概要
當今的 NFV 框架都是封包取向的,對於處理較複雜、上層(應用層)協定會顯得沒效率。
Microbox 支援 transport、application 層(TCP model)的 middlebox 以及像是服務等終端系統。
僅是引入 TCP stack 到 NFV 框架是相當沒效率的,因為大多數 NF 僅需要 TCP bytestream reconstruction 技術來滿足終端需求。NF 藉由基於 publish/subscribe 的 API 來存取所需的封包或是 event,並且消除不同 chain 中冗餘的處理,同時使用模組化設計。
使用 OpenNetVM、DPDK 技術打造,並整合 stack operation,此專案共可以提升 51% 吞吐量。
與知名專案 HAProxy 相比,吞吐量、延遲都有 30% 以上的提升。
1. 介紹
- Publish/subscribe 架構提供便利、較抽象的方式來進行 event 操作而不是針對封包做處理
- 整合的 protocol stack 消除每個 NF 都會自行設計解析程式碼的冗余步驟
- 可客製化 stack 提供輕量級 TCP state 監控、TCP 兩端 proxy
- NF、Stack 非同步平行處理,以改善擴展與一致性問題
2. Middlebox Stack Diversity
“One size fits all” 的 TCP stack 設計是很難實現的,因此作者針對不同情況有不同的作法,而這些不同的作法可能會被整合進同一台主機上。
下圖是常見 NF 的處理需求:
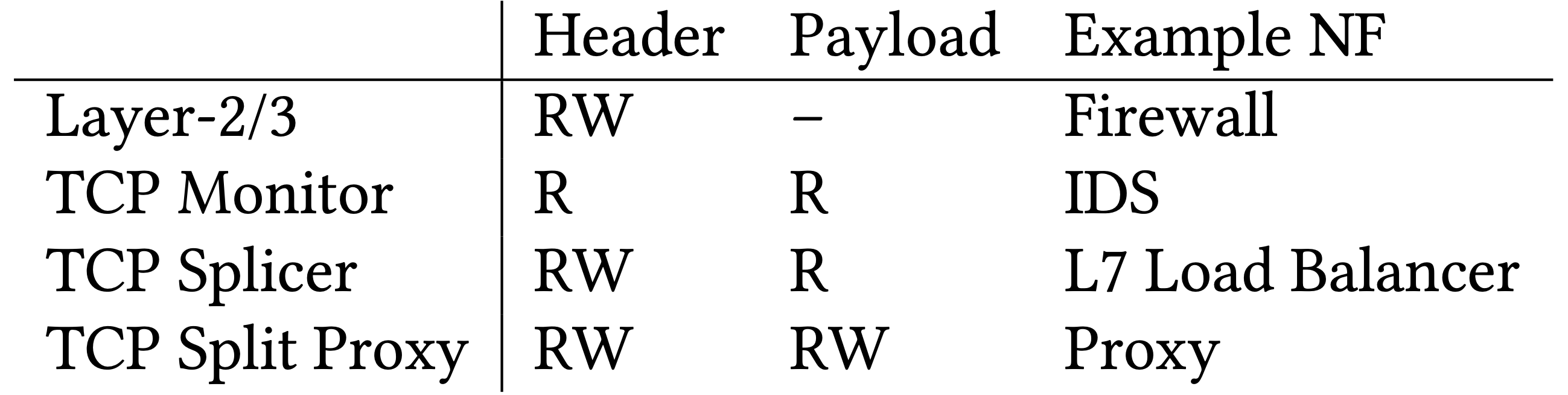
- Layer-2/3
- 不需要 TCP state,但可以能需要修改封包表頭的資訊
- TCP Monitor
- 需要 TCP reconstruction、flow state
- TCP Splicer
- 需要讀寫 TCP header 以轉送封包
- 例如:L7 LB 需要進行完三向交握後,分析封包中 HTTP GET 請求之資源,來決定要交由哪個後端伺服器處理
- TCP Split Proxy
- 需要 bytestream 完整的讀寫權
- 例如:split proxy 可能會壓縮伺服器的回應再轉傳給客戶端
為了知道 procotol 處理的開銷,作者替這些不同的 NF 做了簡單的效能量測:
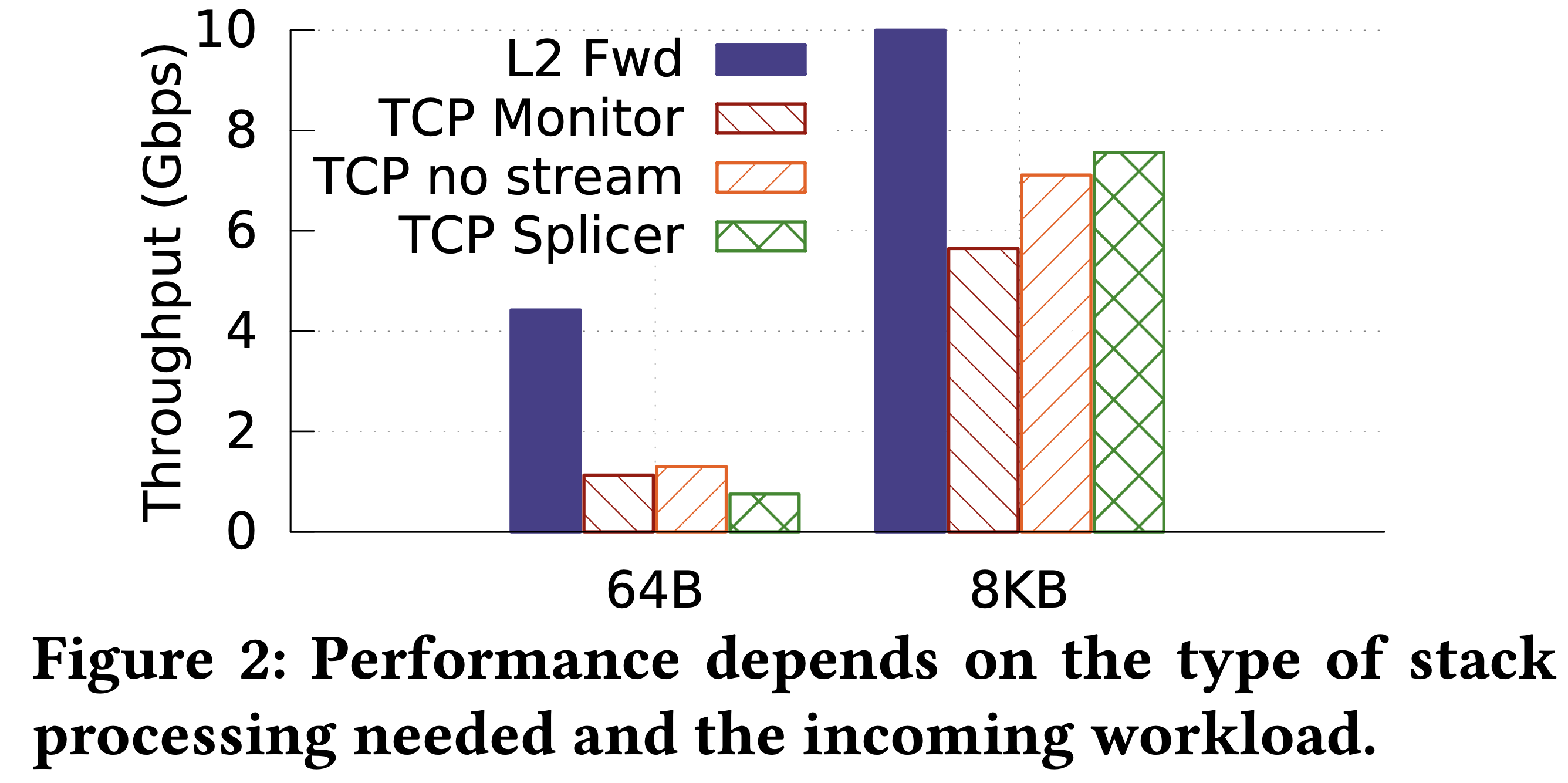
可以看到 L2 Fwd 明顯高於其他,這是因為它僅將封包傳出 NIC。(作者有提到在 64B 情況下,Web server 跟 client 會是瓶頸)
- TCP Monitor
- 使用 mOS TCP middlebox library 來追蹤連線、重組資料流(reconstruct bytestream)
- TCP no stream
- 與 TCP monitor 一樣,只是沒有重組資料流
- TCP Splicer
- 一開始先回應 client,接著向伺服器重送(replay) TCP 握手
- 這在封包小的時候 overhead 會很大,因為需要一直建立新的連線;在封包大時倒還好,因為主要是在連線建立後轉送資料
- 使用 DPDK
上面結果顯示,NFV 平台在處理不同需求時會需要不同的 stack 處理。
因此本篇動機為為每個 flow 客製化具有彈性的 protocol stack,以減少開銷。
3. Microboxes 設計
作者先介紹了 monolithic NF 架構與 pipeline 架構,最後選擇使用 pipeline 架構。
- Monolithic 架構
- 優點:降低 chain 的 overhead(因為只是 function call)
- 缺點:
- 彼此緊密結合,不好個別加速
- 安全、隱私問題(不同 function 之間的隔離)
- 舉例:BESS 與 mOS
- Pipeline 架構
- 優點:
- 每個 funciton 運行在獨立的 process 或 container
- 不同供應商所做的 NF 可以容易的串接在一起
- 彈性擴展
- 缺點:chain 越長 overhead 影響越大
- 舉例:Microboxes、OpenNetVM、ClickOS
- 優點:
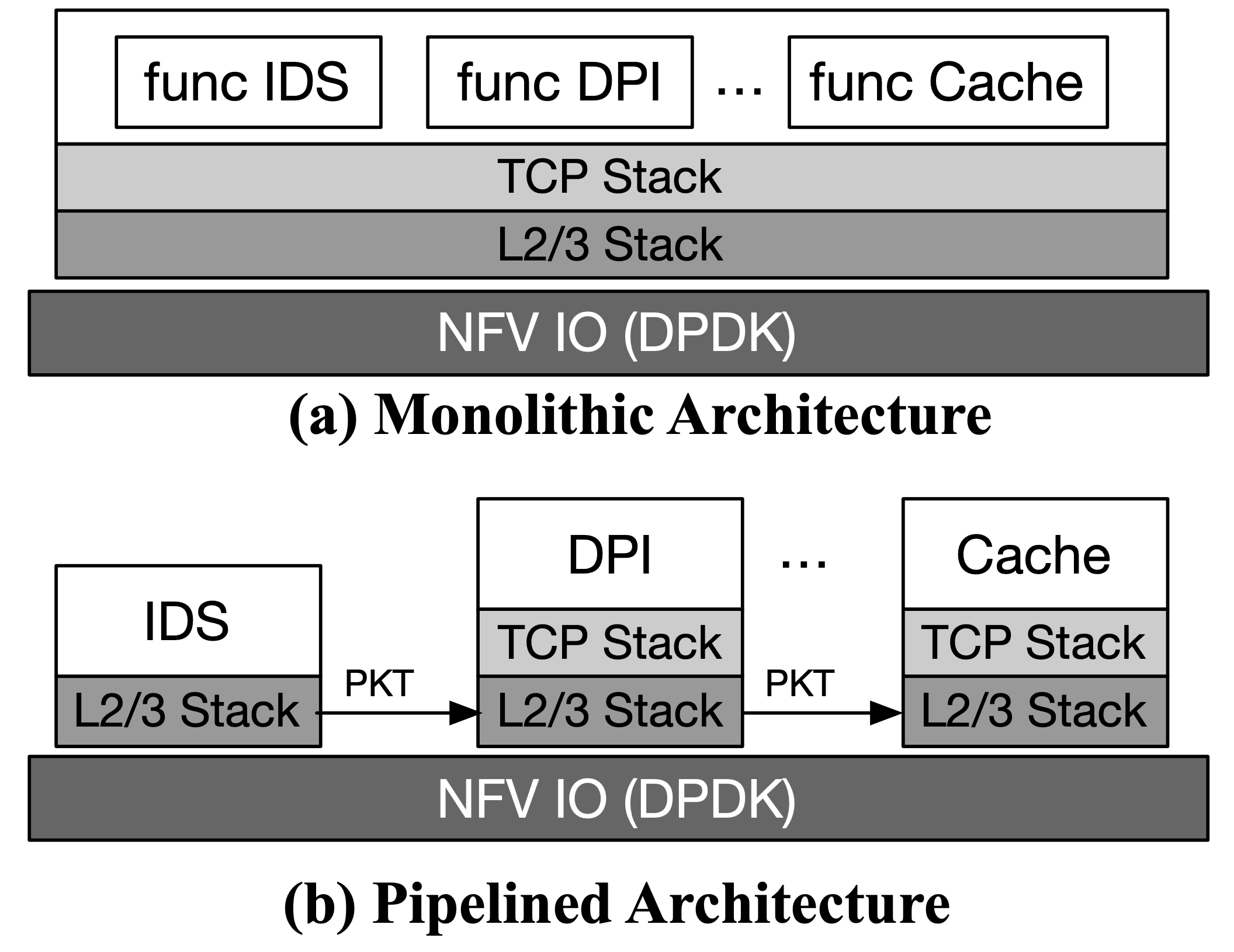
然而,OpenNetVM 與 ClickOS 皆專注於封包轉送,而不是上層 protocol stack 的處理。
