)下量測前三名影響因子,發現 Skylake 的伺服器比較常出現 Mem Write ,作者發現到是因為這兩種架構在記憶體設計上有很大的差異。
Skylake 除了有比較小的 LLC(11 MB vs. 20 MB),也沒有 write-back cache 機制,造成對記憶體的大量寫入。
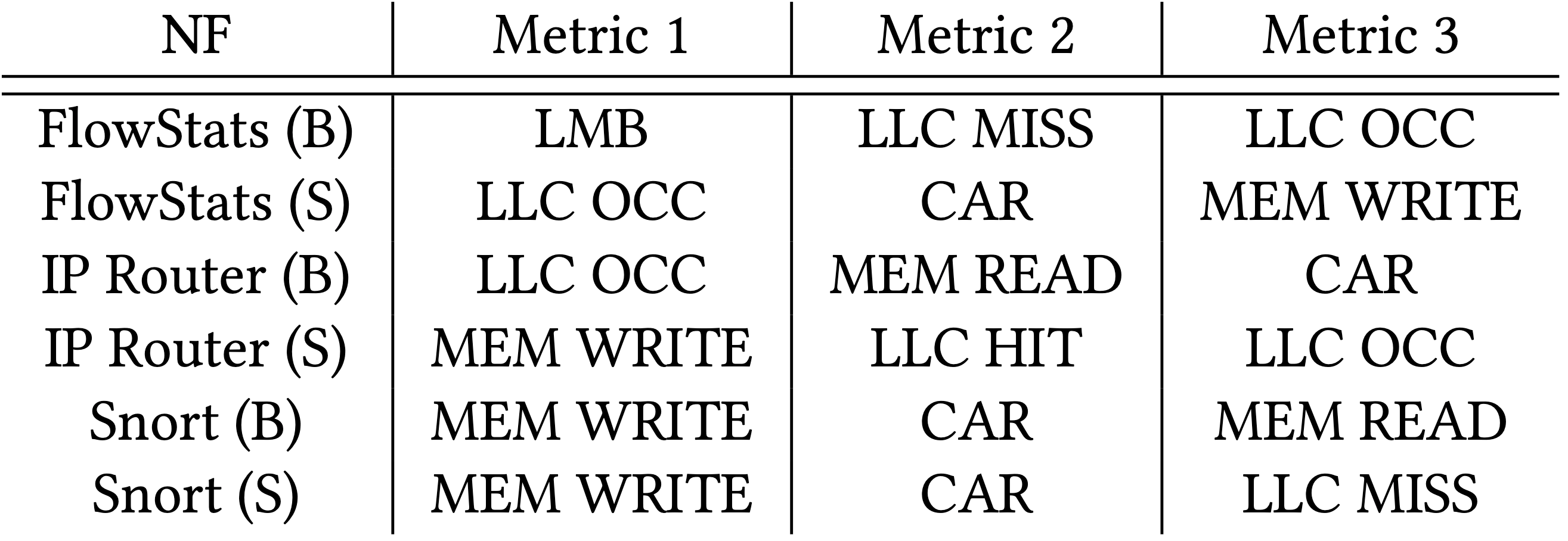
Gradient Boosting Regression 與其他技術的比較
Gradient Boosting Regression 是唯一平均預測錯誤率低於 10% 的。
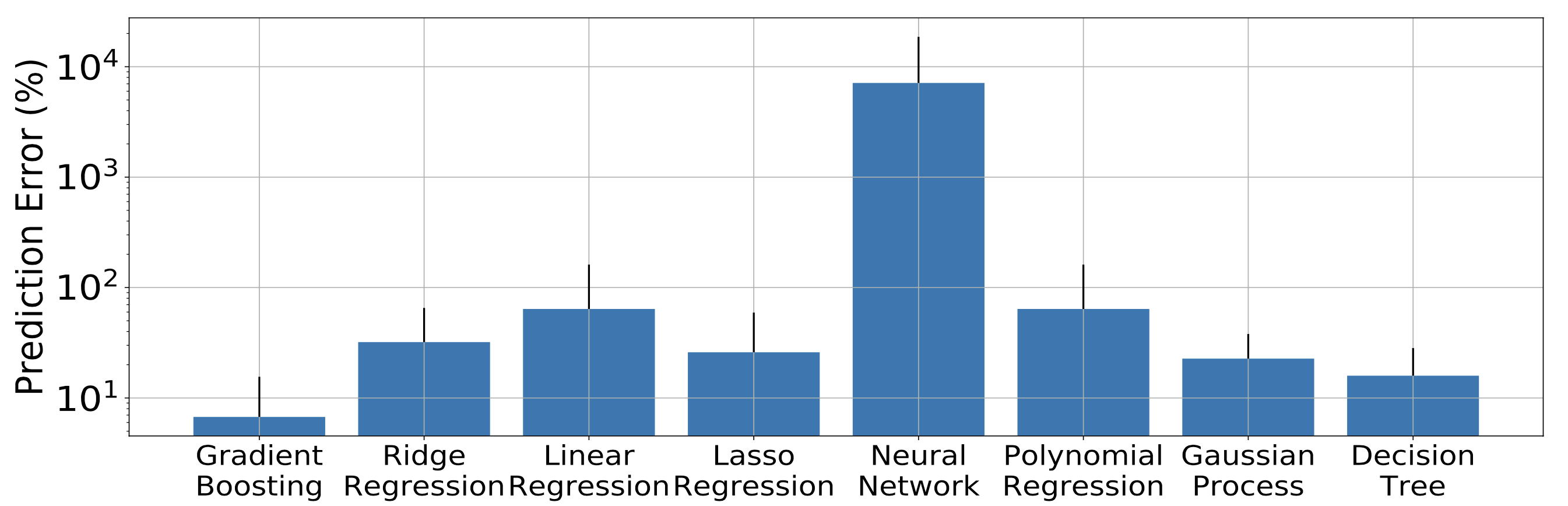
使用了合成後,預測錯誤會怎麼改變?
