概要
作者提出一套用於 NFs 的效能診斷工具——Microscope,透過線上統計、離線分析每個 NF 佇列,可以找到出問題的 NF 和資料流,縱使問題發生當下與原因有著時間間隔、問題會透過 VNF chain 傳播,也難不倒這套工具。
其比較的對象是微軟在 2009 年發表在 SIGCOMM 的 NetMedic 工具,在準確率方面有著 2.5 倍的顯著提升,因為此作品是首個能夠以微秒等級來觀察分析,找到了許多之前不能發現的問題。
1. 介紹
由於 NFV 是軟體驅動,難免遇到吞吐量不穩定、long tail latency、jitter 等問題,這對 SLA 有著不容小覷的影響。
當遇到這些問題時,使用者、ISP、NFV 供應商就會開始互相踢皮球(blame game),因為:
- 效能問題的發生時常是間歇性的,不容易掌握
- 沒有人對所有設備系統是有完整的控制權
舉個例子來說:
NF chain 為 Firewall → VPN,當 VPN 有部分封包發生高延遲時,營運商可能會懷疑是 VPN 出問題,但到最後才發現移除掉 Firewall 就沒事了,問題原來是出在 Firewall。 有時候突發流量(bursty traffic)會造成 Firewall 的佇列(queue)產生,進而導致高延遲發生。但這次原因不是這個,而是 Firewall 有個 bug 導致處理時間大幅增加!
真實世界的情況肯定會更加複雜。每個 VNF 都有可能會發生 interrupt、cache miss、context switch 事件,這些皆會造成間歇性的效能影響,且會接連影響到往後的 NF 運作。
在作者提出的 Microscope 中,可在 DAG 環境中調查出問題 NFs 的因果關係,如:
- 錯誤配置、bugs
- 異常流量
- 系統中斷(interrupt)
- 負載平衡
現有的工具如 NetMedic 雖號稱可以診斷網路問題,其方法是監控相同時間區間(time windows) 資源利用率、處理速率、問題(例如高延遲)。
但現實網路中的問題如 traffic burst、queuing 所影響的時間會較長:
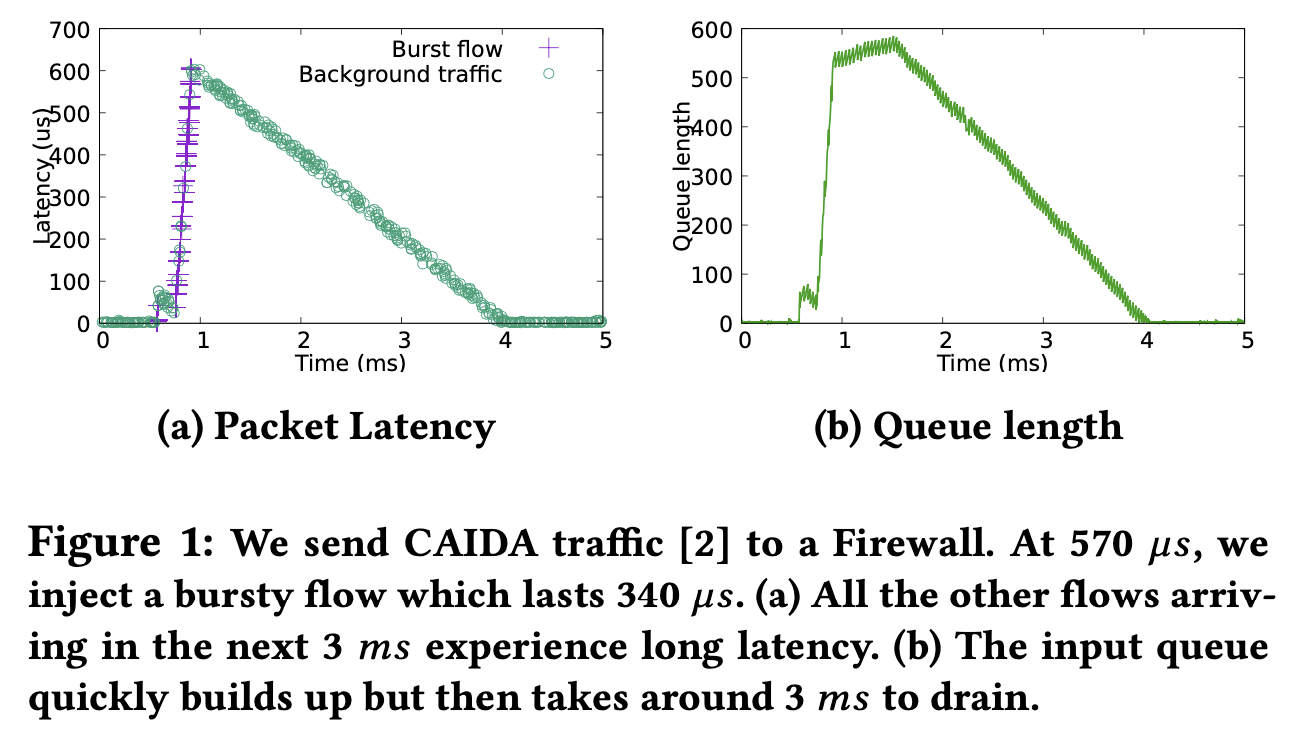