Microboxes 避開了這種封包導向的設計,透過 μStack 來處理常見協定,並且透過彈性的 μEvent 接口來消除 NF 間的冗余工作,同時又保有 piple 的部署彈性。
μEvents
Event 可以經由 ptotocol stack 或是 NF 產生,基於 subscriber list 可以知道哪些其他的 NF 對此 event 感興趣,Microboxes event management system 會傳送 event 到不同的 NF 以觸發需要的協定、應用層來處理封包。其中 subscription 是由 Microboxes Controller 管理,並可以使用 per-flow 來篩選。
Base Event Types
- 定義用來加速通訊的階層式訊息格式
- 定義 NF 與 stack 如何互動
- Event 必須遵守明確規範的型態,確保訂閱者可以正確解析訊息
- 作者假設開發者會為 event 提供 event ID 與資料結構的定義
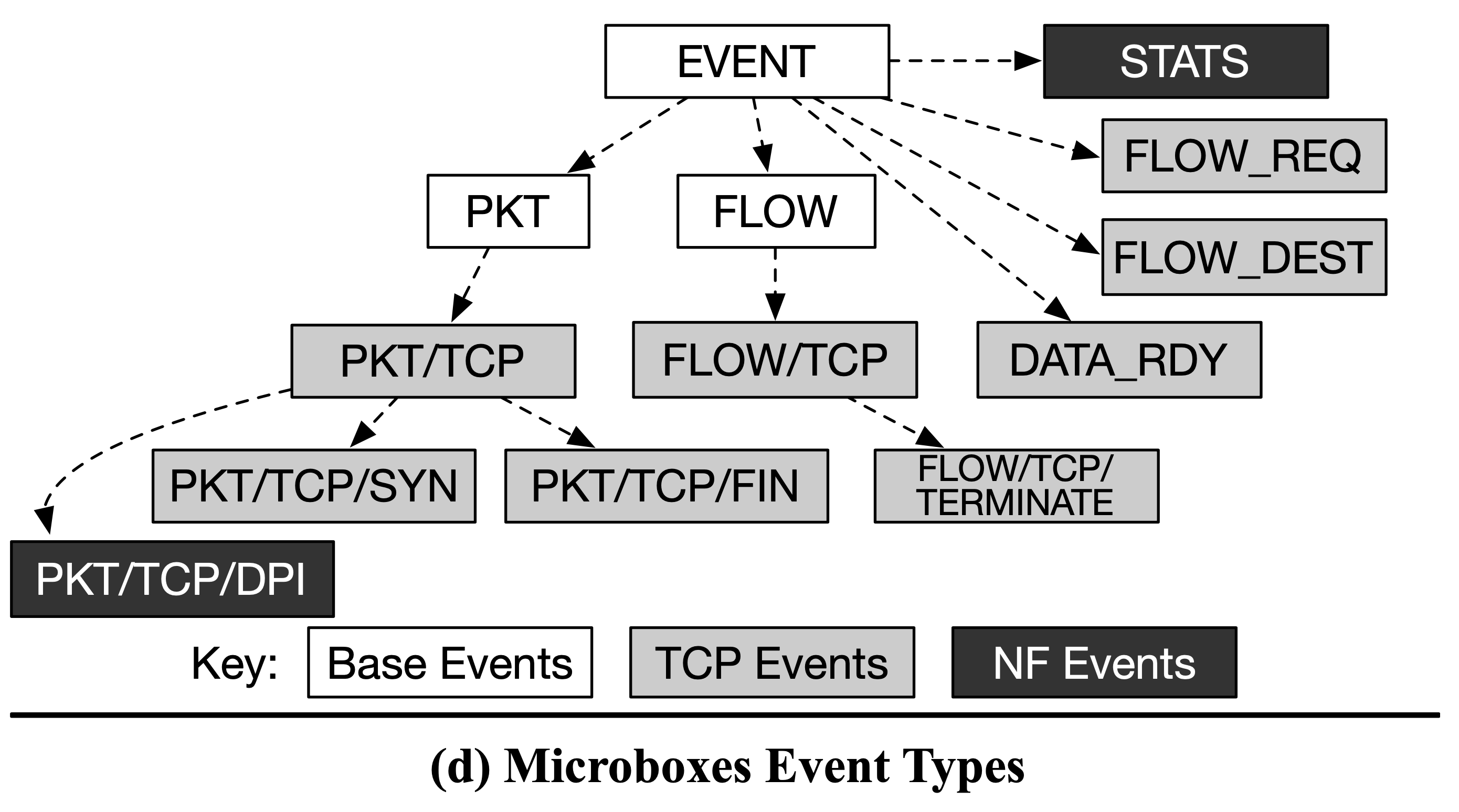
Event是最基礎的型別,所有其他型別都是基於此,並且透過欄位來定義 event type 與發布 NF 的 IDEvent/PKT繼承了 Event,包含特定封包資訊Event/FLOW是給那些不需要知道所有封包的 NF,僅需知道 FLOW 狀態改變- 舉例:只需要知道 FLOW 的開始、結束
- 方便起見,作者在表示時會省略
Event這個前綴
Event Hierachy
- 可以被繼承
- 彈性化的型別檢查、方便 NF 選擇需要的 event
Event Subscription
- 提供 NF 與 protocol stack 推播、訂閱 event 以交換資訊與觸發一些處理
- 當 NF 啟動時,會使用 event type 來訂閱並且提供 callback function
- Controller 可以進行型別檢查,決定新的 subscription 該如何連接上 publishing
X/Y是X的嚴格子集,因此X/Y至少包含了所有X有的欄位- 因此 NF 若訂閱了
X同時也能處理X/Y的訊息 - 此種方式比先前沒有定義 NF 間共享資料格式的框架還要好
- 比起 Click 的 push & pull port,此方法多了階層式型別
作者的想法受到前人作品 mOS、Bro 的影響,但仍有三種不同:
- mOS 雖然允許自行定義 event,但 event 的處理是在 single monolithic process
- 作者將其分為各個獨立 stack、NF(可為 container 形式),好處是有更好的 performance isolation 與 security level 選擇
- 結構化的 event type 允許 NF 繼承基礎型別,同時保有可互動性
- 作者注重訊息的資料結構,而不是觸發 event 的訊號
- Controller 可以使用在 NF 中定義的 publish/subscribe 型別來決定哪些 NF 可以相互連接
- 這有益於不同組織開發的 NF 以鬆耦合方式部署
- 以前的方式都是得由開發者自行處理不同 NF 連接問題
μStacks
最簡易的 μEvent 是在 Layer 2/3 處理後的 publish。
NF 的開發工作可以利用訂閱許多複雜的 event 來簡化,也就是上層 protocol stack 的處理結果,舉例:重建 TCP bytestream 的新資料、三次握手。 Microboxes 將 protocol 處理邏輯從 NF 中分離出來,並且實作了模組化、階層式的 μStack。
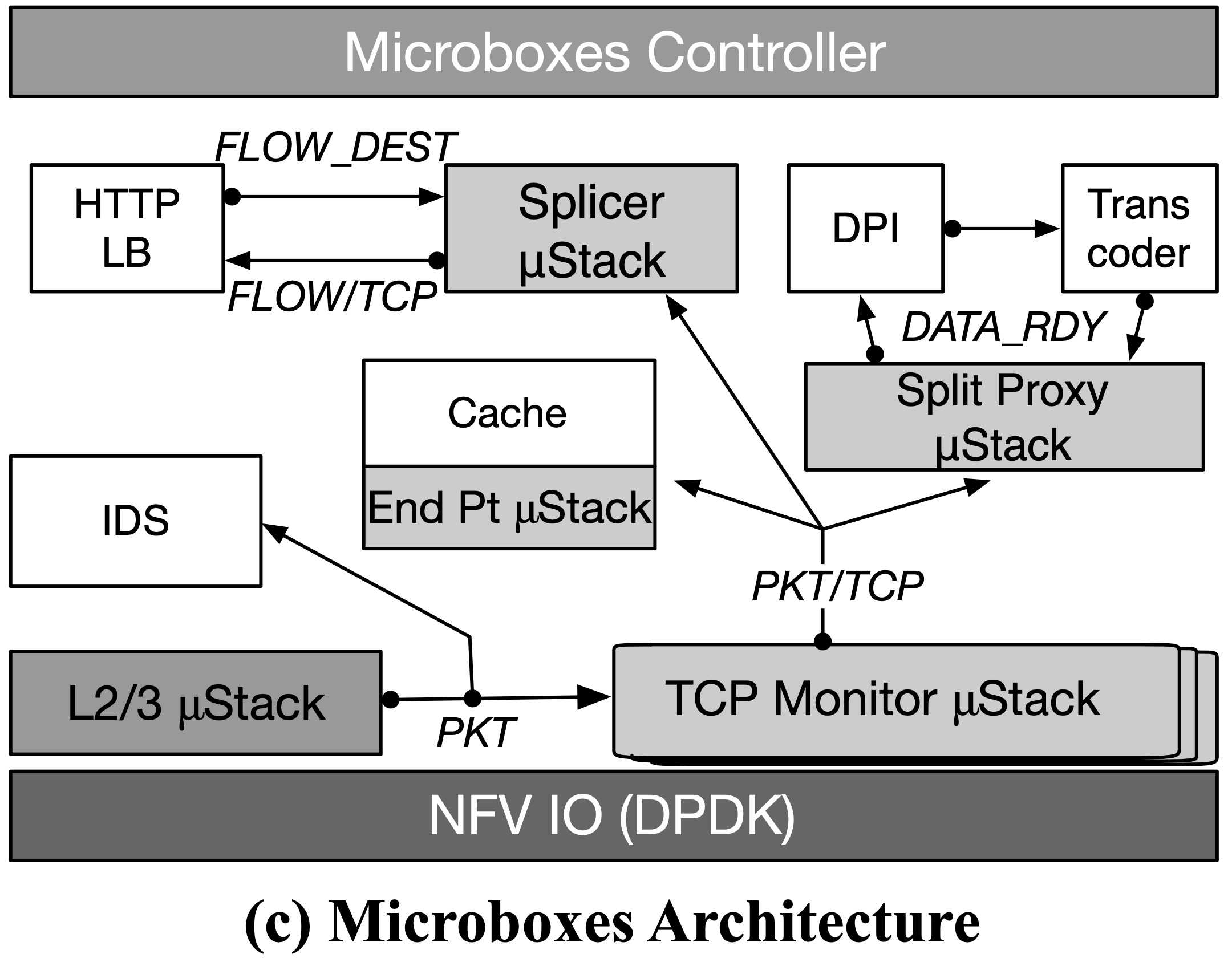
上圖可以看到只有:
- Cache 需要 full TCP endpoint termination(編按:猜是指說連線關閉時才做整體 cache 記錄)
- IDS 不需要任何 TCP 處理(因為接收 PKT event)
縱使有了模組化, μStack 必須要建立在其他現有 μStack 上以避免冗余操作。
μStack 是基於 mOS,其為 monolithic NF 提供高效率網路堆疊,其 twin stack 設計使其能夠追蹤兩端的 L4 state,這可讓 NF 選擇訂閱 client 或 server 端的 TCP connection event。
編按:twin stack design?
然而,因為一致性問題與效能挑戰,只利用 mOS 當作 μStack 是不夠的,這會在第四章討論。
