概要
在 middlebox 出錯時,能夠快速且正確的恢復是一大挑戰。
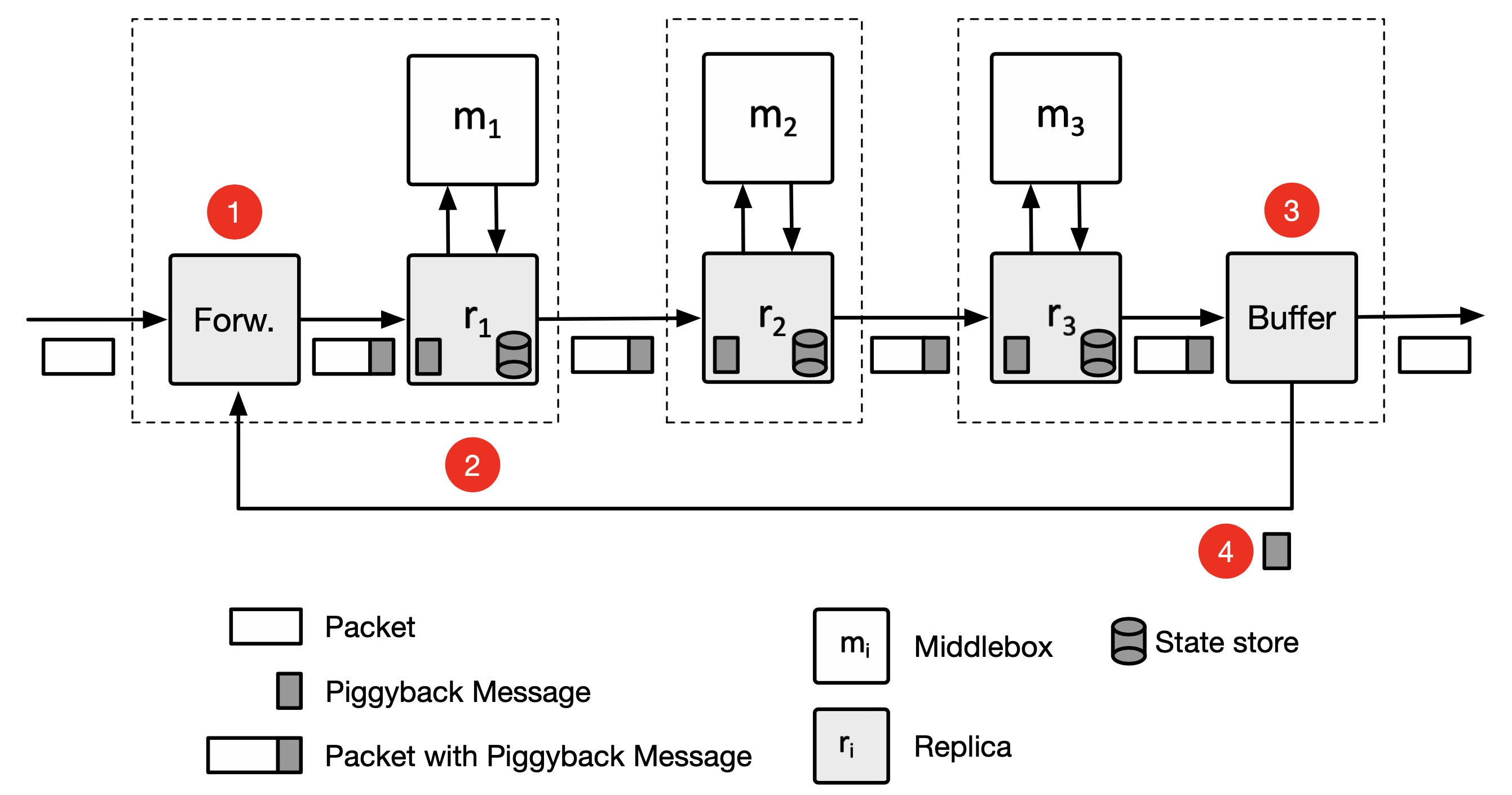
作者提出 FTC 框架,允許總長 f+1 個 middlebox 時能夠有 f 個 middlebox 失效。假設每個 NF 都運行在不同的伺服器上,每個伺服器上各自有 NF 與 replica(用來備份 state)。NF 會透過 API 來修改資料,這些 API 會使得 replcia 記錄相關修改 log 與套用到其 state 中,之後把修改 log 新增到封包尾端(piggyback)傳送到下個節點,而下個節點的 replica 會讀取 log 並套用到其內部的 state store 中,如此省去多一次傳送的開銷。
同時使用 transactional memory 技術來減輕 multi-thread 開發時的負擔,使得 middlebox 得以享有 concurrency 的加速效果又不失開發效率。
1. 介紹
由於現在許多 middlebox 都是有狀態的,單一 middlebox 發生錯誤後就算成功開啟新的節點,也難確保舊有的狀態能夠維持,像是防火牆紀錄、NAT 資料等等,這容易導致暴露在弱點威脅之下。
單獨地將每個 middlebox 做 replication 需要大量的 replica server,當然有部分的 middlebox 可以共享 replica server,但會對效能造成一定程度上的影響
編按:為何需要大量的 replica server,replicaion 真的這麼吃資源嗎? 作者應該單純只是想增加 replica 數量
有些人提出使用 snapshot 來保存狀態,但這使得吞吐量相當低且延遲高,無使用錯容錯系統的延遲約為 10 ~ 100 μs,做了之後為 400 μs ~ 9ms,且吞吐量會有 40% 的下降。
作者提出 Fault Tolerance Chain (FTC) 來解決這問題,FTC 會蒐集封包處理時的 state 更新資訊,透過 piggyback 方式新增到封包尾端,因此當封包流經整個 chain 時,這些狀態資訊就會順便同步到其他 middlebox 與 replica 上,因此允許每個架設 middlebox 的伺服器扮演著前個 middlebox 的 replica 角色。
編按:作者似乎沒考慮到多路徑(分岔)等狀況時該怎麼更新封包資訊,尤其當多個 middlebox 共享狀態時。
FTC 使用 packet transaction 機制來提供簡單實現 multi-thread 並且不太需要顧慮到狀態更新時的 race condition 問題,以有效使用多核心 CPU。透過 transactional model 可以使得狀態存取能得以序列化的並行執行,前人(Rollback-Recovery for Mid- dleboxes)曾使用過靜態分析方式來達到此功能,但若是分析的不完善可能會使得效能變差。
在實作上,使用 Click 與 ONOS SDN controller,與前人相比其結果成功降低了延遲且改善了吞吐量。
2. 背景
Middlebox 狀態可以是 partitionable 或 shared:
- Partitionable
- 表示單一 traffic flow 的狀態(例如:有狀態防火牆的 MTU 大小、超時)
- 只能被單一個 middlebox thread 存取
- Shared
- 多個 flow 共享,因此有多個 middlebox thread 可以存取(例如 IDS 中的 port-counts)
Middlebox 可能因為硬體或軟體緣故導致不能正常運作,歸類出以下幾種:
- bit corruptions
- 纜線問題
- 軟體 bug
- 伺服器維運問題
- 電力問題
作者將其稱為 fail-stop,也就是 fail 是可偵測的,且 failed component 沒有自動恢復。
挑戰
當出錯時,必須要能夠將流量導向到備援裝置上,並且備援裝置上的狀態要是跟原本裝置失效時是一樣的。在 state replication 上有兩個問題會影響到 middlebox 的效能表現:
多執行緒
- 多數的 middlebox 是多執行緒的,其會交互存取共享的狀態
- 困難在於捕獲交互存取時的操作紀錄
編按:為何會難?
- 其中一種方式是記錄所有狀態的讀寫,並在復原時 replay 紀錄檔,但開銷很高
容許 f 個錯誤
- 封包只在 f+1 個 replica 「回應 ack 狀態更新」時才能夠被釋出,也就是封包將會在被處理完後放在 buffer 中等待一陣子
- 此會導致延遲上升、吞吐量下降(因為 replica 一致性同步問題)
- 關鍵因素為:
- replica 擺放位置
- 狀態更新、傳送機制
當前方法的限制
Snapshot
- 以每個封包、batch 為單位進行快照,會有 400 μs ~ 8 ms 的延遲
- 週期性的快照,會導致延遲衝高到 6 ms
- 快照會使得吞吐量下降 40%
- Middlebox 操作會陷入一致性問題
編按:為何會有一致性問題?快照時 middlebox 不能做事倒是真的
分離狀態、將狀態存放到容錯後端 data store
- 存取狀態會有 RTT 延遲
- 只有在收到 data store 的 ack 時,middlebox 才會釋出封包
- 會降低 60% 的吞吐量
3. 系統設計概要
需求
FTC 需要下列四種需求:
Correct recovery
- FTC 會確保復原的 middle 行為狀態跟停機前一樣
- 為了能夠容忍 f 台停機,封包只會在 f+1 台伺服器都收到(ack)必要的重建資訊後才能釋出
Low overhead & fast failure recover
- 延遲必須要小於 10 ~ 100 μs
- 容錯系統的變數存取速率需達到每秒 10 ~ 100 萬次
- 恢復時間必須夠短,以避免應用程式出問題(如高可用系統超時約幾秒鐘而已)
Resource efficiency
- 為了有效隔離可能的失效問題,replica 必須部署在不同的實體伺服器上
編按:若單純防止軟體錯誤,應該不用部署在不同的伺服器上吧?