由此可見上游 NF 的問題容易影響下游 NF,且持續一段時間,因此難以定義合適的 time window 大小來進行分析。
Microscope 會直接針對每個 NF 的 queue 做監控側錄,並在離線時分析(因為會花很多時間),藉此找出問題的因果關係。
2. 動機
前人的作品都是基於相同的 time window 進行分析,並無法有效解決上述問題。
2.1 挑戰與 NF 診斷
Microsecond 等級的影響
§1 的圖片說明了:
就算某個流只出現極短暫的時間,但其造成的影響卻持續了很久。
原因除了 traffic burst,也可能會是 interrupt, context switch 等造成的。
所造成衝擊的大小取決於:
- 資源競爭嚴重性
- 當前流量
- NF 的處理速率
因此更加難以定義合適的 time window 大小,過小則會錯失許多相關的行為,過大則會包含太多不重要的行為。
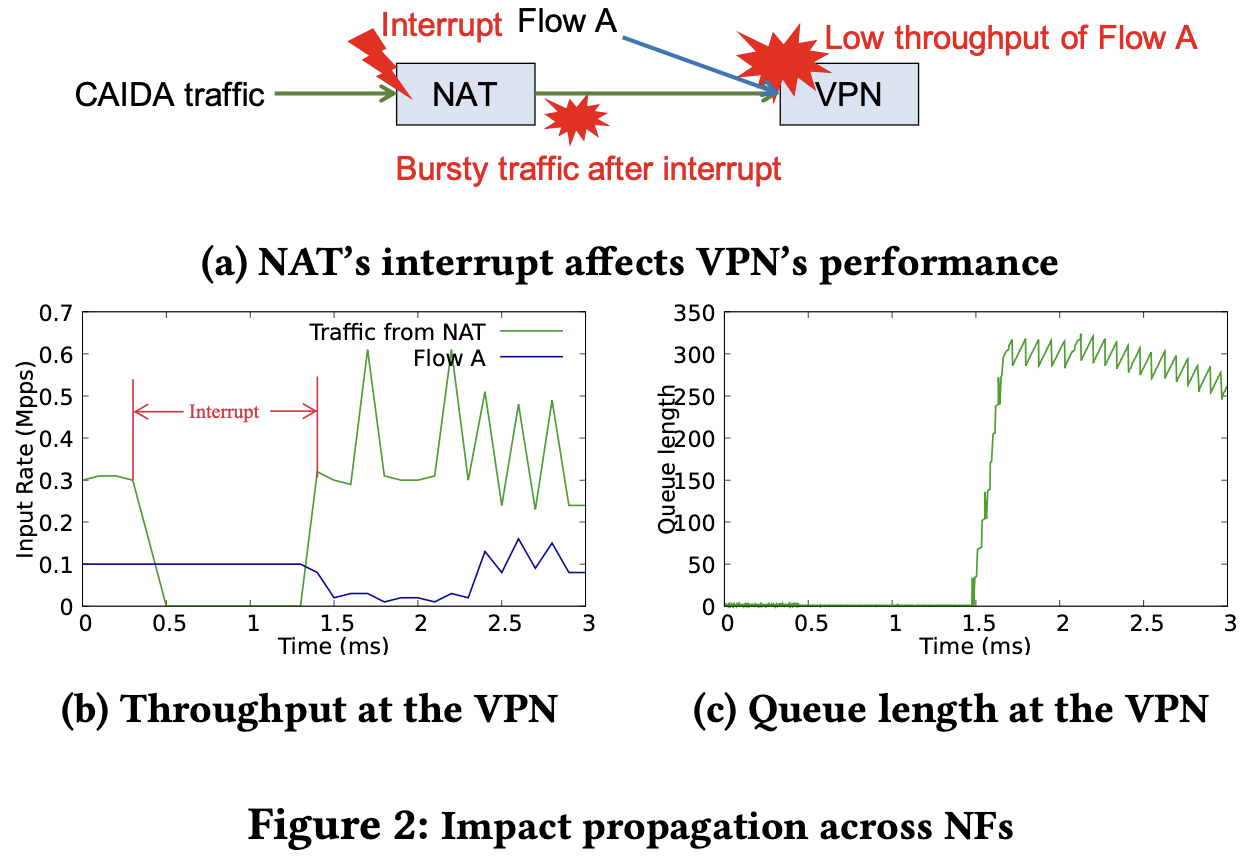
跨越多個 NF 的影響
下圖中 VPN 同時接收兩個流,不過 NAT 有段時間遭遇了 interrupt 因此暫時無法處理封包。
當 interrupt 處理完後,由於 queue 中有大量的封包,一次處理完丟給 VPN 造成 burst 現象,就換成 VPN 的 queue 快速累積,造成 Flow A 的處理也受到影響而吞吐量下降。
這時候從 Flow A 到達 VPN 的封包,雖然時間上跟 interrupt 沒有重疊,但也受到影響!
實務上來說,影響效能的關鍵有兩個:
- NF、流量源頭的異常
- Queue 的佔用率
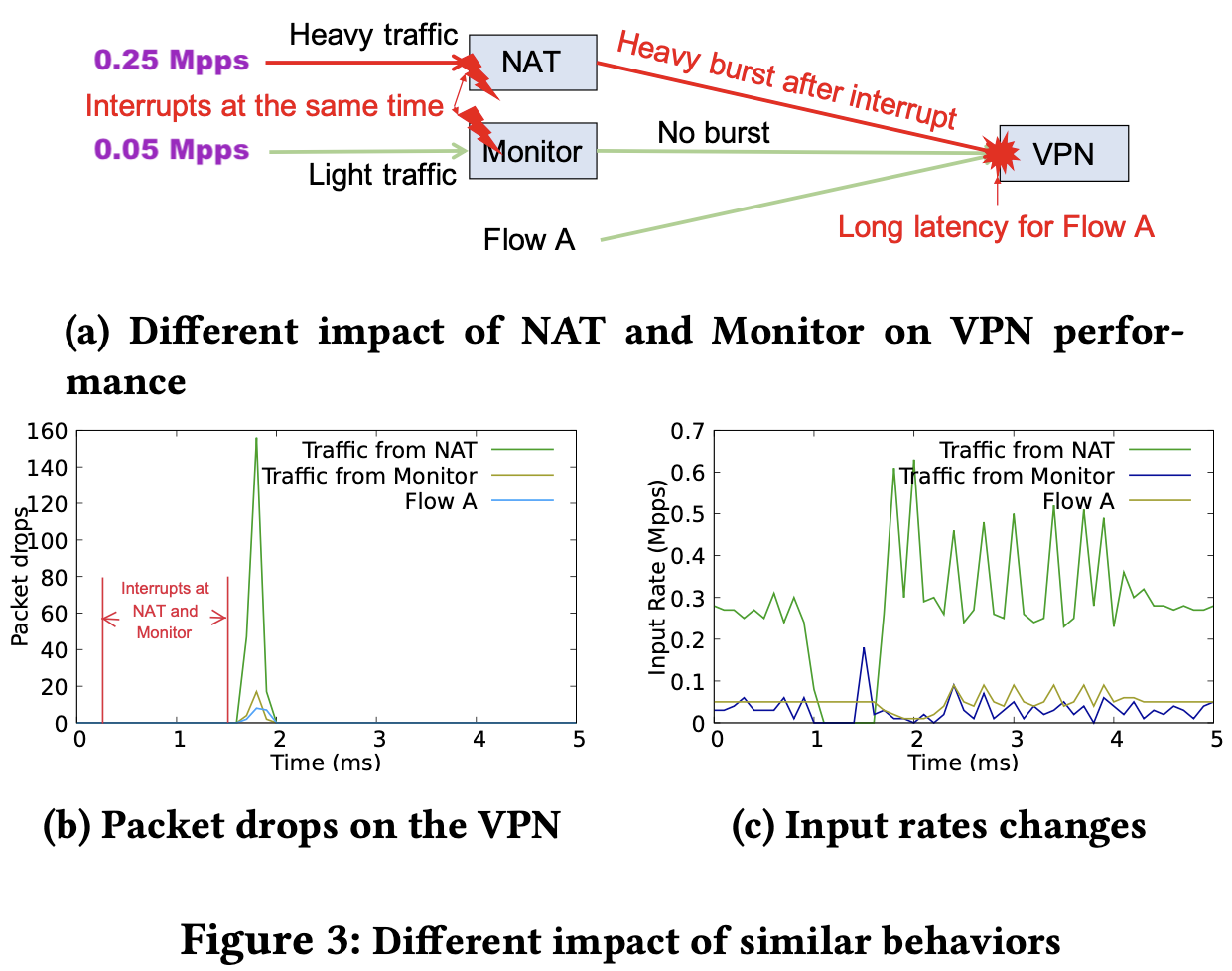
類似行為卻有不同的影響
- NAT 流量 0.25 Mpps
- Monitor 流量 0.05 Mpps
當 NAT 與 Monitor 發生 interrupt 後,造成三種流量都有掉包的發生,但因為兩者皆有發生 interrupt,難以知道兇手是誰。為了咎責找出元兇,可以參考 3 (c) 的圖片,明顯的是 NAT 瞬間多了很多流量。
作者希望能將此過程量化!