雖然每個 μStack 都提供不同的功能,但是資料修改是在共享的 flow table,因此 event 必須連結到原始封包,這樣 stack 才知道 Application 層何時處理完畢。
編按:跟原始封包有什麼關係?
當所有 NF 都執行完畢,會有個 message 傳送到相對應的 μStack,其就能完成處理以回報給 L2/L3 stack 將封包送出 NIC。
編按:為何多個 NF 只有一則 message?
Controller
兩個主要功能,其一維護 NF 註冊表與其 event 型別(發布、訂閱),另一為類似 SDN controller,包含指定 publisher 與 subscriber 們該如何連接的邏輯。這類的想法跟 Microservices、SDN 很像。
每個 NF 或 μStack 模組會向 controller 提供 message type 以註冊 input ports (subscriptions,透過 mb_pub API)、output ports (publications,透過 mb_sub API),一個 subscription 可能對應到多個 publication ports。而 controller 負責檢查型別、媒合 NF,以確保 event type 是一樣的,或是 publication 是 subscription 的子集也可接受。
作者假設每個 event type 都會有個 UID 與公開的資料結構,假設有個名為 PKT/TCP/SYN 的 event,但實際上會將其轉會成獨一無二的 bits。
NF 也會 publish 其所有 event type 給其訂閱的 NF,這可用來讓 controller 組織 chain。
編按:啥東東?
當 NF 修改封包內容或 μStack 狀態時,會在其 publication 中特別指名,這可當作 controller 判斷 NF 是否能平行處理的依據。
Application
由一個以上 μStack 與 NF 組成,NF 只用它所需要的 stack module。這讓開發者可以建立通用型 module,以用來讓 controller 彈性建立更複雜的 service。
下面會舉兩個高彈性的例子:
- Splicer μStack 實作了一部分 TCP Stack 的功能,能夠在收到第一個 payload data 時轉送整個 flow,然而這項功能得依賴其分離出的 load balancing NF 後端來選擇路徑操控 Splicer。
上圖可以看到是接上一台 HTTP LB NF,或是也可以接上 Memcached LB NF 之類的 policy engine。Splicer 首先會推播
FLOW_REC訊息來表示三次交握完成,同時附上包含重組後的 bytestream 指標,此時 LB 若有訂閱這個 event 就會檢查該 payload 來選擇合適的路徑並推播FLOW_DEST訊息,此時 Splicer 會依照指示建立 TCP 連線以轉送封包。 一個 stack 可以連接多個不同的 policy engiine 以轉送不同的 protocol type(destination port 之類的)。 - Event 的訂閱也具有彈性。舉例來說,IDS NF 雖訂閱了
PKT,但 controller 可以依據當時整體需求考量將其分配到PKT/TCP,畢竟後者只是資料多了點,該有的資料還是有。
4. Asynchronous μStacks
首先會先釐清將 NF 與 Stack 平行處理時遇到的挑戰,接著講 Microboxes 克服挑戰所使用的技術。
Consistency Challenges
不管在 monolithic 或 pipeline 系統,每個 NF 都會盡量在一個 processing context 的時間內完成,如此可以避免 concurrency 問題。
編按:是指 context switch 嗎?
Microboxes 為多核心協同運行,stack 與 NF 可以同時處理同個封包,因此作者力圖尋找在 protocol stack 中更夠實現對 NF 有相同執行結果的執行順序。

圖 4(a)
上圖是一個 pipeline 執行的例子,每個 NF 都在專屬的核心上執行,不同顏色代表不同的封包,綠色封包在 Core 0 執行完便會被送到 Core 1,以此類推。
不過在 stack 與 NF 處理間會有一致性的問題產生,也會增加不必要的延遲。
編按:一致性是說 P1 還沒處理完就處理 P2,會不會有些狀態還沒更新完 不過額外延遲是怎麼來的? 每個 NF 執行速度不一是否也會導致資源浪費?