設計選擇
transactional packet processing: 為了簡化並行處理時的狀態存取問題,作者使用序列化的 transaction 方式來實現,以確保一致性的狀態能夠被攔截、replicate。由於 hybrid transactional memory 的發展,可以善用硬體加速來提升吞吐量。
在其他系統中使用 鎖 方式實現,這種方式比較複雜且會有較高的開銷。
編按:應該是 lock 沒設計好才會有較高開銷吧,不然 transactional memory 開銷其實會比 lock 高。
In-chain replication: 基於共識的狀態複寫,需要 $2f +1$ 個複本以在 $f$ 個節點失效時恢復。在高可用叢集中需要 f+1 個複本。因此對於 $n$ 個 middlebox 的 chain,總共需要 $n * (2f+1)$ 與 $n * (f+1)$ 個複本。
編按:為何需要 $2f+1$ ?
作者認為封包本身就會流經各個 middlebox,這些 middlebox 所在的伺服器理當也可以當作 replica,因此 FTC 容忍了 f 個節點失效,同時又不需要獨立的 replica 伺服器。
State piggybackign: FTC 中封包會攜帶著其曾經處理過的狀態更新紀錄。
No checkpointing and no replay: FTC 使用較細粒度的封包 transaction 來做複寫,而不是使用 snapshot 方式、也不是使用 replay 封包處理操作。並且會在所有 replica 都有複本後停止該紀錄的 piggyback。
Centralized orchestration: FTC 中有個核心的 orchestrator 來管理網路、chain,包含部署、監控偵錯、錯誤還原初始化。其使用容錯的 SDN controller 打造,並在部署完畢之後不干預正常 chain ,以避免瓶頸的發生。
編按:監控、流量導向總要吧,這算干預嗎?
4. FTC for A Single Middlebox
為了使狀態的傳輸是可靠的,作者使用了類似 TCP 的 sequence number 的方式來避免傳送順序上的錯誤。
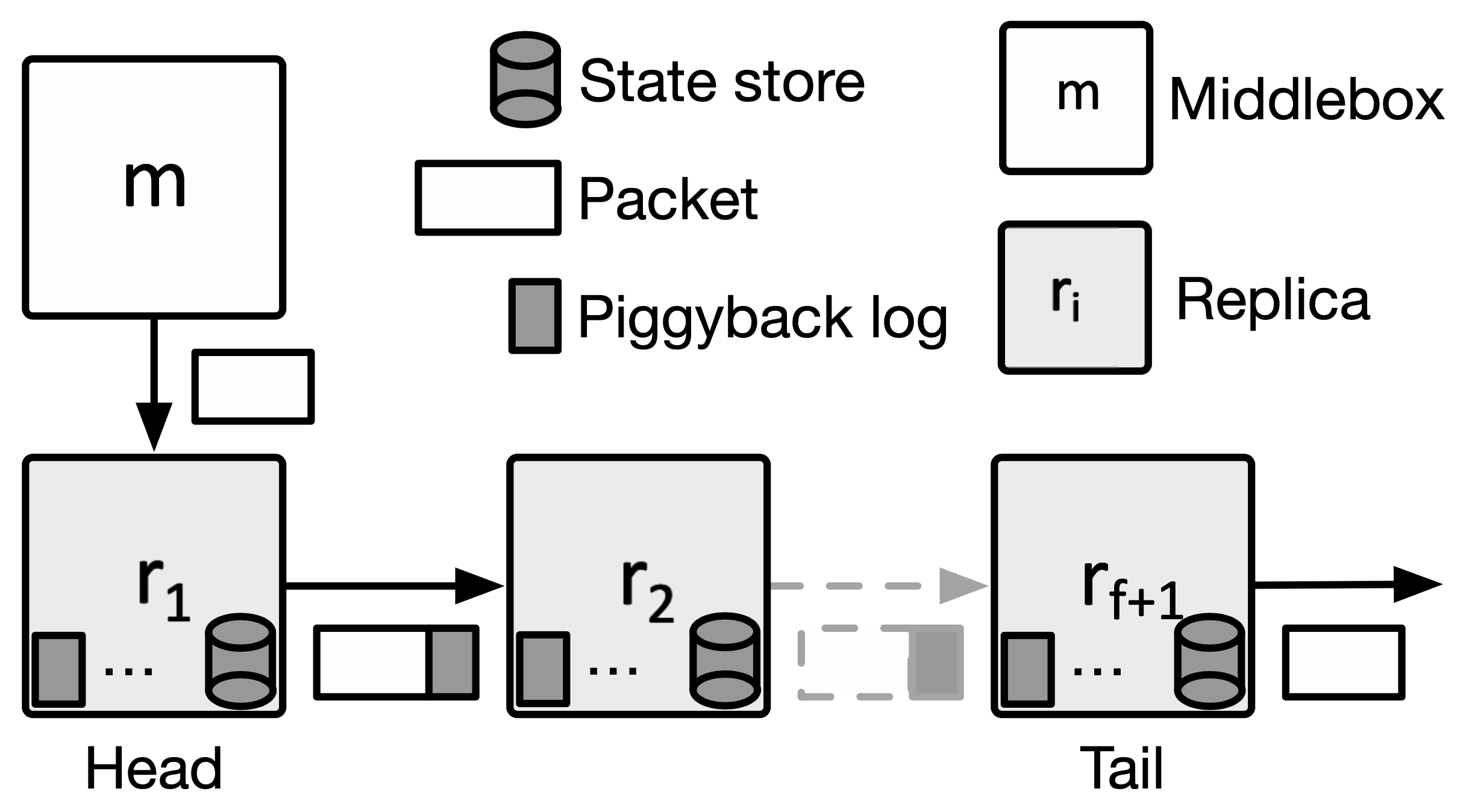
對於 middlebox $m$ 來說(不一定是 chain 中的第一台 middlebox),第一個 replica 為 $r_1$(head),最後一個為 $r_{f+1}$(tail),這些屬於 $m$ 的 replica 稱為 m 的 replication group,每個 replica 都在不同的伺服器上,且都會將 piggyback log 複製一份,並且將狀態更新到其 state store 中,因此能容忍 f 個節點失效。
head 節點跟 middlebox $m$ 位於同台伺服器上(見概要的圖),提供狀態管理 API 給 middlebox 使用,而 middlebox 的狀態從其 logic 中分離到 head 的 state store 中儲存。因此若要使用 FTC 必須在程式碼中使用相關的 API 來進行狀態的讀寫。
Normal operation of protocol:在 middlebox 處理完封包後,head 會建立 piggyback log 並將其新增到封包尾端,其包含了:
- Sequence number(monotonically increasing,單調遞增)
- A list of state update (during packet processing)
如果狀態沒有更新,head 會新增 no-op 的 piggybacklog。每個 replica 都會持續接受含有 piggyback log 的封包,一但發生封包遺失,便會發送重傳通知給前一個節點。在 replica 收到所有該收的 piggyback log 後,與套用到其內部的 state store 後,才會將封包轉發出去。
最後,tail 會將 piggyback 從封包上移除,並定時向 head 宣傳其目前最大的 sequence num,接著這些 seq 會傳播到每個 replica,他們就可以將舊的 log 清除,只保留最新的。
值得注意的是,雖然 replication group 不一定是從 chain 的開頭開始,不過這些 state 不會在 chain 尾端停止傳播,而是會另外通知 chain 中第一台 replica 去把這些狀態資訊加到後繼的封包上。
Failure recovery:FTC 依靠具有容錯功能的 orchestrator 來偵測節點失效。在偵測到失效後,replication group 會進行下面三步驟來修復:
- 新增新的 replica
- 從目前活著的 replica 恢復遺失的狀態
- 導流到新的 replica(會確認所有失效的節點都成功復原)
log propagation invariant: head 節點在還原時會跟其後一個節點要還原資料,其他節點(除了 head)在還原時會跟其前一個節點要資料。
編按:猜測這只是程式設計上方便的考量
在還原期間,身為還原的 source 節點會丟棄所有尚未被套用到 state store 的封包,且不再接受任何封包傳送到此節點。
假如還原失敗,那就在還原一次。
編按:是否該有個機制來屏排除無法正確還原的 source?