2.2 效能診斷問卷
為了瞭解真實世界中的問題與診斷,作者在 2020/01 時詢問了 19 間網路營運商(包含 ISP、資料中心、企業),其問卷在此。其中有 4 間小型網路(< 1K hosts)、6 間中型網路(1~10K hosts)、4 間大型網路(10~100K hosts)、5 間超大型網路(> 100K hosts)。
調查結果顯示,有 5 間業者每月需調查 10~100 件效能問題,其中 4 間每月費時超過 12 小時。
其常見情況包含:
- 低吞吐量
- 間歇性發生的
- 單一使用者才有的問題
其問題原因為:
- 資源競爭(7 operators)
- traffic bursts(12 operators)
- interrupts(5 operators)
- NF bugs(15 operators)
- NF 相互影響
- 上游 NF 流量造成(6 operators)
- 錯誤配置(8 operators)
- 資源競爭(3 operators)
對診斷工具迫切所需的功能為:
- Ranked list of root causes (12 operators)
- Low overhead (12 operators)
- High accuracy (9 operators)
- Aggregated flows of each cause (7 operators)
3. 核心想法
利用佇列期間來了解每個 NF 的持久性問題
由於 NF 是由各家不同廠商所設計,我們無法取得其程式碼,因此作者打算透過 queue 來探討問題發生的原因。從 §2 中我們知道先前的封包可能會影響後來的封包,因此作者定義一個名詞 queuing period,表示 queue 的形成開始(0 封包)到目前這段時間,藉此判斷問題發生時間跟曾在 queue 中的封包有沒有重疊的時間,避免漏網之魚封包早已被處理完而找不到原因。
透過 queuing period 中的封包來量化因果關係
一般來說封包在 queue 中的原因有兩種:
- 進來的封包太多
- NF 處理太慢
作者會調查進入封包速率、峰值處理速率,來決定哪個才是根本問題。
總體因果模式(aggregate causal patterns)
作者利用此演算法來產生問題排名分數清單,其魔改了 AutoFocus 演算法,讓它蒐集因果模式而不是 traffic clusters,清單原型如下:
$$\text {<culprit flow aggregates, culprit NF>} \rightarrow \text {<victim flow aggregate, victim NF>}: score$$
4. Microscope 設計
Microscope 僅收集每個封包的 timestamp、NF 間的 queuing 與 flow 狀態,而不存取 NF 內部程式碼。
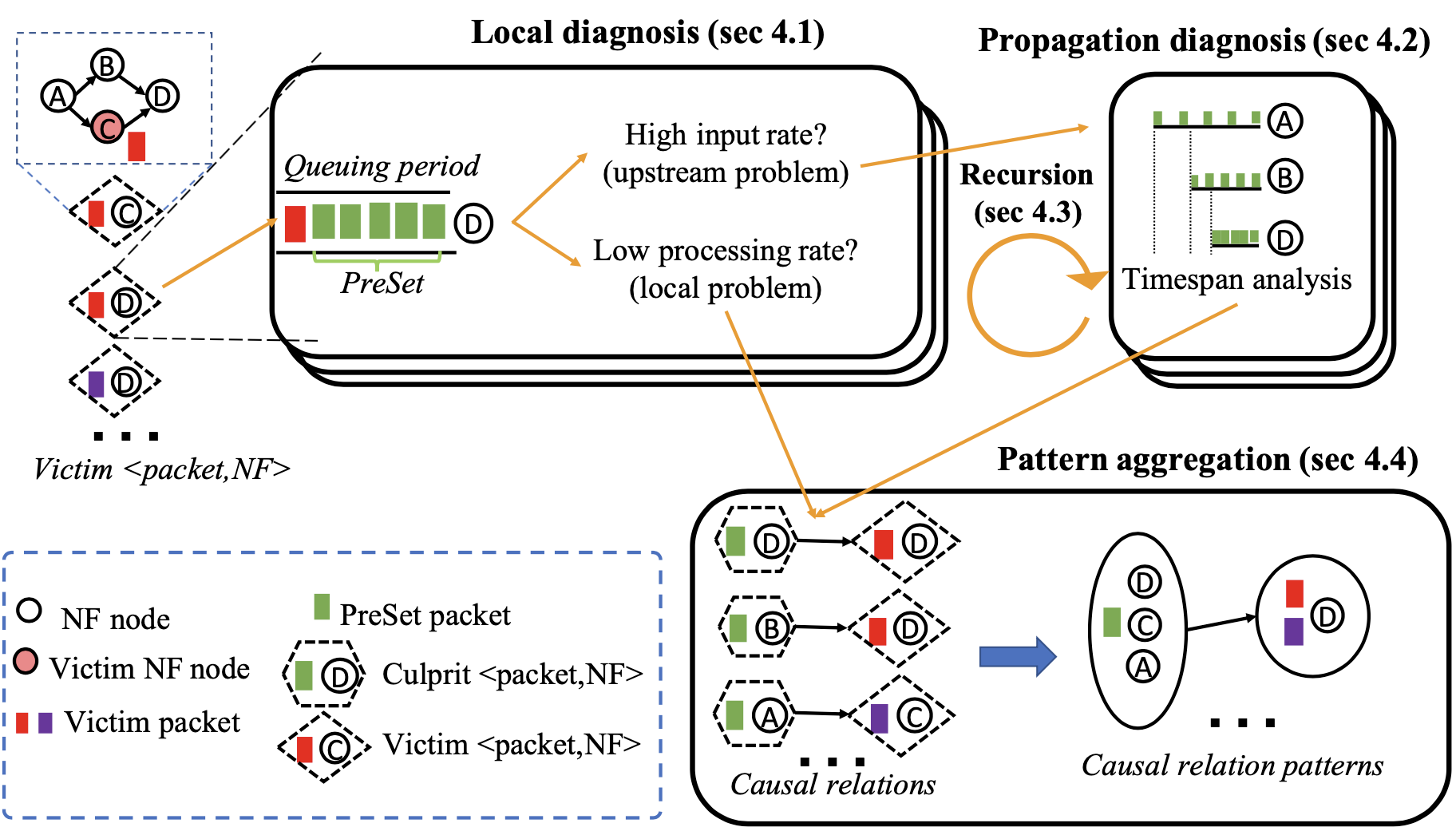
當收集完必要資訊後,Microscope 會進行離線分析:
- 對 NF 中每個 victim packet(遭遇高延遲、低吞吐量、掉包)進行 local diagnosis,以確認原因是在 local 還是上游 NF。§4.1
- 觀察 queuing period,看問題是低處理量(local)還是 high input rate(上游 NFs)