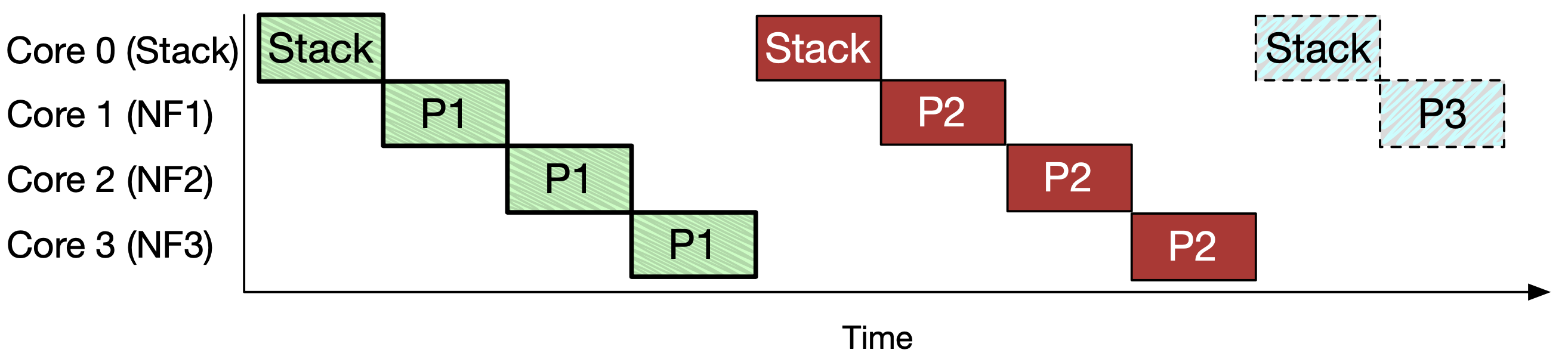
圖 4(b)
上圖是一個比較安全也比較慢的作法,將 stack 單獨抽離出來,為了一致性問題必須得在 P1 處理完才能處理 P2,這時候或許就可以在中間的等候時間加入其他 flow 的封包(前提是不同 flow 間的狀態不會互相影響)。
Stack Consistency:
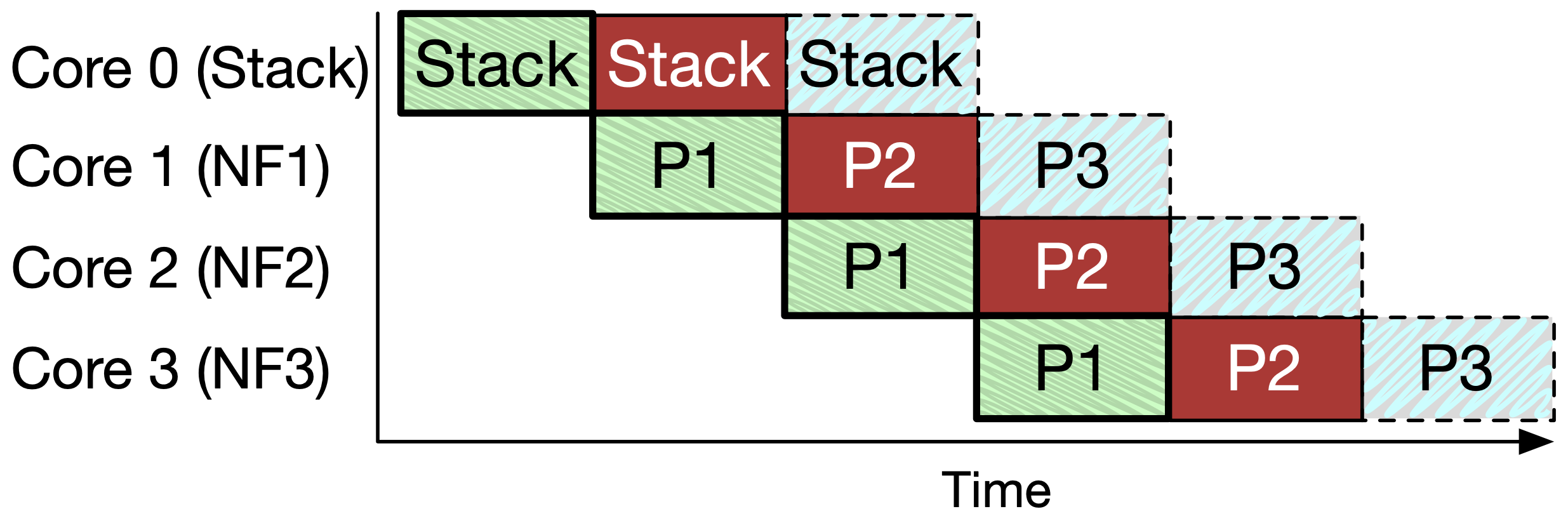
圖 4(c)
上圖處理方式較有效率,但僅針對只會讀取封包、且 state 狀態保證會在下一個封包到達前改變完成的 NF 才可以這麼做,不然會有一致性問題。
舉個例子,在 P1 在 NF1 執行期間,可能會詢問 consolidated stack 關於 protocol 狀態資訊,但若此時狀態正好被 P2 改掉那就糟糕了。
作者特別提到說在他們的實作中,NF 可以回應關於 client-side 或 server-side 的 stack processing event 。
NF Consistency:
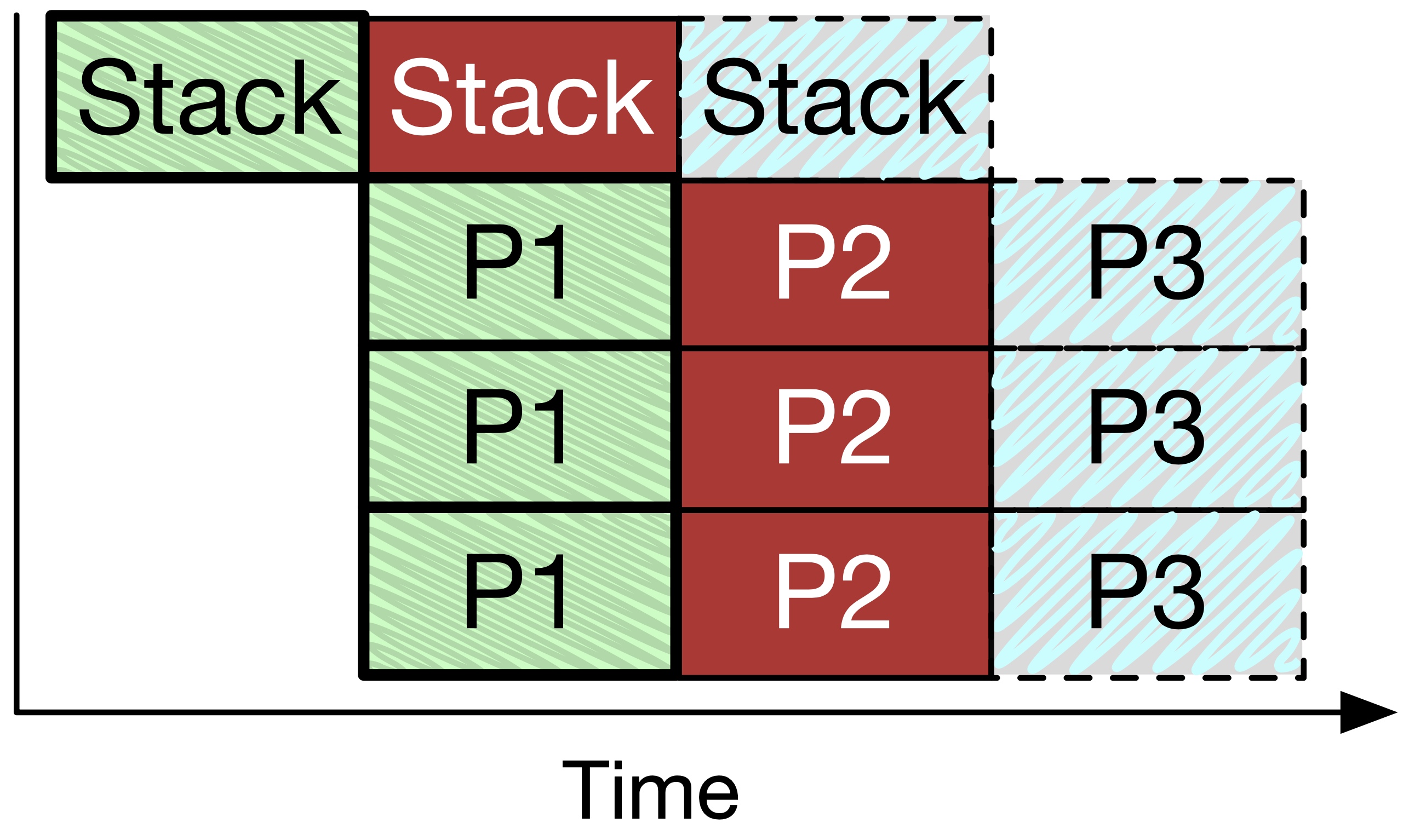
圖 4(d)
上圖 stack 與 NF 平行處理為較為理想的狀態。Microboxes 不只需要解決 stack 一致性問題,也需要避免多個 NF 同時修改封包。因為 NF 是以線路速度在運作,傳統 concurrency 解法如 locks 可能會造成難以接受的 overhead。雖然如此,許多之前的文獻指出這種平行運行的方式可以在 read-only 或不讀寫的相同封包的 NF 中實現。
編按:這有解決 concurrency 問題嗎?