Concurrent Packet Processing
為了達到高效能,FTC 中 middlebox 跟 head 都可以多執行緒的方式執行,只有剩餘的 replica (除了 head)會以單一執行緒方式。(剩餘 replica 多執行緒 執行會在後面章節實施)
在並行的情況下,多個封包會同時被處理,因此多個執行緒可能會同時存取相同的狀態,因此作者採用 transactional memory 技術來避免 race condition 問題,如此就不需要追蹤每個變數的相依狀態,僅需要知道 transaction 的順序即可,當然多個執行緒存取不同的狀態時仍可以平行處理。
作者使用 Software Transactional Memory(STM) 技術來實現,當封包到達時 runtime 即會開啟新的 transaction 以應付所需要的狀態讀寫,並使用嚴格的 two phase locking 來提供序列化。
使用 wound-wait scheme 來避免到可能發生的 deadlock,並且使用 state space partitioning 來簡化 鎖 在管理上的困擾,每個 state 都會經過 hash 來保持一致性,且 partition 數量會多過 CPU 核心數以降低競爭。
編按:應該是避免了 starvation 才對吧?且為何會有鎖,作者是指 transaction 過程嗎? 為何競爭與 partition 數量、CPU 核心數量有關係?
在 transaction 結束前,head 會在狀態更新時自動遞增 seq num,接著打包 piggyback log 到封包中送到下個節點。
Concurrent State Replication
為了解決 replication 的瓶頸,作者用了 data dependency vectors 方法來支援 state replication 的並行處理,比起追蹤執行緒間的相依關係並且回放那些操作,這個方法比較有彈性:
- 支援垂直擴展
- 正在執行中的 middlebox 可以替換不同的 CPU
- 允許使用不同執行緒數量
- 前人的作品要求 replica 的執行緒數量需要與 middlebox 一樣以利一對一對應複寫
Data dependency vectors 將狀態細分成多個 partition,使得複寫時的並行效益能夠增加。在 read-only 的 transaction 中不會變更 vector,其餘的 transaction 都會增加 seq num。
如果該 transaction 沒有存取到某個 state partition 的話,則會在 piggyback log 中標記為 don't-care。若有存取到, head 會從 dependency vector 取出成 seq num 當作 piggyback log,並在套用時才對其做遞增。
Replica 會維護 dependency vector MAX,為其當前所收到最大的 seq num 們,因此在收到 piggyback log 時會與當前的 MAX 做比較,只有大於、等於 MAX 的 log 才會套用。如果發現有封包遺失(可能是 seq num 有跳躍情況),則會向前一個節點發出重送 piggyback log 請求。
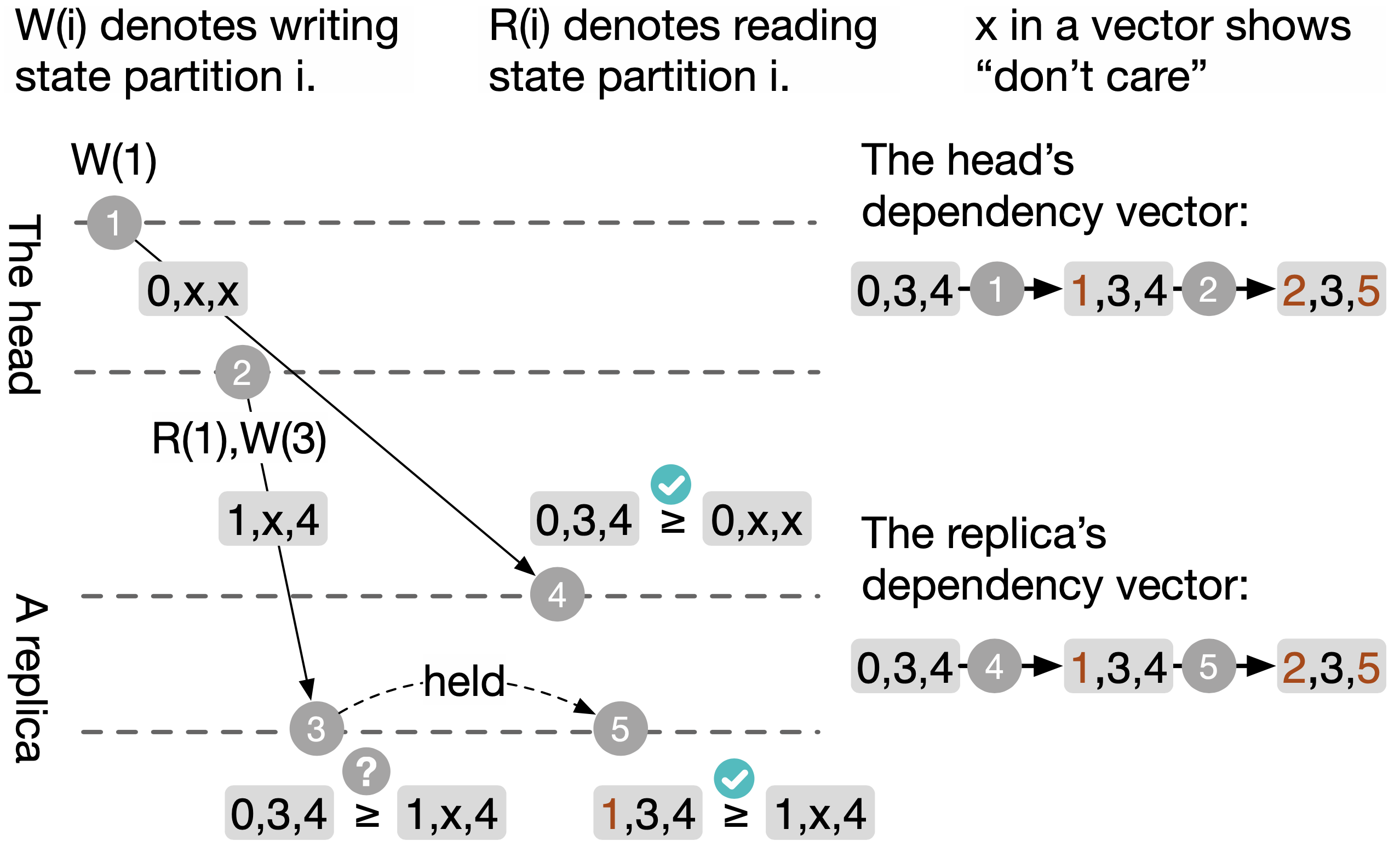
上圖的執行流程:
- head 寫入 state partition 1,並且遞增 seq num
- head 在另一個 transaction 中讀取 partition 1、寫入 partition 3
- replica 發現順序錯誤,擱置 piggyback log
- replica 發現順序正確,套用變更(seq num +1)
- replica 套用前一個 piggyback log
5. FTC for A Chain
FTC 有兩個元件分別在 chain 的入口與出口處:forwarde 、buffer ,兩個都是多執行緒,且與前後 middlebox 位於同樣的伺服器上。
編按:為何要位於同樣的伺服器上,省資源?
forwarder
- 將從 buffer 來的狀態更新加到封包上
編按:上一個處理封包的資訊,交由下一個封包傳
buffer
- 將封包留在此,直到所有 replica 都有複寫後才能釋出
- 會將 chain 尾端的狀態更新(使用
piggyback message)傳送到 forwarder
Normal Operation of Protocol
piggyback message 包括:
- piggyback log
- a list of
commit vectors(tail 中與之相對應 middlebox 的 dependency vector MAX)
Tail(replication group 最尾端)會在封包上新增 commit vector 以宣告最後一個狀態更新執行完畢,並且將相關的 piggyback log 從封包上移除,之後 buffer 在讀到此 vector 後便可以釋出拘留的封包,其後的 replica 看到即可將 piggyback log 刪除。
編按:如果 commit vector 掉包呢?
當 forward 有段時間沒收到封包,就不能將 piggyback log 往下送,此時可以透過 forward 的 timeout 來觸發 propagating packet 來將收到的 piggyback message 傳出去,其後的 replica 會照常處理,只是不會將其送到 middlebox 做處理。
編按:這樣延遲不就變高了,能否有主動一點的機制?