- 如果是因為 high input rate,那就進行 propagation analysis 以識別上游 NFs。§4.2
- 檢查 queuing period 的封包(也就是 Preset packets),並且分析每個 NF 中封包 timespan 的變化
- 如果該 NF 造成了 high input rate,其也很可能遭受到了效能問題,因此進行 recursively diagnoses,也就是第 (1)、(2) 步。§4.3
- 進行 aggregates causal relations,彙整並列出 culprit 到 victim 間的封包與 NF 資訊。§4.4
- 使用了 AutoFocus 演算法
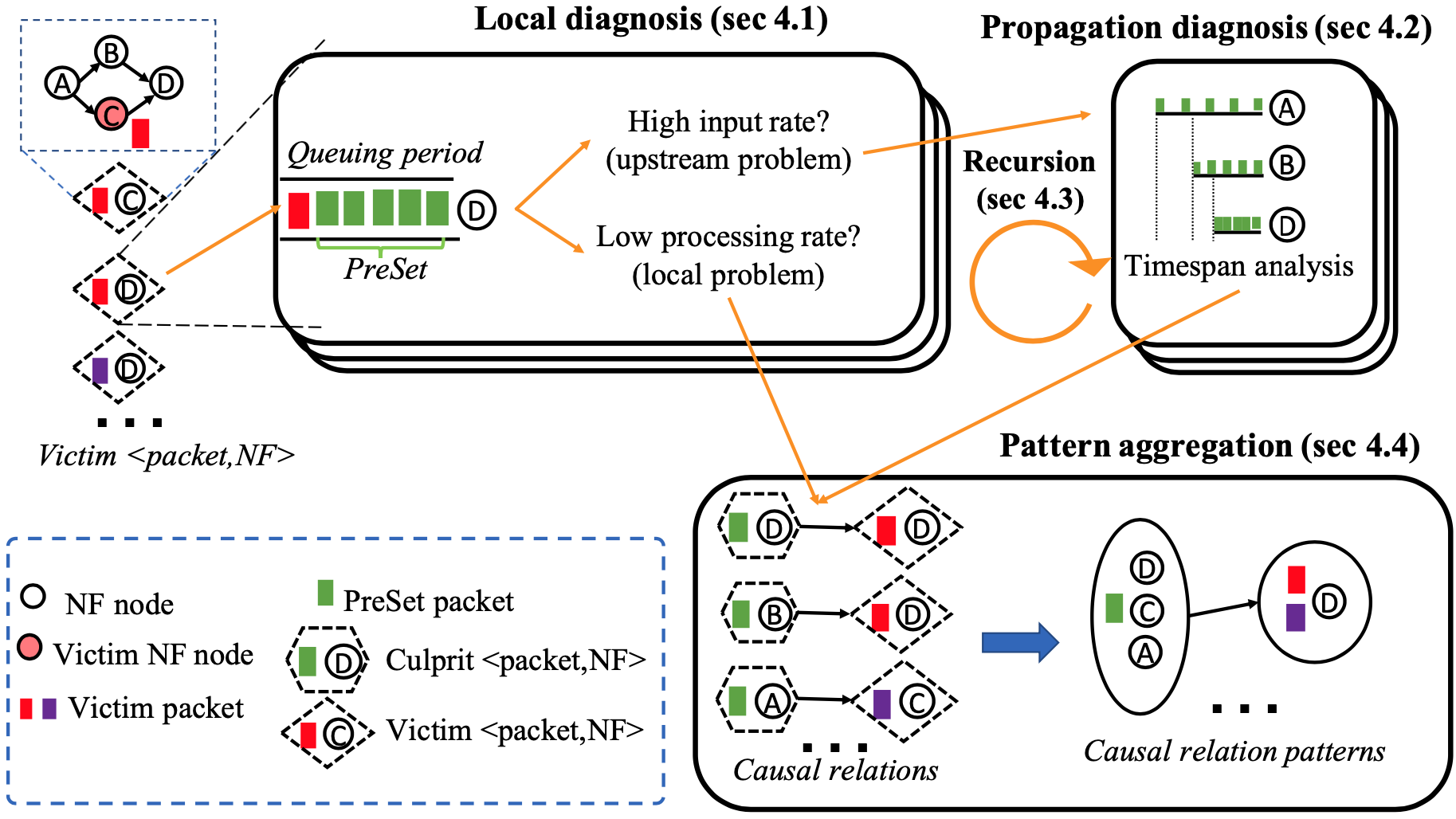
4.1 Local Diagnosis
作者聚焦在效能表現差(像是高延遲、低吞吐量)或是掉包的 victim packets。
為了找出異常的 NF ,該框架觀察路徑上每個 NF 的表現,並且如同 NetMedic 一樣定義 NF 的效能與過往歷史有一個標準差以上的差距即為異常。
當 victim packet $p$ 在 NF $f$ 時有異常的效能表現,作者會去探討是 $f$ 有異常行為或是其上游的 NFs;其中這些異常行為的發生時間並不一定會跟 $p$ 有重疊(也就是可能異常後過一段時間才造成效能影響),這部分晚點會說明。
造成封包 $p$ 高延遲的直接原因是「在這之前到達 $f$ 的封包佇列」所造成的,佇列時間是從第一個封包 enqueue 開始算,直到 $p$ 到達為止。因此為了找出兇手,Microscope 必須得知道整個 queue 的歷史資訊。
造成佇列的發生不外乎兩個原因:
- 大量的封包進入
- 低落的封包處理效能
為了表示這些關係,用了一些符號來解釋:
- $f$:NF
- $T$:某 NF 佇列出現的時間長度
- $n_i(T)$:在 $T$ 時間內到達的封包量
- $n_p(T)$:在 $T$ 時間內被處理的封包量
- $r_i$:NF 的峰值效能處理量(在相同軟硬體下)
- $S^f_i$:在最佳效能下($r_i$)無法消化造成累積在佇列的封包量(輸入負載分數)
$$S_{i}^{f}=\left{\begin{array}{cl}n_{i}(T)-r_{i} \cdot T & \text { if } n_{i}(T) \geqslant r_{i} \cdot T \ 0 & \text { if } n_{i}(T)<r_{i} \cdot T\end{array}\right.$$
- $S^f_p$:實際處理的量比預期的少多少(處理分數)
$$S_{p}^{f}=\left{\begin{array}{ll}r_{i} \cdot T-n_{p}(T) & \text { if } n_{i}(T) \geqslant r_{i} \cdot T \ n_{i}(T)-n_{p}(T) & \text { if } n_{i}(T)<r_{i} \cdot T\end{array}\right.$$
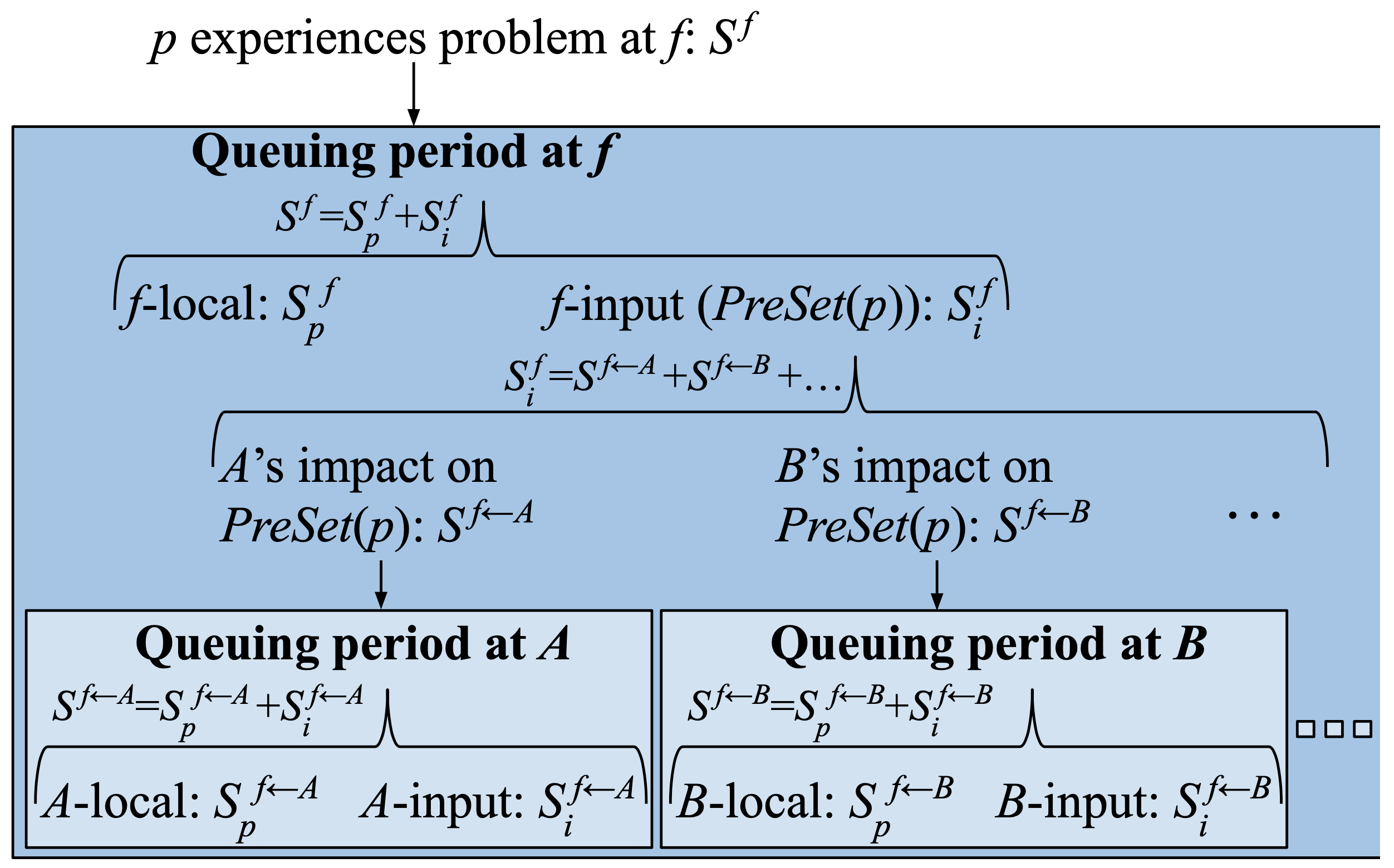
因此可以用 $S^f_i$ 與 $S^f_p$ 來表示在時間 $T$ 中,所有造成佇列形成的封包:
$$S^f_i + S^f_p = n_i - n_p$$