Asynchronous, Parallel Processing
用了四種方法來確保 NF 與 stack processing 為高效率且一致的:
Asynchronous Stack Snapshots
- 為了避免之前提過的 stack 狀態改變,作者在 event message 中加入 stack 的 snapshot
- 例如 seq num、timestamp 等資料可以被複製到 event 的資料結構當中
- 不過複製 bytestream 卻是不可行的,所幸可以使用 append-only 方式來取代,因此 snapshot 中只需要有指到 bytestream 尾端的指標即可
編按:作者沒說為何 bytestream 複製不可行,猜測是開銷太高
- 為了確保 bytestream 不受重組影響,μStack 會在 event 發出前建立一個
frontier指標來標示 append-only 邊界,在 frontier 前面的部分將會保持不變
編按:重組發生,是否是受到後來的封包影響?frontier 是否會更新?
使用 stack snapshot 方式可以避免 stack 一致性問題,讓 stack 與 NF 可以如圖 4(c) 那樣運作。
Parallel Events
用來達成 stack 與 NF 的完全平行處理,如圖 4(d)。
Controller 可以將多個 NF 的訂閱連接到像是 splitter 的 NF 上,收到 splitter output 的 NF 們執行完它們該做的事情後會回報,由 splitter NF 統計 reference count,完成後 splitter 會視情況將這些回傳的結果合併成一份,並將 event 轉交給下個階段。
編按:splitter 就好比一對多的轉接頭。 作者沒說 splitter 怎麼知道 reference count 要是多少才是完成
舉例來說,firewall NF 會 multicast event 給多個安全監控 NF,再綜合判斷回傳結果以決定是否放行這個封包。
當然要能做到這樣,NF 們本身得是 read-only 的才不會發生衝突,這在 NFP 與 Parabox 中皆有提到。
Modifying Packets and Stack State
NF 若需要修改封包、event 需要在其 output port deifinition 中表明,這樣 controller 才知道這個 NF 是否能夠平行處理。
為避免 race condition 發生,NF 不能夠直接對 stack state 做修改,而是得透過 event-based API。
舉例來說:μStack 訂閱了 FLOW/TCP/TERMINATE event,這可能是由防火牆想要擋掉連線(回傳 RST 封包)而發布的,這避免了 stack state 的一致性問題,但也就是 NF 必須要處理非同步問題,像是防火牆說要丟包了,但有些 stack 已經處理了這些封包。
Parallel Stacks
為了將多核心的處理效能最大化,作者使用 RSS (Receive Side Scaling) 技術讓同個 flow(雙向)可以被送到相同的 stack 與 NF,不同的 flow 則可能被送到不同的 CPU 核心。
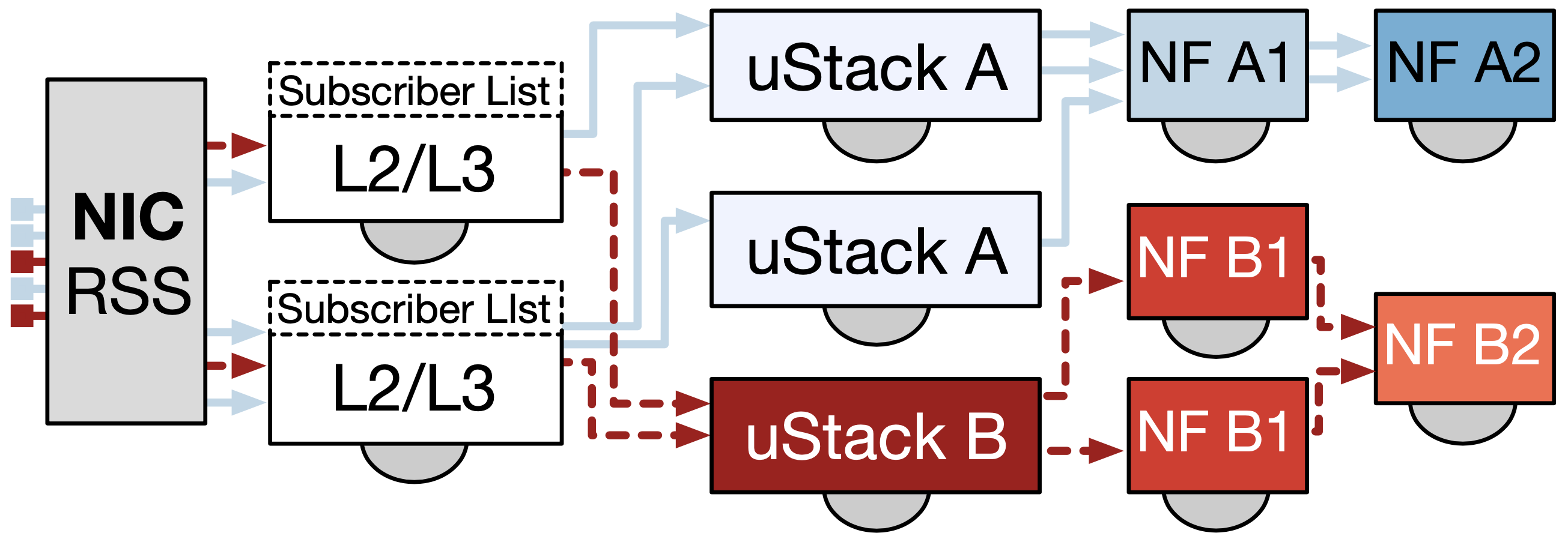
上圖可以看到 μStack A 跟 NF B1 都有被擴展複製, L2/L3 stack 會查找 subscriber list 來決定該發送 evnet 給哪種終點 stack type,其中使用 RSS 的 hash value 來挑選擴展的 stack。
除了 flow 之外,像是 TCP flow state table 等資料結構也會被分到不同的 CPU 核心上以避免平行處理 stack 間的 contention。
編按:為啥會有 contention?
5. 客製化 μStack 模組
不同 flow 所經過的 μStack 也不同,這些 stack 可以客製化以符合需求,減少不必要的處理。
這些 stack 初步處理過後都會交由 NF 進行其所需的邏輯規則,而 Microboxes TCP stack 拆分為以下幾個 μStack 模組:
Network Layer:
當封包到達時,首先經由 Layer 2/3 來決定它屬於哪個 flow,之後該流經哪些 μStack 做處理。
同時維護一個很小的 state-flow 狀態表,像是總封包數、flow 狀態追蹤,並且發布 PTK 與 FLOW event。
編按:可是 Microboxes 架構圖,flow event 沒有跟
Layer 2/3連在一起 🤔
TCP Monitor:
企圖追蹤 Client 與 Server 端的 TCP state,好讓 monitor 類型 NF 重建雙向 bytestream,並且觀察 TCP 狀態變化。
舉例來說,為了要支援有狀態防火牆的禁止 bytestream 的 full termination 與 arbitrary transformation,作者使用 mOS middlebox TCP library 打造 client 端與 server 端的 μStack。
編按:什麼是 full termination 與 artitrary transformation?
TCP Monitor 會訂閱 Network Layer 的 PKT event,並會產生 EVENT/DATA_RDY 表示 bytestream 的改變,或是 FLOW/TCP 表示 TCP 狀態改變。
NF 們可以指定哪些 flow 的 client 或 server 要訂閱這些 event,因此 TCP Monitor 可基於此來決定是否要重建某個 flow 的 bytestream。
編按:作者有提到只能對 bytestream 內容做適當的修改,但不能隨意修改,因為改變封包大小會造成問題,但為何作者在改變大小時不重算 CRC 呢? 猜因為這不是 Monitor 該做的事情,這得交由 Bytestream NF
TCP Splicer:
Proxy 形態的 middlebox 可以在三次握手後,將連線重導到其他地方。舉例來說 HTTP Proxy 可以藉由觀察 GET 請求的內容來決定要將請求往哪台 server 送。
在 Middleboxes 中藉由將 TCP Monitor 進一步做延伸來達到此功能就不用複雜的 full TCP endpoint。
編按:跟 TCP endpoint 有何關係?
Splicer 首先會回應 SYN-ACK 封包給 client,在交握結束並且收到相關資料後發出 FLOW_REQ event 給具有 proxy logic 的 NF,這個 NF 會使用 FLOW_DEST 回應目標 IP 位址,接著 Splicer 會與目標建立連線,並把之後的封包都導向到其這個快速通道,因此 Splicer 僅需修改 seq num 來達到 zero-copy TCP splicing。
這也可以透過截斷兩方連線的方式達成,像是 split proxy,不過這會需要額外的 TCP logic,如果只是單純要重導封包(沒有要修改 bytestream)其會有額外的 overhead。
編按:這有講等於沒講?