有些 middlebox 會過濾封包,這時候其 head 也會產生 propagating packet 來傳達必要的資訊。
假設原先預期每個 chain 都能容錯 f 個失效,也就是有 f+1 個 replica,但實際上 chain 卻沒又這麼長,這時候可以只增加 replica 而不增加 middlebox 來達成。
編按:感覺這部分有點偷懶
Failure Recovery
在復原的過程中,orchestrator 會告知新節點他在 chain 中的位置與相關資訊,藉由向鄰近 replica (看是 head 或其他 replication group)抓取 state store 資訊與 dependency vector MAX。
一旦復原完成,orchestrator 確認完後即將相關流量導到這個節點上;若有多個節點同時失效,會等到這些節點都成功復原。
6. Implementation
FTC 使用 ONOS controller 與 Click 來實作,在 orchestrator 用了 JAVA 1k LOC,FTC 與 middlebox 用了 C++ 6K LOC。
Replica 中分為:
- control plane
- 負責與 orchestrator、其他 replica 的 control module 進行通訊
- 在還原的過程中會對每個 replication group 各開一個執行緒來抓取資料(透過 TCP)
- data plane
- 處理 piggyback message
- 傳送、接收封包給 middlebox
- 建立 piggyback message
- 轉送封包到下個節點(replica or buffer)