其中 $n_i - n_p$ 也就是佇列的長度。
4.2 Propagation Diagnosis
假設我們分析到 $S^f_i$ 是正的,代表輸入的量已經高於峰值處理量,勢必會導致佇列的累積,這時的原因可能為:
- 上游 NF 忽然大幅增加封包處理量
- 流量來源本身
這個章節會討論找出 NFs 間因果關係的「傳輸分析演算法」。
先來點名詞定義:
- $PreSet(p)$:當封包 $p$ 到達 NF $f$ 時,其佇列已經持續了 $T$ 時間;在 $n_i(T)$ 累積的過程中,所有參與封包的統稱
- $timespan$ of $PreSet(p)$:在 $PreSet(p)$ 中「第一個」與「最後一個」離開該 NF 的封包時間差
- $T_{source}, T_{A}, T_{B}$:在 source、NF A、NF B 的 timespan
當前目標是理解 $PreSet(p)$ 的歷史,與為何這些封包在 $f$ 花費了 $T$ 時間。首先會討論 $PreSet(p)$ 遍歷單條 VNF chain 的情況,接著推廣到 DAG 的情況。
遍歷單條 VNF chain
假設 $PreSet(p)$ 會遍歷 A→B→C→$f$:(參考下圖)
- 在 A 遇到 interrupt 需等待,之後封包們緊湊(back-to-back)的被處理
- 封包間時間間隔被壓縮,相較於 $T_{source}$,$T_A$ 的 timespan 被壓縮了
- 在 B 的處理時間較長,因此 $T_B$ 相較之下增加了
- 在 C 遇到其他流量封包(cross traffic)的佇列需等待,因此 $Tc$ 被壓縮了
- 這是變項對 $f$ 造成突發(bursty)封包,因為 $f$ 無法在 $T_C$ 時間內處理完,進而影響到封包 $p$
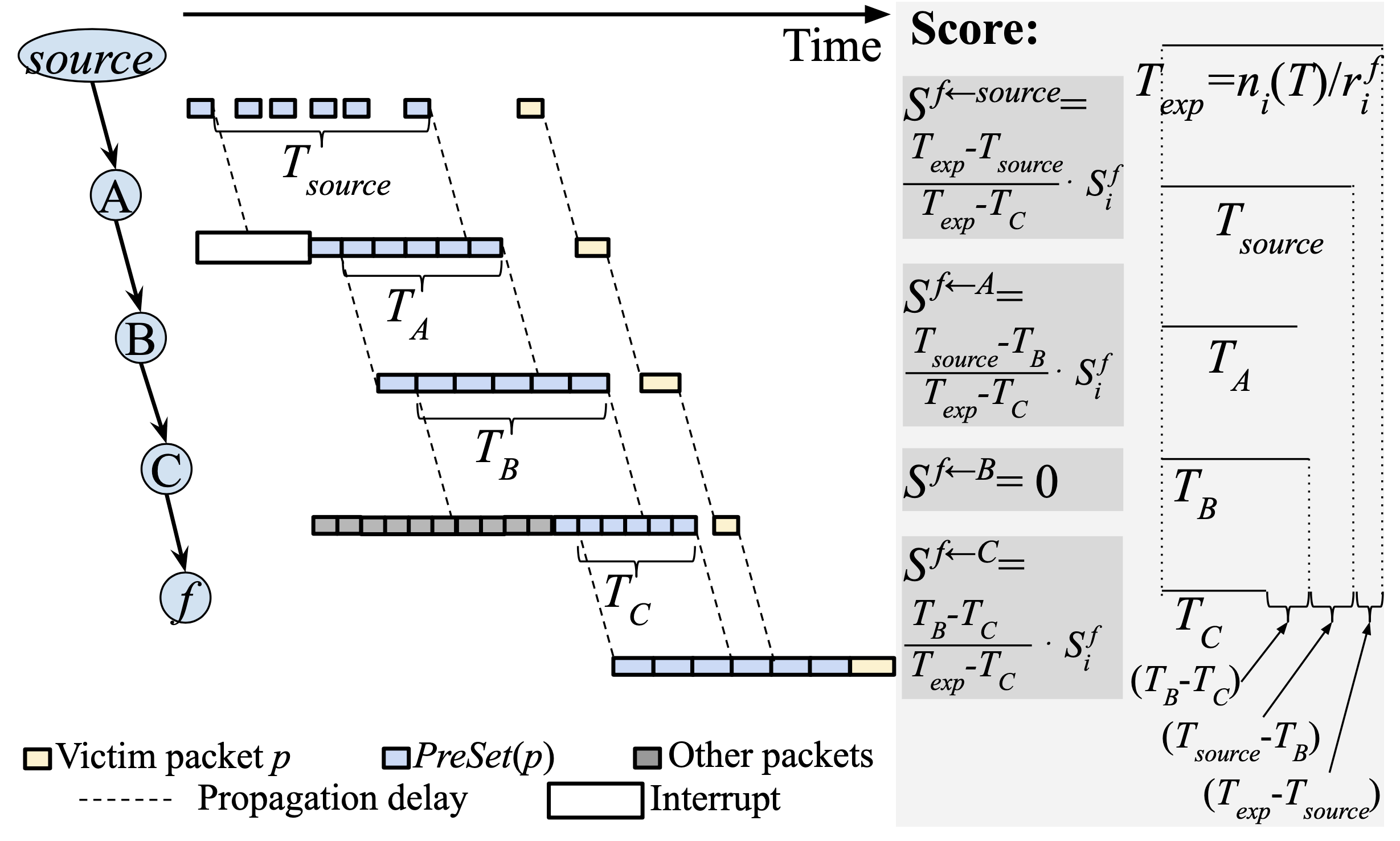
這邊作者只關注整體 timespan 而不是封包在上游 NFs 的分布狀況,因為結果都一樣,且 timespan 也比較好在不同 NF 中分析比較。
接著要來抓戰犯了,$f$ 的預期 timespan 為 $T_{exp} = n_i(T)/r^f_i$,我們知道 $T_C < T_{exp}$ 是造成突發封包的主因,那麼作者就將其所減少的 timespan $(T_{exp} - T_C)$ 做比例肇責分配,看看誰的 $S^f$ 分數高, 誰就是真戰犯:
- 對 C 而言,因為從 $T_B$ 減少了一些 timespan:
$$S^{f \leftarrow C} = \frac{T_B-T_C}{T_{exp}-T_C} \cdot S^f_i$$
- 對 source 而言,其減少了 $T_{exp} - T_{source}$
- (如果其值 > 0,表示從源頭開始就送的太急了)
$$S^{f \leftarrow source} = \frac{T_{exp} - T_{source}}{T_{exp}-T_C} \cdot S^f_i$$
- 對 A 而言,其減少了 $T_{source} - T_B$,因為 B 相對於 A 是增長的
$$S^{f \leftarrow A} = \frac{T_{source}-T_B}{T_{exp}-T_C}$$
- 對 B 而言,因為相對於 A 是增長的,因此肇責為 0
遍歷 DAG NF(多條路徑)