TCP Endpoint:
Microboxes NF 也可以當作是 TCP endpoint,像是用來快速回應的 cache server。
其也是透過將 TCP Monitor 進一步做延伸來達到 full TCP logic(如壅塞控制、重送等等),可以輸出類似 socket API 的 event。
作者使用 mOS 與 mTCP 技術使 NF 可以用 EPOLL 介面連接到 μStack 的 socket。NF 開發人員可以使用流行的高效能 EPOLL 介面來進行 socket programming。
TCP Endpoint 的支援對不同種類服務的部署來說是個機會,例如在 edge cloud 提供 CDN caches 或是 IoT 資料分析。
TCP Split Proxy and Bytestream NFs:
最複雜的 NF 種類,用來轉換與遍歷 bytestream,作者稱為 Bytestream NFs。
對此需要兩條 TCP 連線,一個連 client 另個連 server,這允許 redirection(像是 TCP Splicer stack)、artitrary bytestream transformation。
Microboxes Proxy μStack 使用兩個 TCP Endpoint stack,在連線進來時會發布 FLOW_REQ event,而 Bytestream NF 以 FLOW_DEST event 回應告知如何 redirect 這個 flow;Proxy μStack 與 Bytestream NF 皆會使用 DATA_RDY 來表示收到或送出的資料準備好了。
6. Microboxes Implementation
- 建立在 OpenNetVM 這套 NFV 框架上
- 其提供基於 share-memory 的通訊
- NF 各自運行在獨立的 process/container
- IO management layer 可用來啟動、停止 NF
- 透過 NIC 傳送封包
- 作者將專注於 Microboxes TCP stack 與 shared-memory based event communication 系統
- 使用 RSS (Receive Side Scaling) 來避免任何 concurrent update 共享 cache lines,此會降低 cache 命中率。
Stack Modules:
TCP 處理是基於 mOS 的 monitor stack,與部分來自 mTCP 的程式以支援 full endpoint termination。
在 mOS 中改動 5.8k loc,新增 13.5k loc 於作者的 NFV management layer 與範例 NF。
在作者的觀察中,TCP stack 經常會是瓶頸,因此將不必要的處理從 stack 移動到 NF 中。