關於 piggyback log 攜帶的部分,是在 IP option 中加入一些資訊來告知 FTC runtime,並在封包尾端加上 piggyback log。當 replica 傳送封包給 middlebox 處理前,會將額外加上的資訊都移除,並且在處理完後重新把資訊加上去。
編按:IP option 滿了怎辦?是否會有資安隱憂(駭客自己加)?我認為傳送自定義的 data structure 會比較好,不要透過修改封包方式
7. Evaluation
作者將 FTC 與 沒做容錯的基準系統、FTMB 相比。
FTMB 使用獨立的主機(Master,M)來處理容錯,其他主機運行 middlebox,封包會流經 input logger(IL)→ M → output logger(OL),其中 M 會使用 packet access logs (PAL) 來追蹤 share state 的存取紀錄並將其傳送給 OL。
作者使用兩種環境進行測試:
- local cluster
- SAVI distributed Cloud
- 位於加拿大的資料中心
- 每台虛擬機有 4 核心,8G RAM
- Ubuntu 14.04, Kernel 4.4
- 使用 ONOS docker 來控制 OVS switch 網路(連接多台虛擬機)
- 使用
[multiple interleaved trials methodology](https://dl.acm.org/doi/10.1145/3030207.3030229)來減少共享 infra 所帶來的變異性
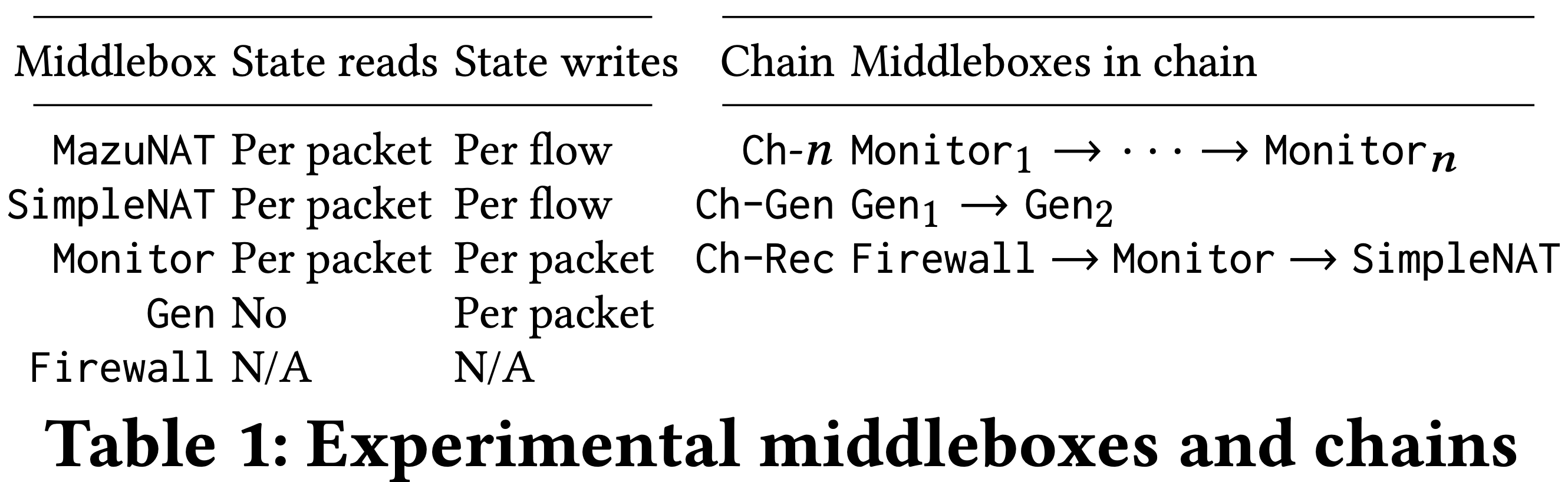
上圖是作者使用到的 middlebox 與 chain。
- Monitor 為 read/write heavy
- Gen 為 write-heavy,使用 state size 測試其對 middlebox 表現的影響