- $PreSetPath(p)$:從 source 到 $f$ 間是 DAG 的話,$PreSet(p)$ 所有經過路徑的集合
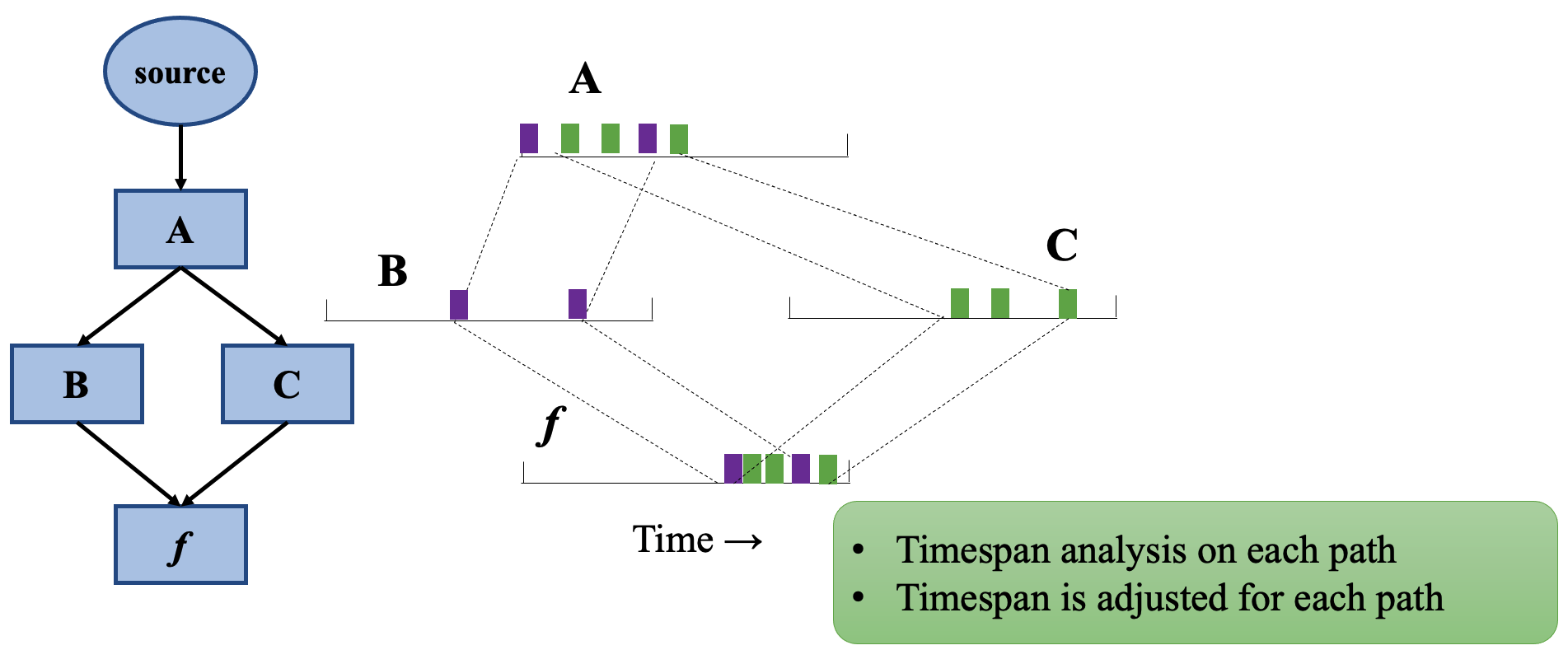
當 $PreSet(p)$ 中的封包經過 DAG 時,這邊只考慮其封包所經過的部分,以上圖來說紫色和綠色只有經過 B、C 兩個節點。
從 VNF chain 的遍歷推廣到 DAG NF 時,最大的問題是「如何設定每條路徑的預期 timespan?」。
雖然在「每條路徑上的封包量必定 ≤ $PreSet(p)$ 的封包」,但是這並不代表所預期的 timespan 會比較小,這是因為封包在不同路徑上經常是會交錯經過(interleave)的。
當封包是完全交錯(fully interleave)
- 那麼 timespan 就會跟 $PreSet(p)$ 相同為 $n_i(T)/r^f_i = T_{exp}$
當封包不是完全交錯
- 那麼 timespan ≤ $T_{exp}$
- 也就代表或有一條或多條路徑較為突發(也就可能是戰犯)
編按:為何可能是戰犯?
總結來說,在最佳的情況下,每條路徑的 $T_{exp}$ 都要等於 $ni(T)/r^f_i$ 會比較好。
編按:為何要等於比較好?
每個 NF 都有可能會有多項分數,因為一條路徑就會有一個分數。那麼這些分數該怎麼合併呢?
- 單純的加總起來不可行
- 原因為多條路徑可能會聚在某個 NF 上,timespan 加總就很可能超過 $S^f_i$
- 按比例縮小所有分數
編按:怎麼按比例縮小?
4.3 遞迴診斷 PreSet 封包
為了量化分析,作者遞迴地執行 §4.1、§4.2 的操作來檢驗佇列(如 4.2 圖中的 other packets)。
遞迴示意圖如下,停止條件有兩個:
- 到達 source
- NF 的 $S_i$ 值都不是正的
用 §1 的範例來舉例的話,想知道為何 Firewall 會壓縮 timespan 造成佇列的形成,可以發現 $S^{VPN \leftarrow FW}_p >0$,也就是處理速度太慢啦。
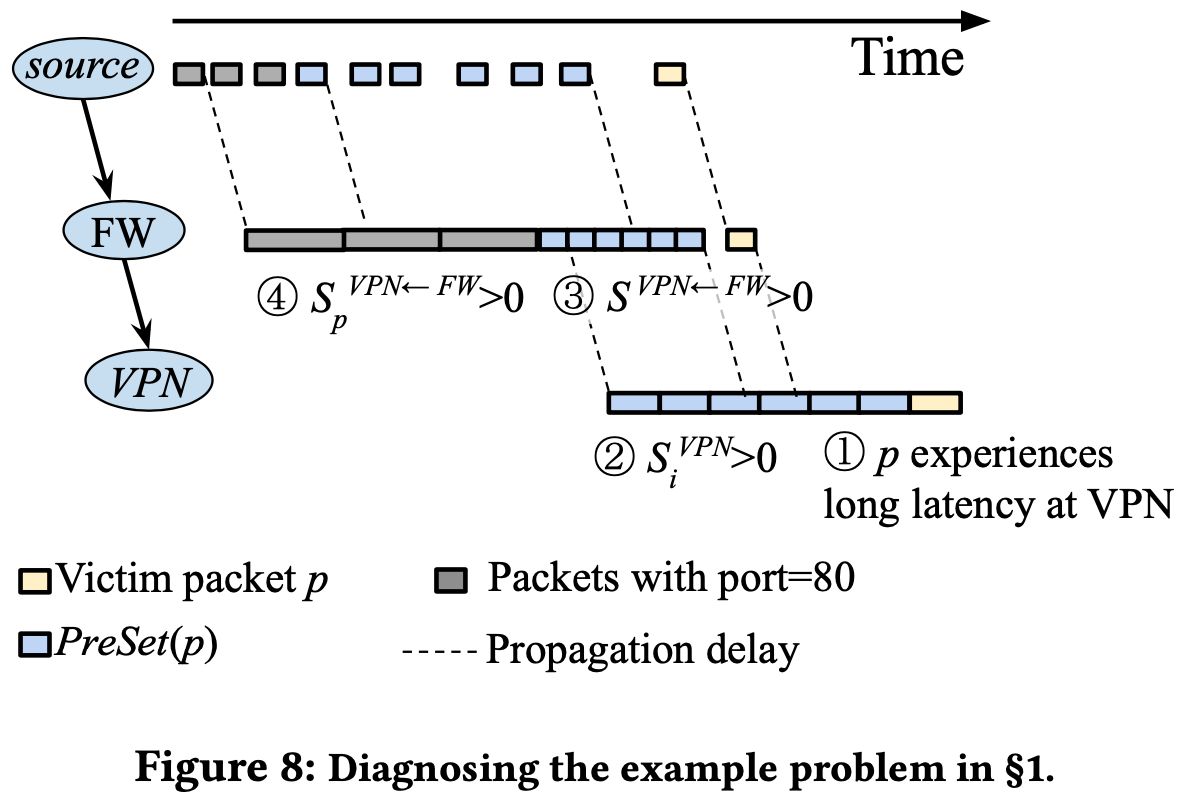
作者將這些戰犯封包稱為 “culprit packets”,下一節(§4.4)會提到如何使用特徵 pattern aggregation 來找出哪條 flow 造成此問題。
4.4 Pattern Aggregation
有了 packet-level 的因果關係後,接著是要將其模式分類,以利營運商採去後續行動。像是如果能縮小問題範圍,進而找到特定 NF 出包,那就能請該廠商調查修正。
首先對於每次找到 culprit packets 後,採用下面的形式當作輸入:
$$\text {<culprit packets, culprit NF>} \rightarrow \text {<victim packet, victim NF>}: score$$
接著產生 aggregate patterns:
$$\text {<culprit flow aggregates, culprit NF set>} \rightarrow \text {<victim flow aggregates, victim NF set>}: score$$
其中
- flow aggregates 包含
- source IP prefix