Shared Memory and TCP state:
- Event Memory
- 儲存封包、event、重組資料流、communication queues
- 支援 NF 與 stack 間零複製移動
- Stack Memory
- 儲存 flow tables(用來維護 per-flow TCP 狀態),像是 seq num、connection status
- 只能透過受限制的 API 存取,以確保所有的狀態資料對 NF 來說都是唯讀
- Stack State Snapshots
- 嵌入在 TCP event message 中,因此 stack 可以持續更新 flow table state 而不用擔心 concurrent 更新的一致性
- snapshot 僅需包含 state table 中可能會被修改的資料,因此約 23 bytes 而已,每次製作平均使用 76 CPU cycles
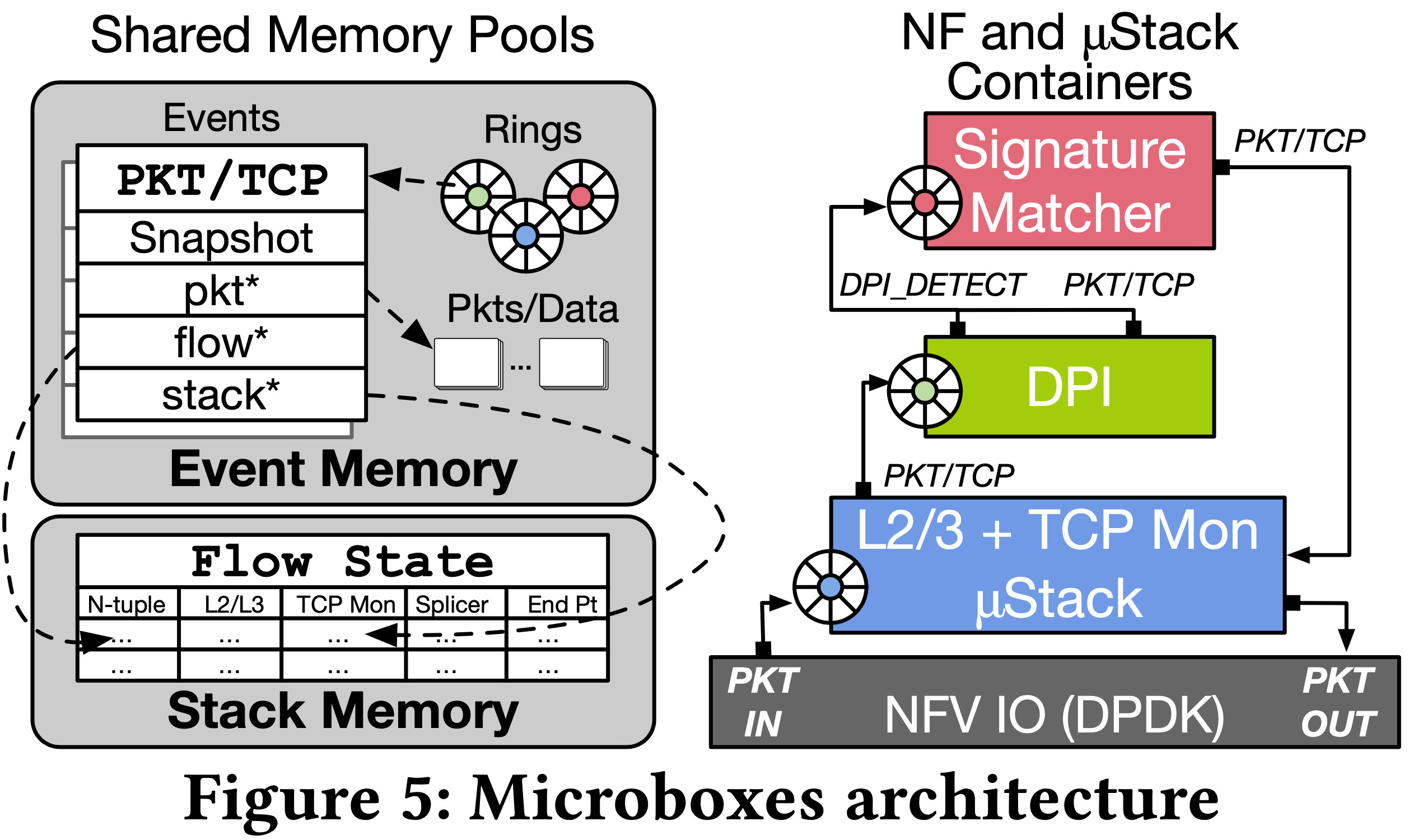
- Event Messages
- 發布者會將 message 存放在 shared Event Memory pool
- Producing NF 會檢查其 subscription list,之後在每個訂閱者的 incoming queue 中加上此 message 的 pointer
- 每個 NF 只有一個 incoming queue,可有多個 output port
- Sample Application
- 將 application 拆成 NF modules,並將部分處理轉移至 stack

7. Evaluation
作者使用 CloudLab 提供的主機來進行測試。
- E5-2660 v3 @ 2.6GHz CPUs (2 * 10 cores)
- RAM: 160 GB
- NIC: Dual-port Intel X520 10Gb
- Ubuntu 14.04, kernel 3.13.0-117-generic
- DPDK v16.11
- Web server: Nginx 1.4.6, Benchmark: Apache Bench 2.3
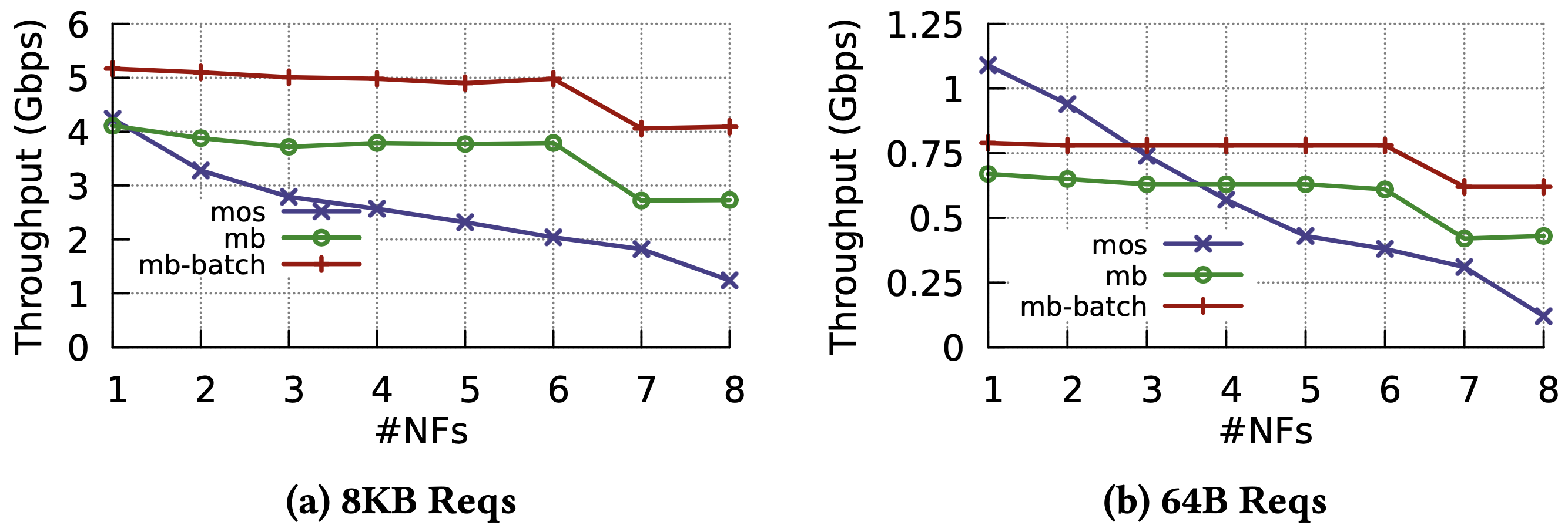
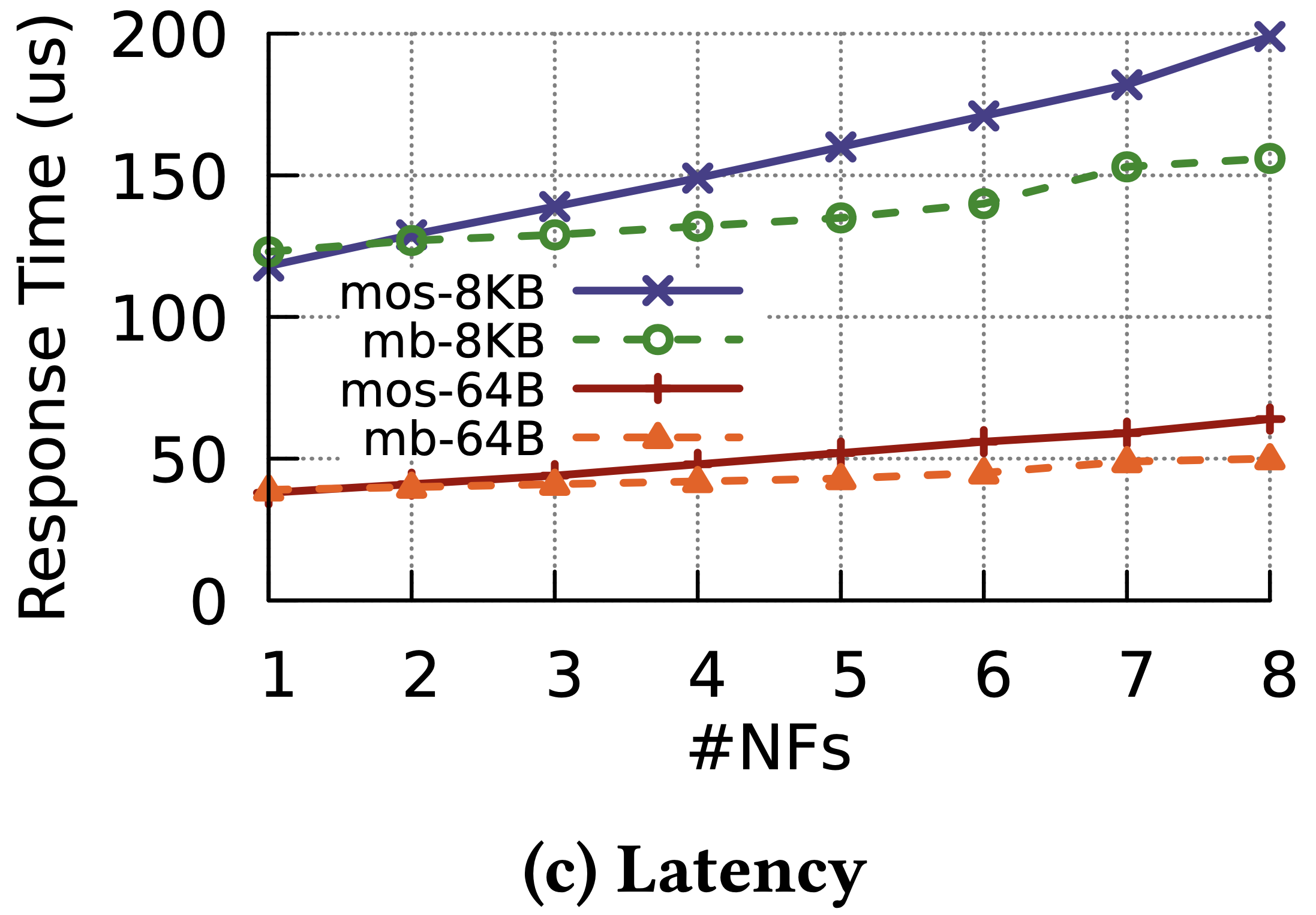
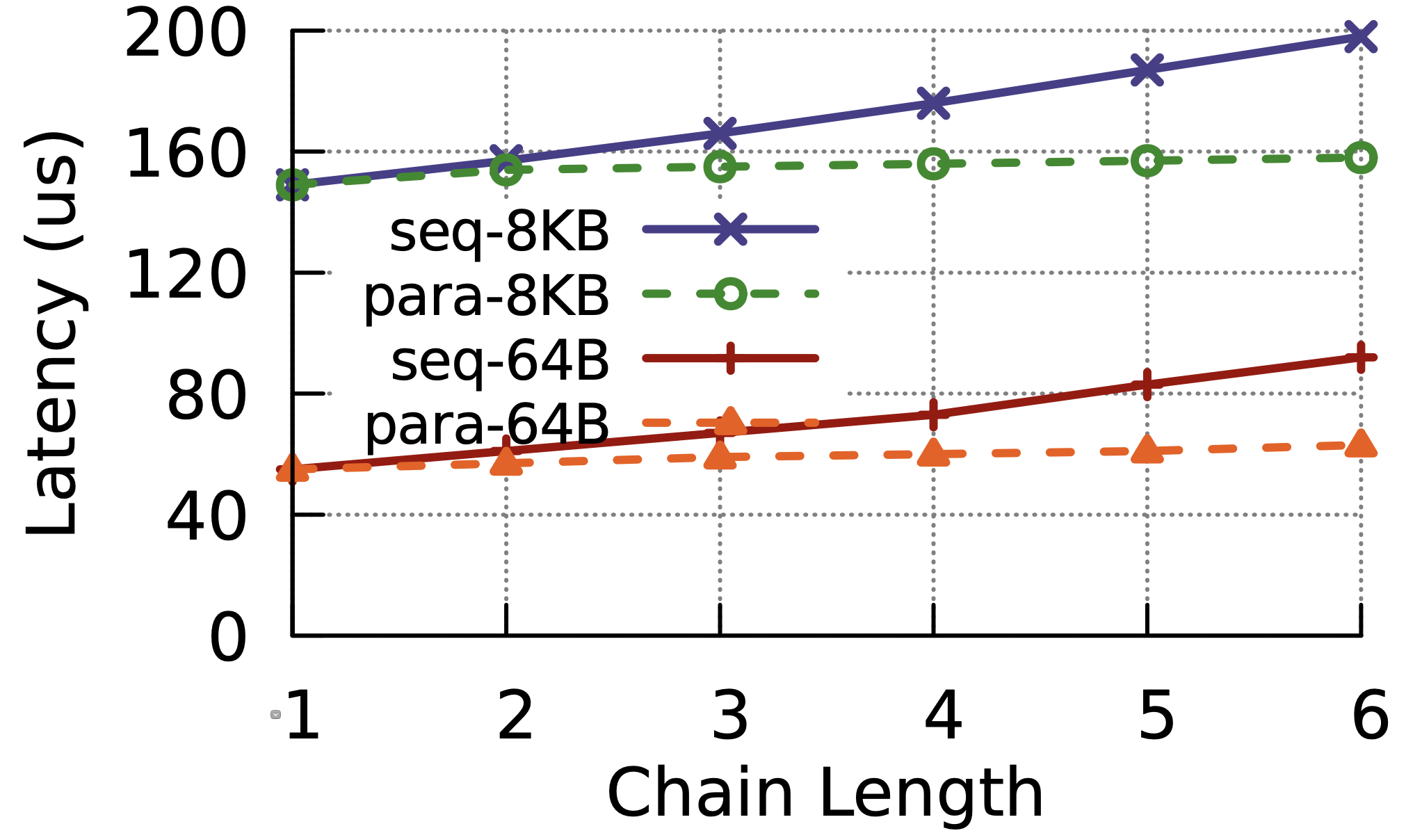
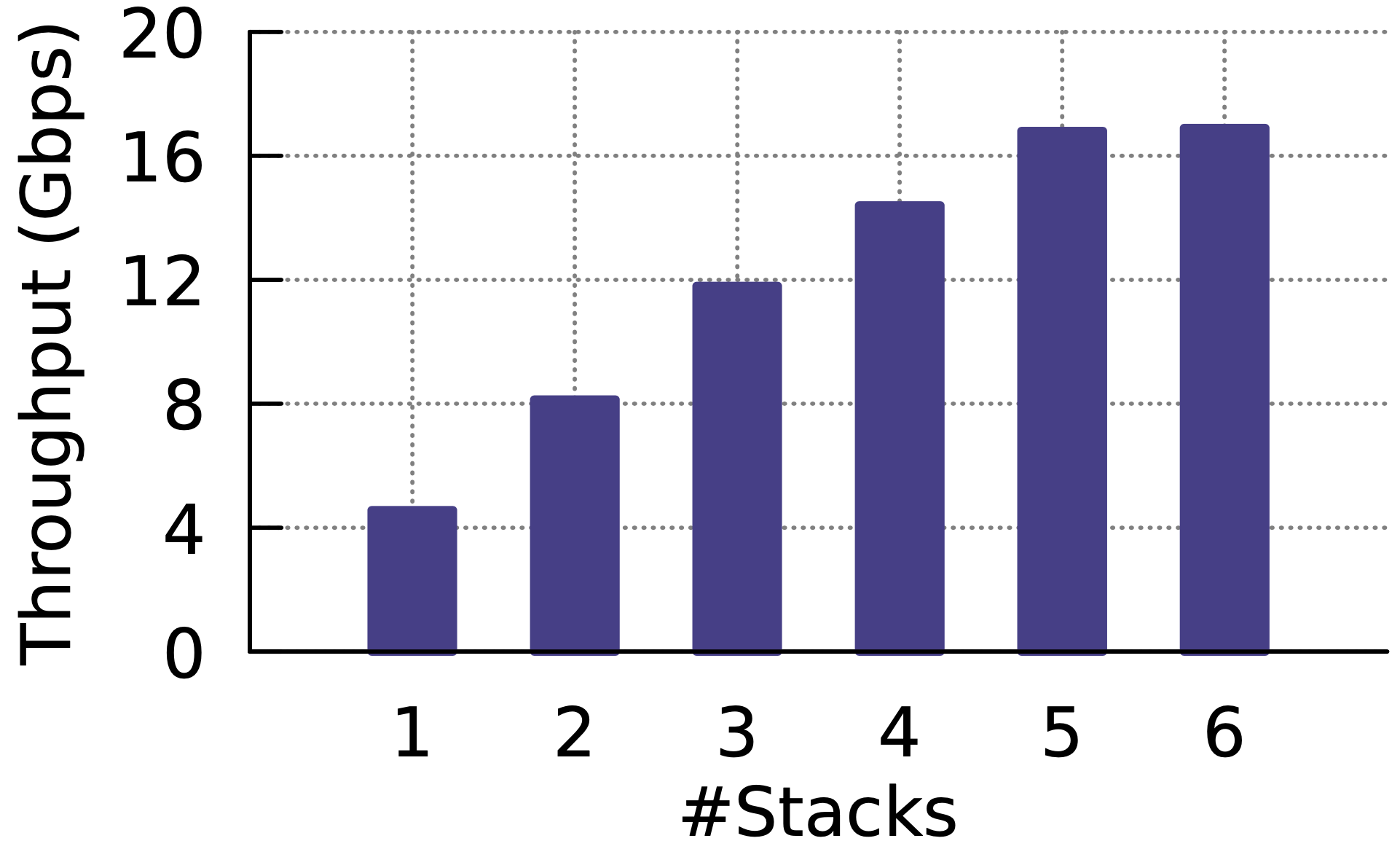
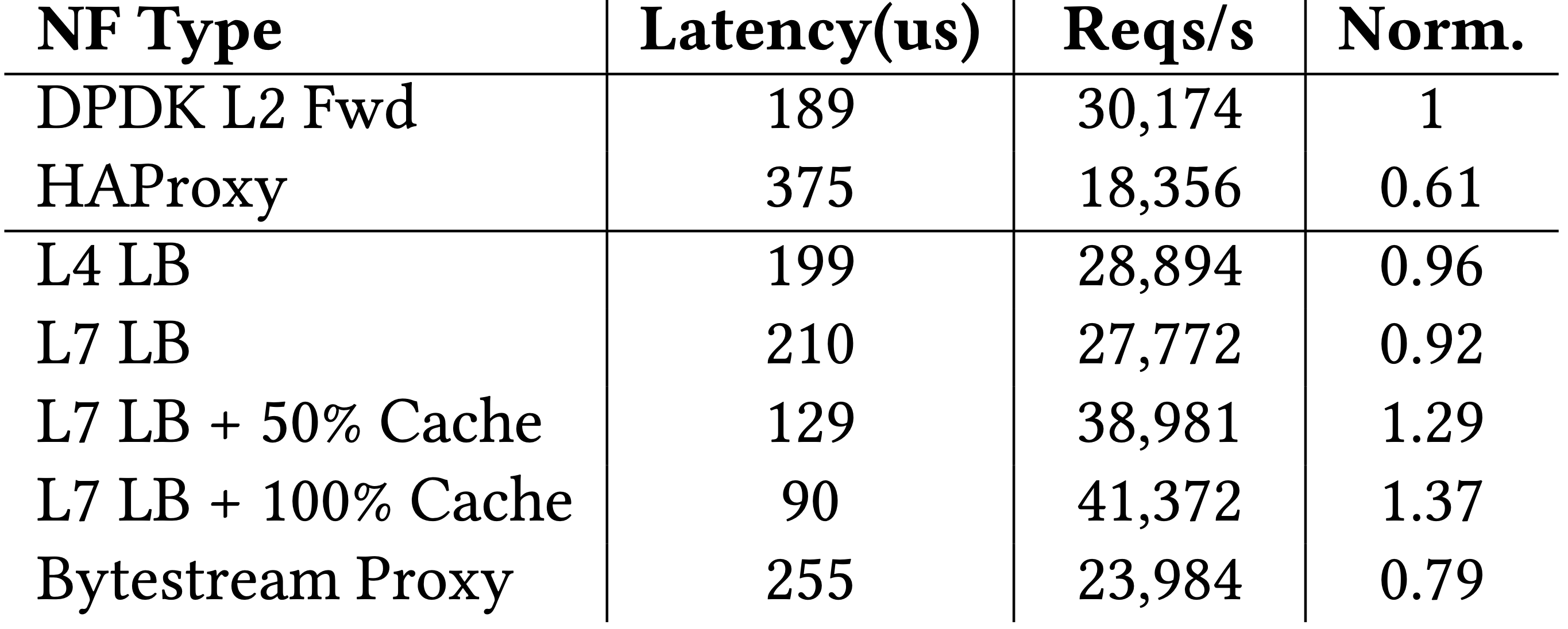
與 HA Proxy 之比較,吞吐量與延遲都有 30% 以上提升。
8. Related Work