作者使用三種情境進行評估:
- 直接從伺服器上量測競爭(沒有任何的合成)(Observed)
- 當競爭向量與每個單獨執行競爭者的 PCM 指標進行合成(Composed Solo)
- 使用 SLOMO 方法進行合成(Composed)
使用情境
在叢集環境中可以使用 SLOMO 的高效率的線上排程,也可用 CAT 來達到較好的資源分割(resource partioning)。
使用 SLOMO 排程
營運商的目標是在滿足 SLA 的情況下,最大化資源利用率。而這個最佳化問題已經被證明是 NP-complete 的,因此作者選擇了 greedy incremental algorithm,如果沒有可用的伺服器,那只能加開一台。
實驗中對每個請求都窮舉了所有合成可能,以決定最佳排程:

8. 討論
如果 NF 沒有用封包加速技術呢?
作者發現,如果沒有使用封包加速技術,則 kernel-based 網路堆疊會是主要的瓶頸。
SLOMO 可以考量其他競爭源嗎?
在一個 CPU core 擺放一個 NF 的情況下,L2 快取會是瓶頸。
在 NUMA 架構下,QPI interconnect、NIC 會是瓶頸。
由於 PCM 沒有網卡相關的指標,作者把 PCM 沒搜集到的指標放到未來的研究當中。
9. 相關研究
NF 管理:
E2, CoMB 整合 NF 以避免 cross-switch 的流量,然而這種方式沒有解決因為競爭導致的效能下降問題。
有些作品旨在 scaling NF,為了解決擁塞、長尾延遲、丟包等問題。
NF 隔離: Netbricks、ResQ 旨在解決效能隔離問題。
透過符號執行來預測、驗證:
Pedrosa、Performance contract 等透過符號執行來了解 execution path,且用了快取模擬器來分析工作量。
這些需要有程式的原始碼才行,而 SLOMO 則可以在黑箱環境中執行。
名詞解釋
Intel Cache Allocation Technology (CAT)
CAT 為一種 performance isolation 的手段,用可以用來限制應用程式對 LLC(Last-level cache) 的使用。
有鑒於現在的 cache 越來越大,CPU 大多時候都是從 cache 抓取資料,當有個「noisy neighbor」如影片串流等等會消耗大量的快取資源,此時使用共享 LLC 的行程效能就會大幅下降。
此做法對雲端租戶的 SLO 比較有保障,因其大多使用共享主機資源。
參考:
Intel Performance Counter Monitor (PCM)
一個由 Intel 發起的 CPU、記憶體資源監控程式,目前已經改名為 Processor Counter Monitor 並且交由社群維護。
其統計資料包含:核心時脈、instructions per cycle、快取狀況、記憶體頻寬、PCIe 頻寬、能耗等等。
參考:
- Intel® Performance Counter Monitor - A Better Way to Measure CPU Utilization
- Processor Counter Monitor
Write-back cache
Cache 寫入機制通常有三種:
- write through:CPU 向 cache 寫入資料時,同時也寫一份到記憶體。
- write back:CPU 只將資料寫入 cache 並將其標記,只有在 cache eviction 時才會寫入到記憶體。
- post write:CPU 向 cache 寫入資料時,同時向緩衝器寫入,並在適合的時間再向記憶體寫入。
參考:
Model-free vs model-based
在強化學習當中,可以分為:
- model-free:agent 在執行動作前,不能對下一步的狀態與回報作出預測。
- e.g., Q-Learning, DQN, Monte Carlo
- model-based:agent 在執行動作前,不能對下一步的狀態與回報作出預測。
comments powered by Disqus