- source port range
- destination IP prefix
- destination port range
- protocol set
- NF set 包含
- NFs
- traffic sources
有了 aggregate pattern 後,接著找出貢獻分數最多的幾個,
作者個 pattern aggregation 問題有點像是 AutoFocus 中提到的自動分類 multi-dimensional 流量。只是作者的目標是找出包含 culprit flow aggregate、culprit NF set、victim packet、victim NF set。在排除掉這些 aggregate 的後繼者後,透過閾值 $th$ 找出貢獻較多分數的 significant pattern aggregates,這邊的 $th$ 如果設大一點那麼回報的資料就會比較少。
編按:後繼者是指後面的 NF 嗎?
目前面臨到的關鍵挑戰是這些搜尋規則(dimension 的量)遠高於 traffic aggregation,為了加速 aggregation 的執行,作者利用了 culprit packets/NFs 與 victim packets/NFs 的優勢,在大多數時候的 significant pattern aggregates 中, culprit flow aggregate 也會是 significant flow aggregate,相同的道理也可以套用到 victim flow aggregates 上。這是因為一個 victim packet 是由一組有限的封包影響,而 culprit packet set 影響了有限的 victim packets。
編按:這是在講說相對於檢查所有封包,只看佇列那些封包會比較容易的意思嗎?
Pattern aggregation 演算法分為三步驟:
- 將 culprit packets 與 culprit NF 分類。對每個 $\text {<culprit packet, culprit NF>}$,作者運行 AutoFocus 在 $\text {<victim packet, victim NF>}$ 上,產出一些有 victim packet/NF 欄位的 intermediate pattern aggregates。
- 在 intermediate pattern aggregates 上再次運行 AutoFocus,以產生 final significant pattern aggregates。
作者的評估顯示這個解耦方式省去大量的 aggregation 時間,且不會漏掉任何 significant patterns。
編按:只有兩個步驟 0.0
5. 實作
Microscope 的組成是由:
- Data collector(執行階段)
- Diagnosis module(離線)
5.1 Runtime information collection
搭配 DPDK lib,僅用了約 200 行左右程式碼即完成了,因此任何支援 DPDK 的 NF 都可以當作封包 I/O lib 使用。
透過插樁(instrument)DPDK 的傳送、接收函數,以搜集必要的資訊(如下圖),當然也可以將此延伸到其他封包 I/O 的 lib 如 netmap、VPP。