- Firewall 為無狀態
之後會提到 Sharing level 參數,其意思是有幾個執行緒共同存取某個相同的狀態變數。例如 Sharing level 1 代表沒有其他執行緒在搶,Sharing level 8 代表 8 個執行緒會互相競爭同個狀態變數。
Microbenchmark
效能分析(Performance breakdown):

上圖為 MazuNAT 運作時的 CPU cycle (使用 8 執行緒在長度為 2 的 chain 上,表中為單一執行緒之結果)
- transaction(Packet processing, Locking)
- 為延遲的主要來源
- Copy piggybacked state
- 影響非常輕微是因為狀態更新的資料量滿小的。
- Forwarder, Buffer
- 跟 chain 的長度無關,造成的影響也不大
狀態大小對效能的影響:
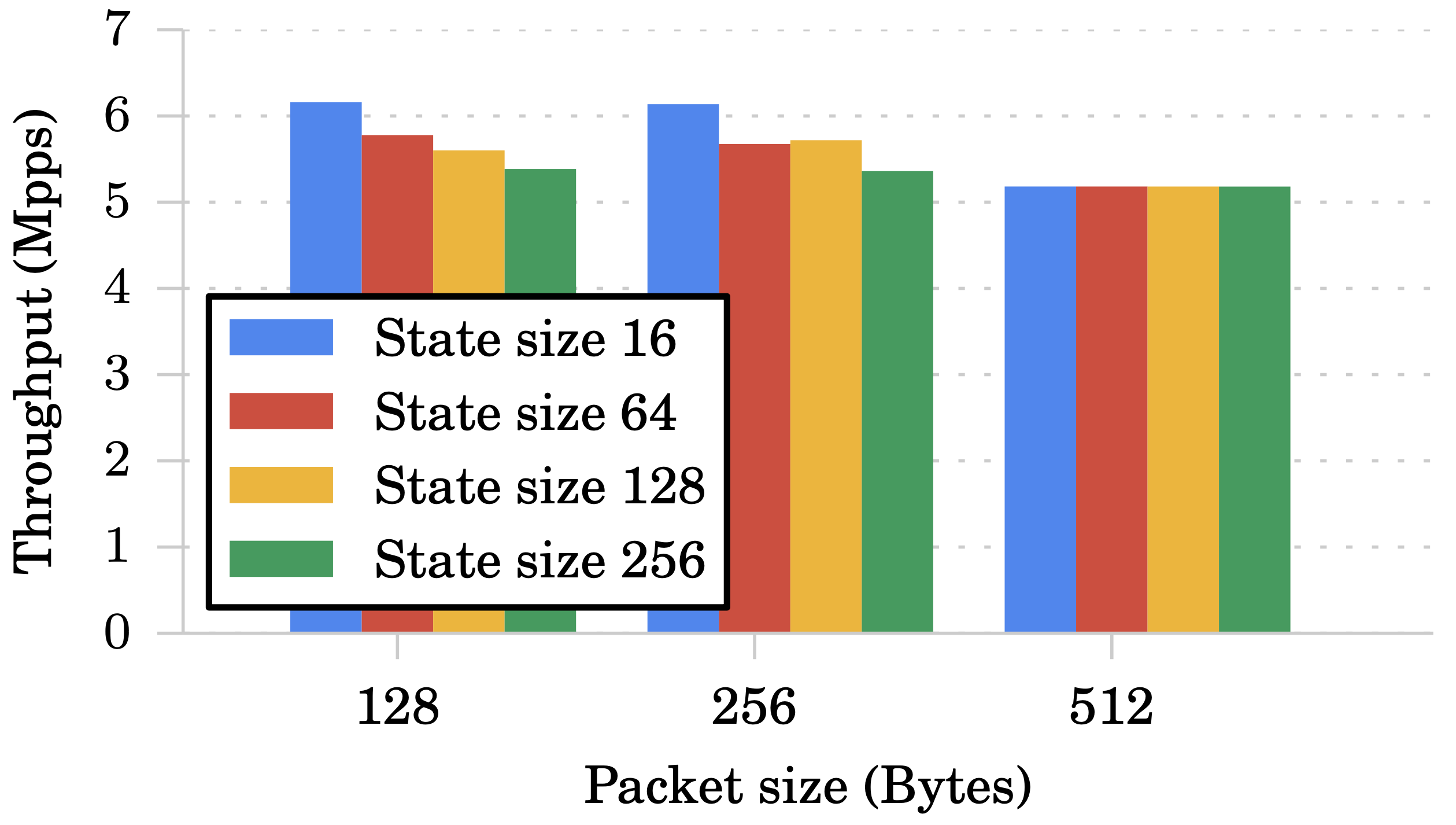
使用 Ch-Gen 這個 chain 進行測試,在 2 Mpps 封包大小 512 Byte 環境下,不管狀態從 32 ~ 256 Byte 都對延遲沒什麼影響。
接著使用不同的封包大小、狀態大小來測試吞吐量,從下圖可以發現影響只有在「state size > packet size」時才會發生。
Fault-Tolerant Middleboxes
吞吐量
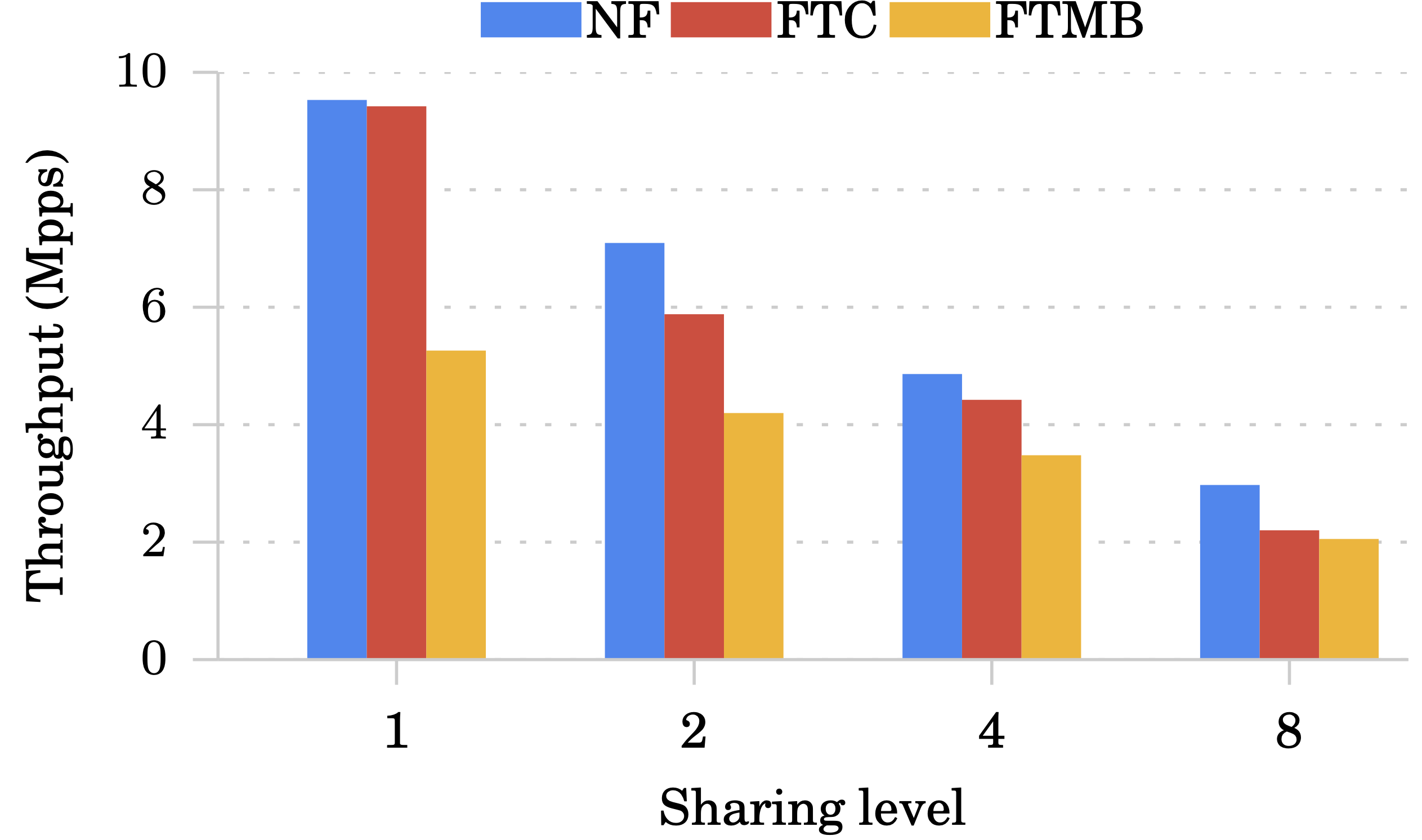
Monitor:
從下圖可以看到 Monitor 在 Sharing level 越多的情況下吞吐量表現越差,這是因為 Monitor 會需要寫入狀態變數,因此會有大量 contention 的發生,造成 transaction 一直被 abort。