作者的 event system 是受到 mOS 與 Bro 中的 user-defined event 啟發。
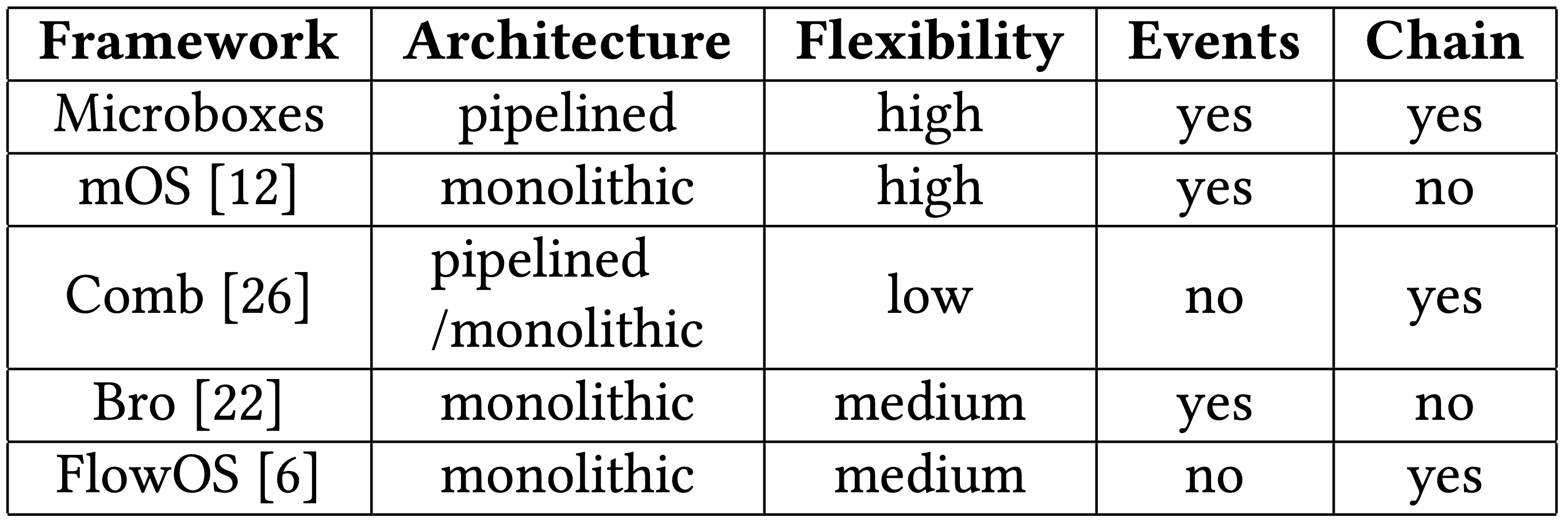
下圖為常見 NFV 框架比較表:
名詞解釋
TCP byte stream reconstruction
TCP 封包是以 byte 方式傳送,本身又是資料流,有鑒於 MTU 上限緣故單一封包可乘載的 payload 大小(MSS)約只有 1460 bytes(1518 - Ethernet header 18 - IP header 20 - TCP header 20)。
因此過大的傳送資料都會被分段處理,接收時自然得將這些資料重組起來。
TCP splicing
這技術能夠將 TCP 封包內容重組起來,通常是在網路中間設備使用,如 Web Proxy,因為他們得蒐集到完成的資訊才能做下一步的動作,如分析、壓縮、轉傳等等。
延伸閱讀:SOCKMAP - TCP splicing of the future
TCP Split Proxy
Performance-enhancing proxy (PEP) 是為了解決一些端對端協定效能表現的網路代理人(network agent),在 RFC 3135 、RFC 3449 中有規範。
實作方法可分為:
- Proxy type
- 可以是 split 或 snoop
- Distributtion
- Symmetry
種類:
- Split-TCP
- 為了解決 TCP round-trip 延遲,典型的用法是在衛星通訊(window size 太小問題)
- 透過將兩個端點間切成數段連線,並使用不同的參數來傳送,而終端系統使用舊有 TCP 方法即可連線
- Ack decimation
- Snoop
- D-proxy
參考:Performance-enhancing proxy
TCP Offload Engine
為一項用於網卡的技術,可以幫忙 CPU 分擔封包 TCP header 處理的負載。
習慣上,會將 TOE 稱作網卡,雖然這技術只是在網卡上的一塊晶片。
參考:Wikipedia
Append-only
一種計算機儲存的屬性,現有檔案不可修改,只能將新資料修改另外追加到儲存中,這種方式會佔用較多儲存空間。
因為編輯檔案開銷很高,甚至可能需要重寫整份檔案,Redis、Hadoop 等講求效能的應用會採用 Append-only 方式來額外寫入每次修改的部分,並可以在合適的時間對檔案進行重寫以節省空間。
參考:
Receive Side Scaling (RSS)
一種在網卡上的技術,使用 hash 技術(n-tuple 之類的)將封包分配到多個 CPU 上處理,同個 flow 會盡量安排到同一顆核心以增加快取命中率。
參考:
comments powered by Disqus