MazuNAT:
再來看到下圖 MazuNAT 反倒是隨著 Sharing level 上升吞吐量越高,這是因為 NAT 在寫入一次狀態後其他時間都是讀取,FTC 不需要 replicate read 操作。
至於跟 NF 相比仍比較差,這是因為在 FTC 實作中會對封包預留一段空間以供狀態寫入需求。
延遲
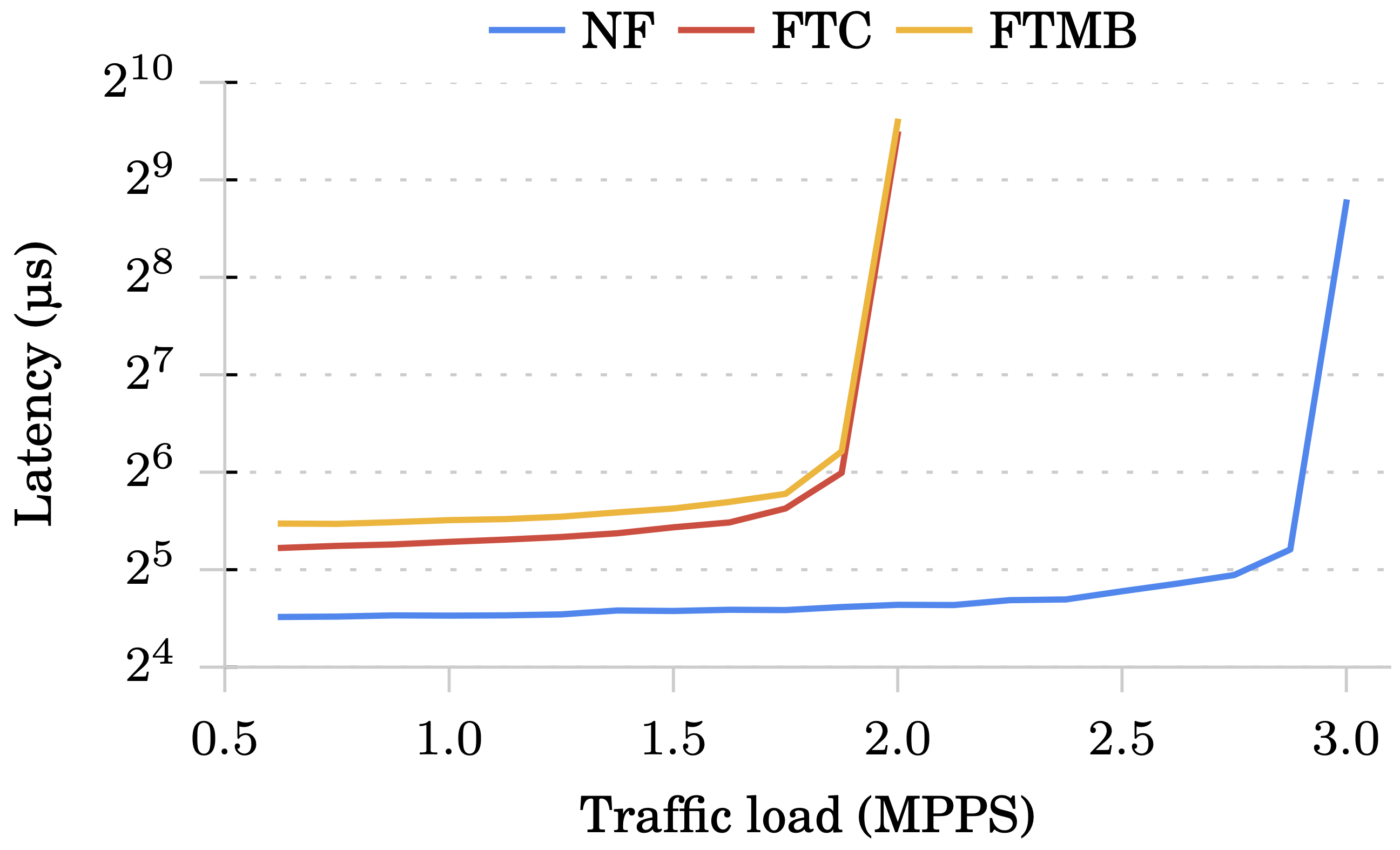
Monitor:
FTC 跟 FTMB 有點差距是因為 FTMB 多了單向的網路延遲去轉送封包、狀態給 replica。
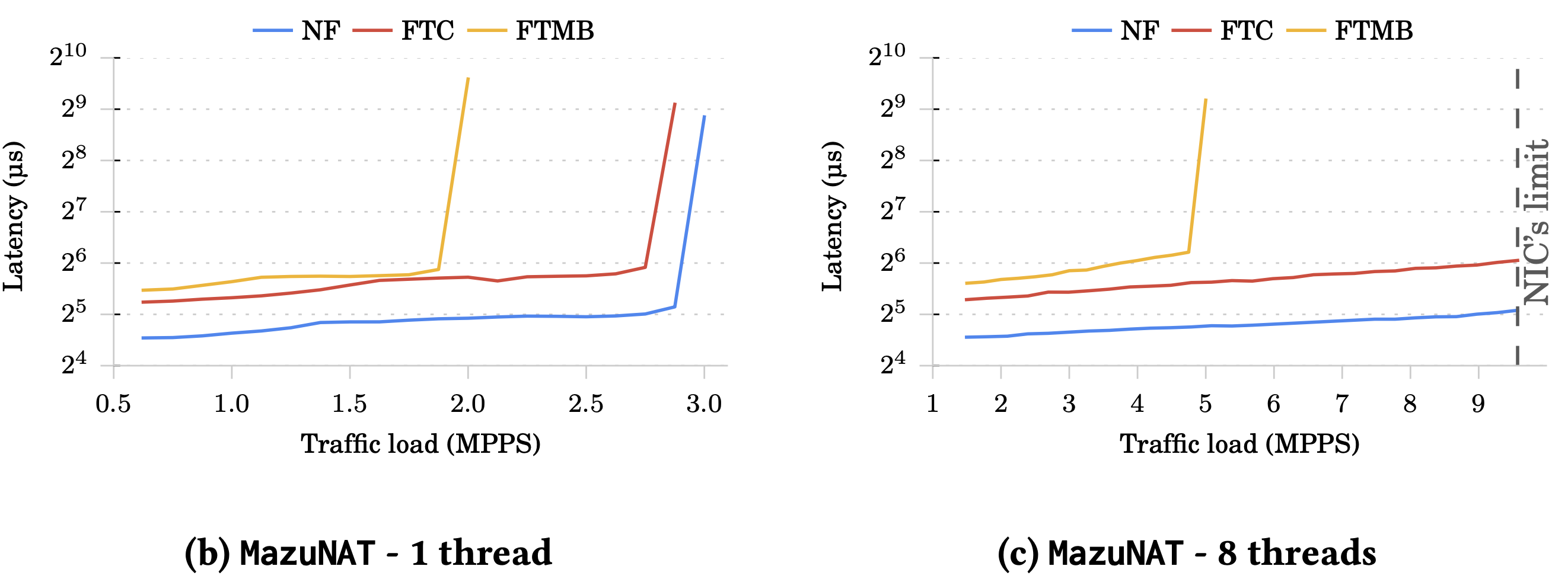
MazuNAT:
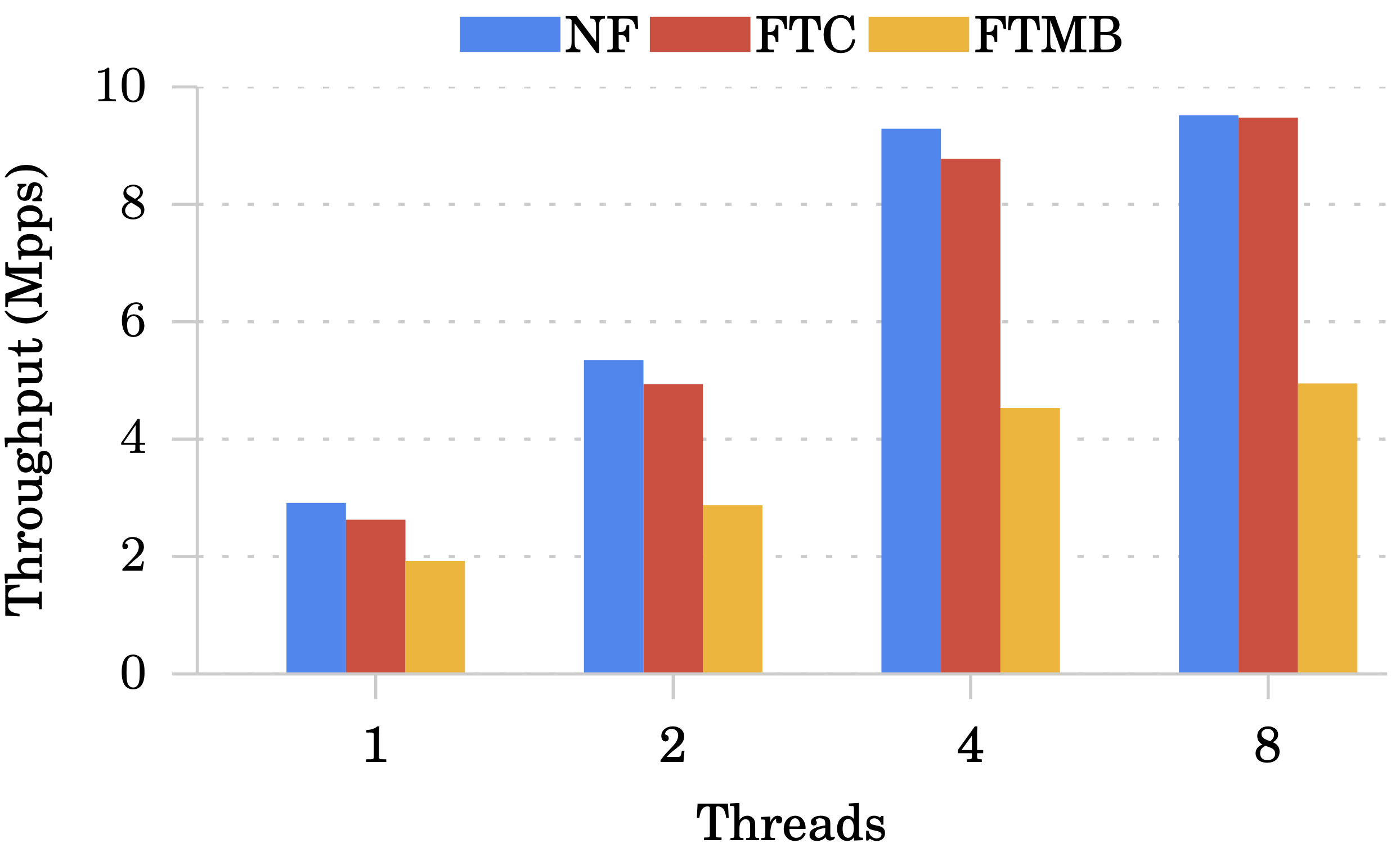
可以看到在單執行緒時(左圖),FTC 跟 NF 可承受的 traffic load 差不多。
再看往右圖,可以發現執行緒的數量跟延遲並沒有太大的關聯。
Fault Tolerant Chains
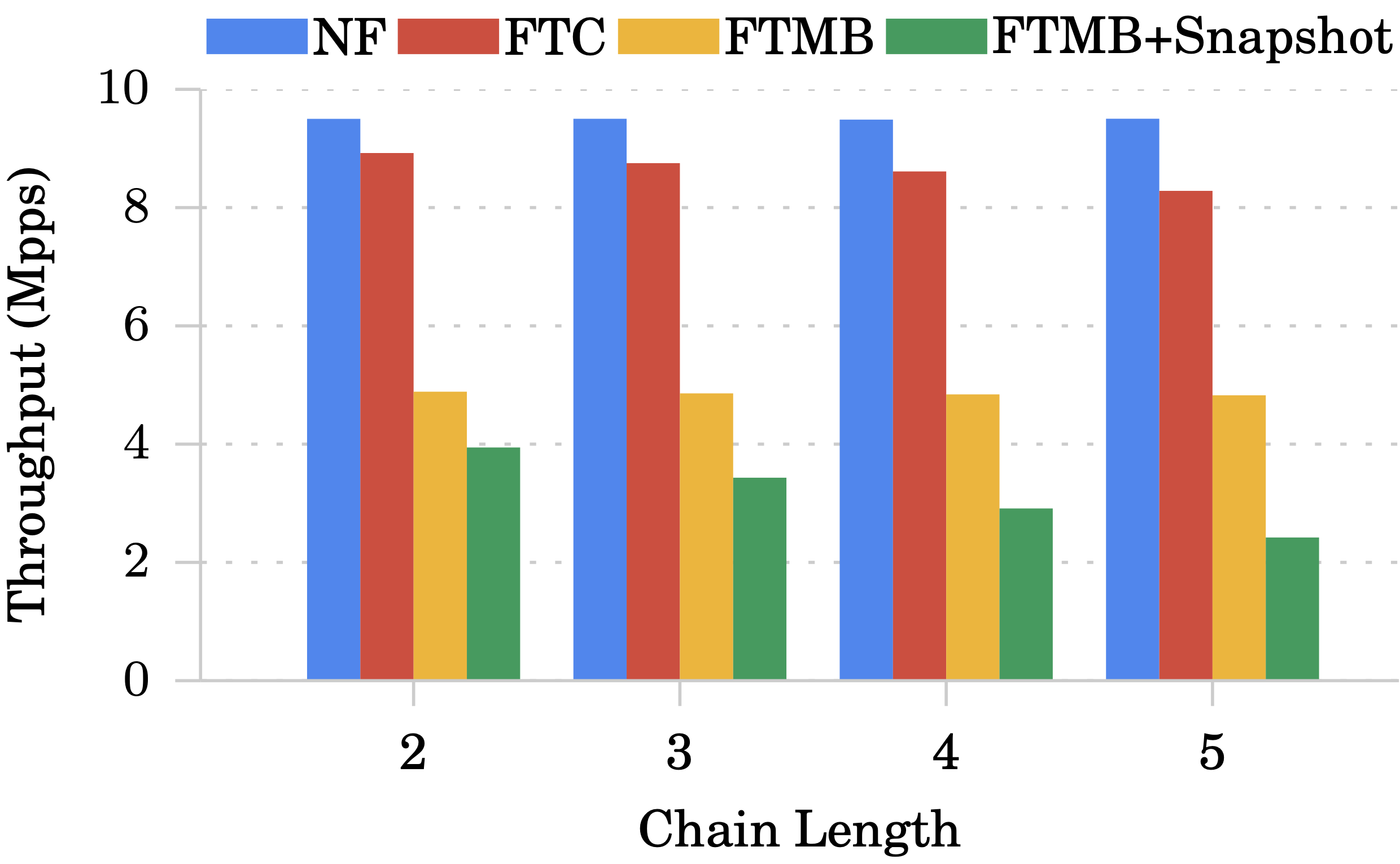
Chain 長度對吞吐量的影響:
Monitor 使用 8 執行緒且 Sharing level 為 1。
可以看到 FTC 受到的影響不大,FTMB+Snapshot 受到的影響比較大,因為 snapshot 的時候封包處理會暫停,但封包持續進來導致 queue 會越來越滿。
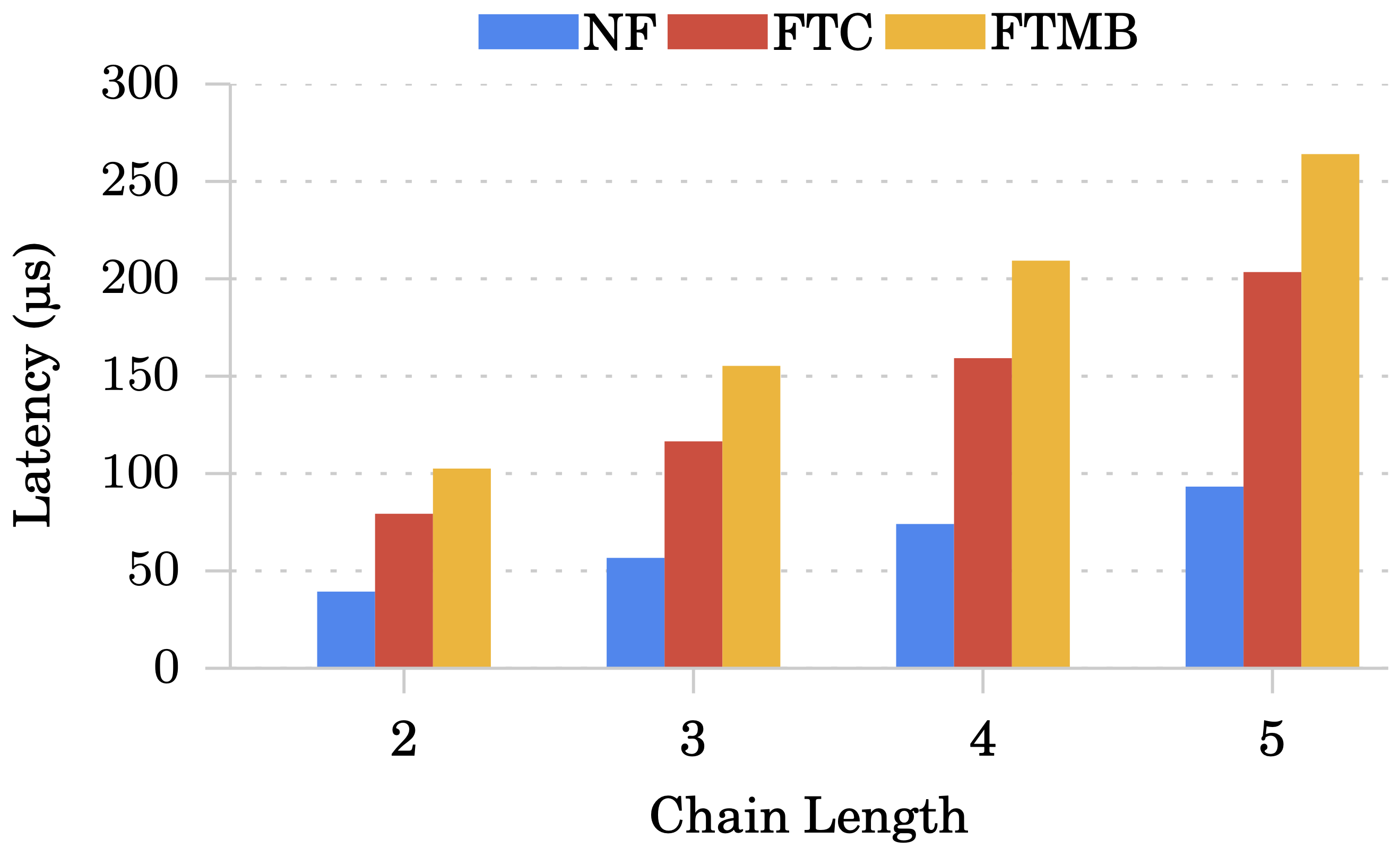
Chain 長度對延遲的影響:
與上面實驗相同的設定,只是 Moniter 使用單執行緒(受限於 traffic generator)。
編按:跟 traffic generator 有什麼關係?
- FTC 每加一個 middlebox 約比 NF 多增加 20 μs
- FTMB 每加一個 middlebox 約比 NF 多增加 35 μs
FTC in Failure Recovery
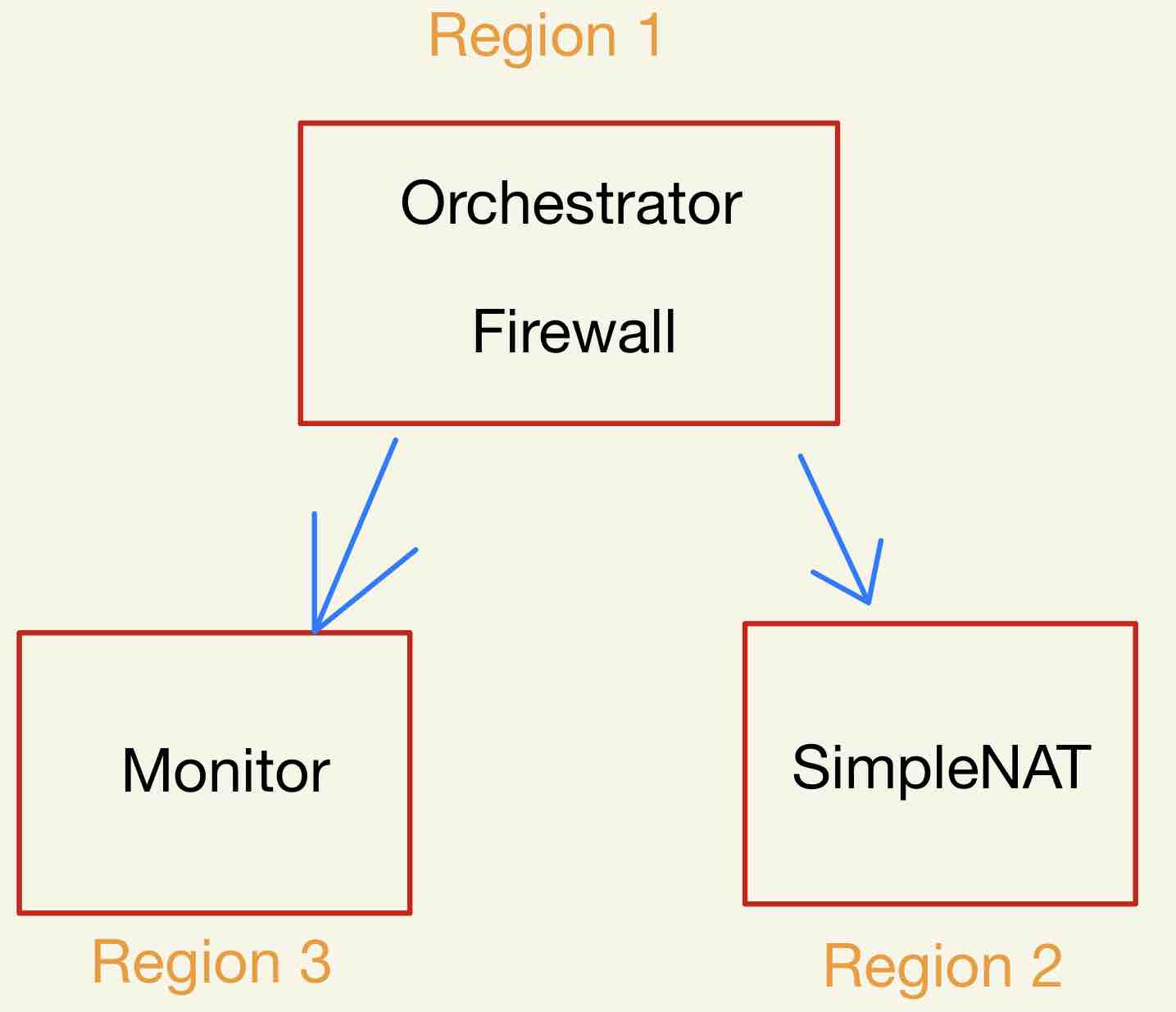
作者利用下圖方式部署在雲端
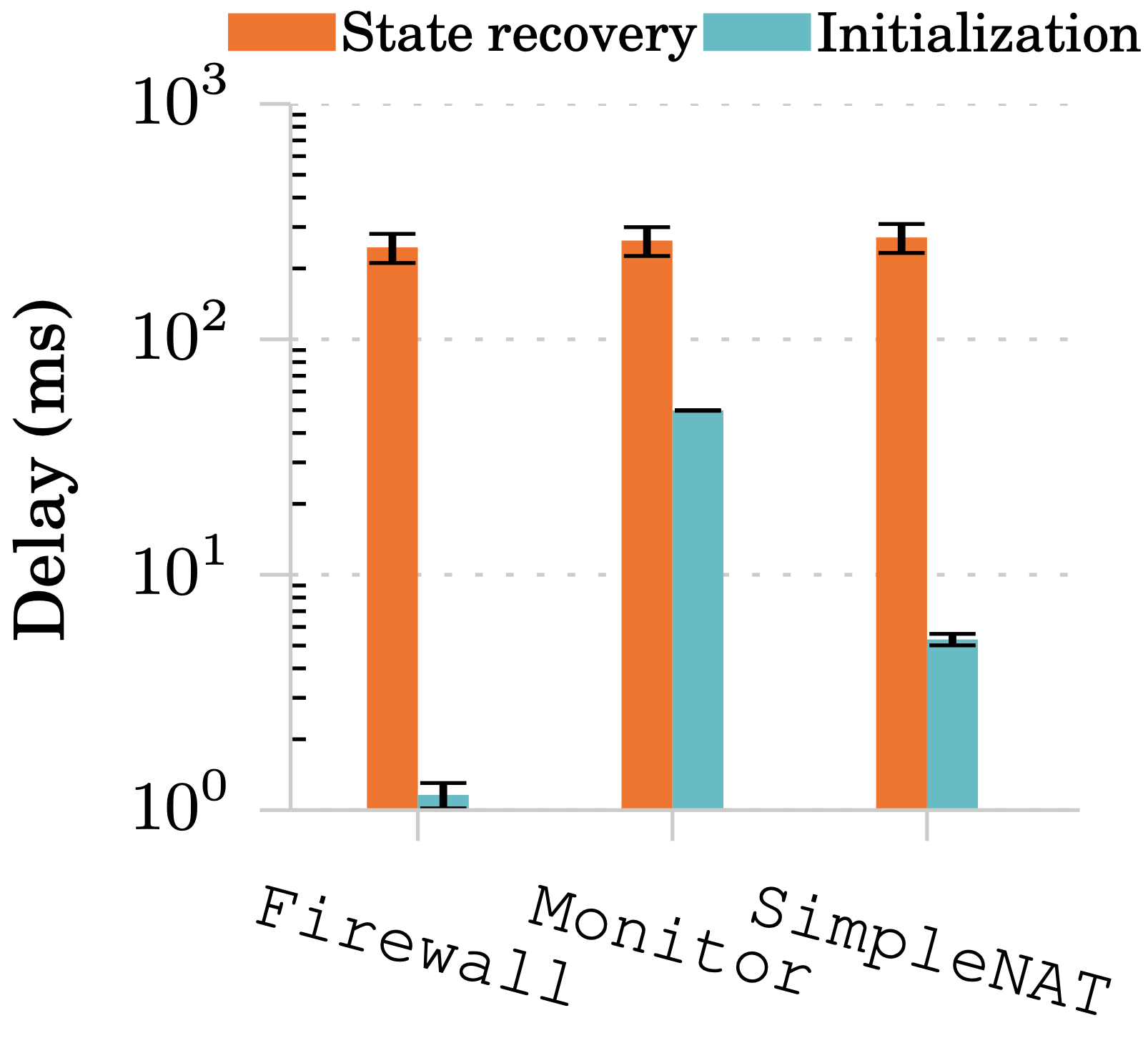
還原時間:
初始化時間分別為:1.2, 49.8, 5.3 ms
還原時間從 114 ~ 270 ms。相比於在 local area network 的 FTMB 其時間約為 100 ~ 250 ms。
有鑒於還原時抓取資料可以平行處理,因此延遲不高。
名詞解釋
Transactional Memory
在並行程式開發中,除了使用 鎖 來達成 Atomicity,也可以使用 transaction 方式,使得程式可以更容易的安全地在平行、共享記憶體環境執行。
實務上使用軟體、硬體、混合方式達成,使得不同 thread 之間平行執行的結果可以跟循序執行結果一樣。硬體方式速度較快,但由於 CPU cache 小能做的事情不多;軟體方式較為彈性但效能差。使用 transactional memory 方式可以免去 deadlock 問題,也不需要考慮需要哪些 lock,程式因此可以更加彈性;混合方式則是在可用情況下使用硬體方式,無法完成要求時採用 鎖 的方式,還是在複雜的情況下使用軟體方式實現。
一般來說「Transacitons are used correctly」是指:
- thread 間的共享資料都得經由 transaction 存取
- transaction 所有操作都可以 rollback
不過 library-based 的程式語言雖有這功能(C、JAVA),但卻無法完整達到上述理想,在實務上有機會遇到一些 bug。硬體上可以透過 Intel TSX 推測執行技術達到。
雖然好處不少,但仍可能會有 livelock 的問題產生,也可能會有 starvation 問題。
Transaction memory 有三種屬性:
- 原子性(Atomicity)
- 事務作為一個整體是不可分的,即其內部的操作要不是全部完成,就是全部不完成
- 一致性(Consistency)
- 任何一個對共享資料進行訪問操作的事務在其執行前後系統的狀態都應該是一致的
- 隔離性(Isolation)
- 事務在正常提交之前,其內部的操作對外是不可見的,即未提交的事務操作不會影響系統的狀態
在知乎的內文提到 transactional memory 執行流程大致為:
// Create threads that use transaction
// Declare transactional data
Begin_Transaction();
// Read and Write
// transactional data
if something happens
Abort_Transaction();
End_Transaction();
// Commit or Abort
在 End_Transaction() 前,這些資料的修改都只是在 transaction 內部預先執行、模擬結果,因此實際上這些值都尚未被改變。
之後執行一致性檢查(確保執行過程中,用到的資料沒有被其他 thread 修改),沒問題即將 transaction 內變動之資料寫入到記憶體中;否則將 rollback。
參考資料:
Wound-Wait vs Wound-Die
在 transaction 中,這兩種都是避免 starvation 的方法。
- Wound-wait
- 較早進入交易的可以搶資源,較晚的需等待
- 撤回次數較少
- 以 preemption 為基礎
- 當 $Ti$ 要求一個正被 $T_j$ 持有的資源時,如果 $T_i$ 比 $T_j$ 晚到(看 timestamp),則 $T_i$ 會等待;否則 $T_i$ 會把資源搶過來,$T_j$ 就會被撤回。
- Wait-die
- 較早進入交易的可以等待,較晚的會被撤回
- 撤回次數較多
- 以 no preemption 為基礎
參考資料:
comments powered by Disqus