為了降低資料收集對系統效能的衝擊,資料蒐集器(collector)會將資料寫入到 shared memory 中,並交由獨立的 dumper 將資料寫入硬碟中。
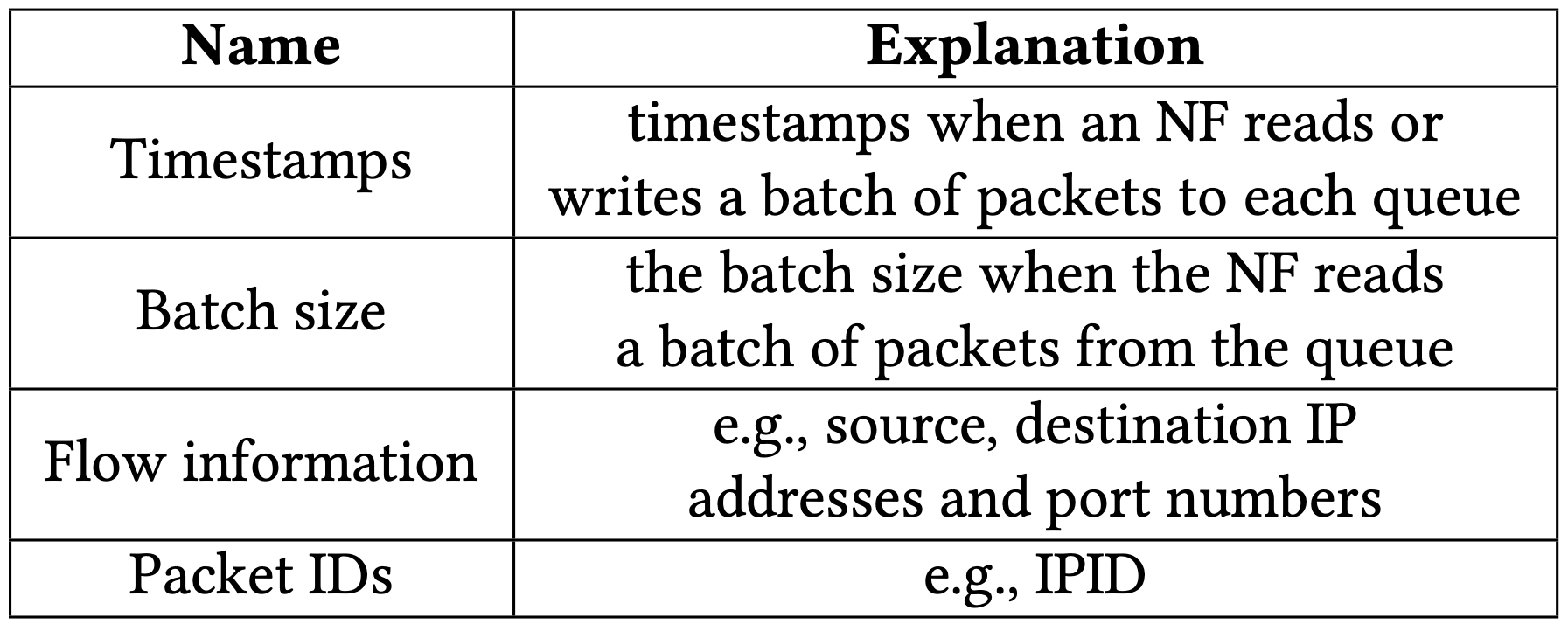
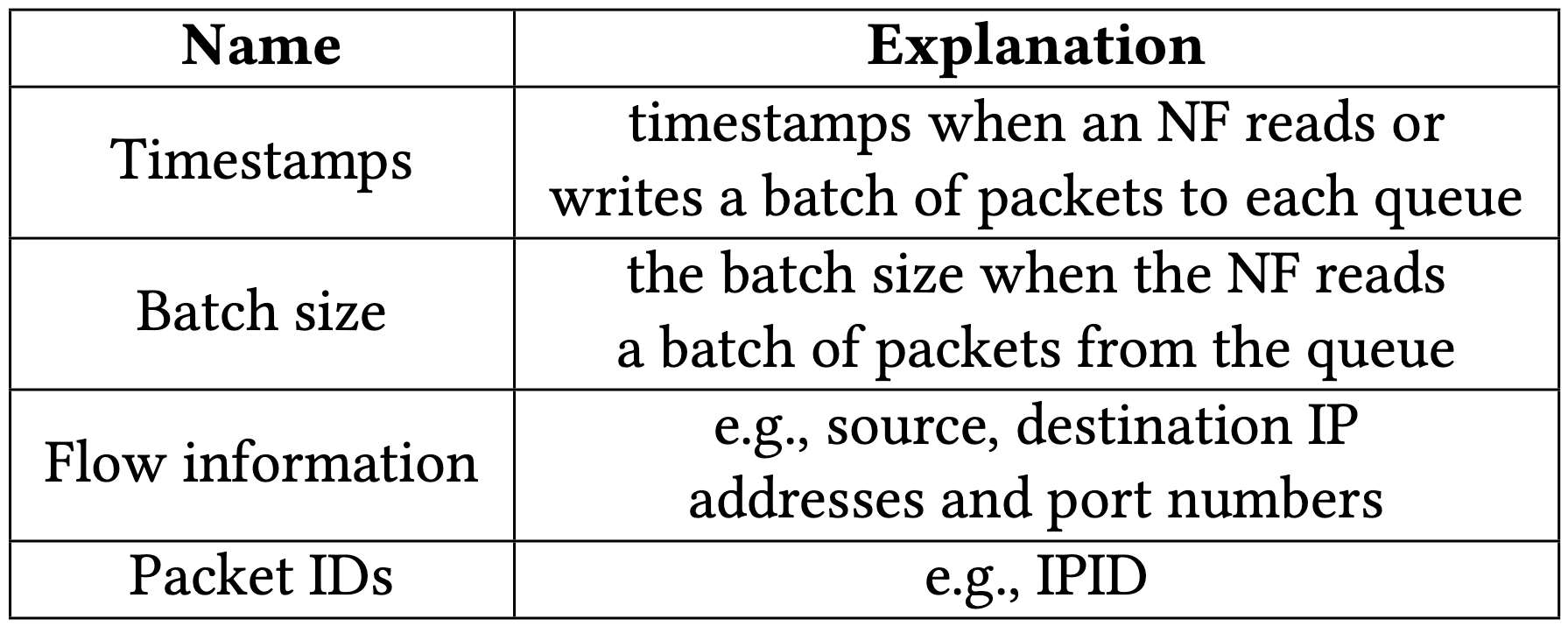
- 每個封包都會記錄下這些資訊:
- five-tuple(source, destination 的 IP 與 port)
- IPID(可能是 independent PID,作者沒提到全名)
- 每個 batch 都會記錄下這些資訊
- timestamp
- batch size
有了這些資料就可以判斷佇列的時間區間,因為若 batch size 小於最大 batch size(通常是 32 個封包),就代表佇列肯定已經被清空!
由於每個封包就至少會需要 15 bytes,對系統會造成不小的負擔,因此作者不打算在每個 NF 都記錄這麼多資訊,而是僅在一般 NF 花 2 bytes 記錄 IPID,只有在 NF graph 最末端(編按:應該就是 VNF chain 最尾端)記錄完整的資訊。
編按:15 bytes 應該是這麼算的「IP (4+4) + port (2+2) + protocol (1) + IPID (2) 」。
如果要這麼做,勢必得有一套路徑重建技術,因為在不同 NF 中可能會有另一個封包有相同的 IPID。為此作者用了三種技術來緩解該問題:
封包路徑
- 在回推的過程中,NF 上游只會是特定幾個 NFs,因此從這些 NF 中遇到 IPID 碰撞的機會不高
- 該方法不適用於動態路徑的 NF,如:負載平衡器
封包時間
- 將上下游封包們做對應,只要將時間做延遲推移即可(propagation delay + queue delay)
- 由於 DPDK 的 queue 中最大封包量為 1024 個,IPID 則有 65536 個,因此在 propagation delay 不大的情況下碰撞機會不高
編按:沒找到 DPDK 有規定 queue size 為 1024 個封包,可能是作者的設定吧。
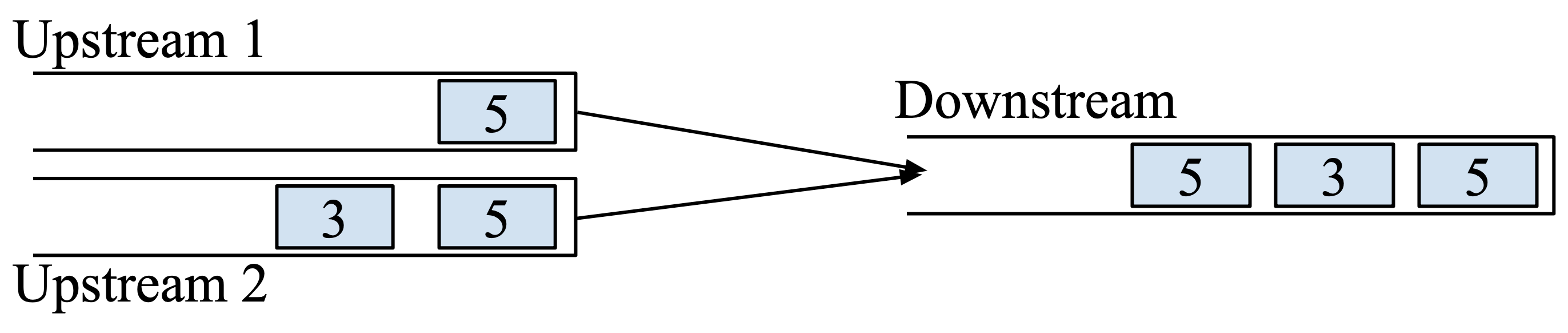
封包順序
在下圖的情況中,IPID 5 的重複情況看似會導致無法辨別,我們可以簡單透過順序性來知道:Downstream 3 左邊的 5 肯定不是從 Upstream 2 來的
5.2 Offline diagnosis
離線診斷模組使用 6000 LOC 的 C/C++ 撰寫而成,並且用下圖的方式來找出 victim packet(延遲太高、吞吐量太低、掉包)的因果關係。
對每個 victim packet,都會使用 §4.3 提到的遞迴方式來處理,最多遞迴次數即為該 NF 上游 NFs 的個數。
6. 評估
該工具可以在 overhead 不高的情況下,在 CAIDA Trace 資料集中正確地捕捉 89.7% 的效能問題。
6.1 環境設定
NF 環境
- 使用 Click-DPDK
- 每個執行個體皆跑在單獨的實體 CPU core 的 VM 中
- 使用 SR-IOV 分配網卡資源
- 使用 MooGen 發送 CAIDA 16 封包
- 使用 64 bytes 大小封包
- 因為 NF 效能表現主要跟封包量有關係,因此該設定能使系統盡量達到較高封包速率
拓樸
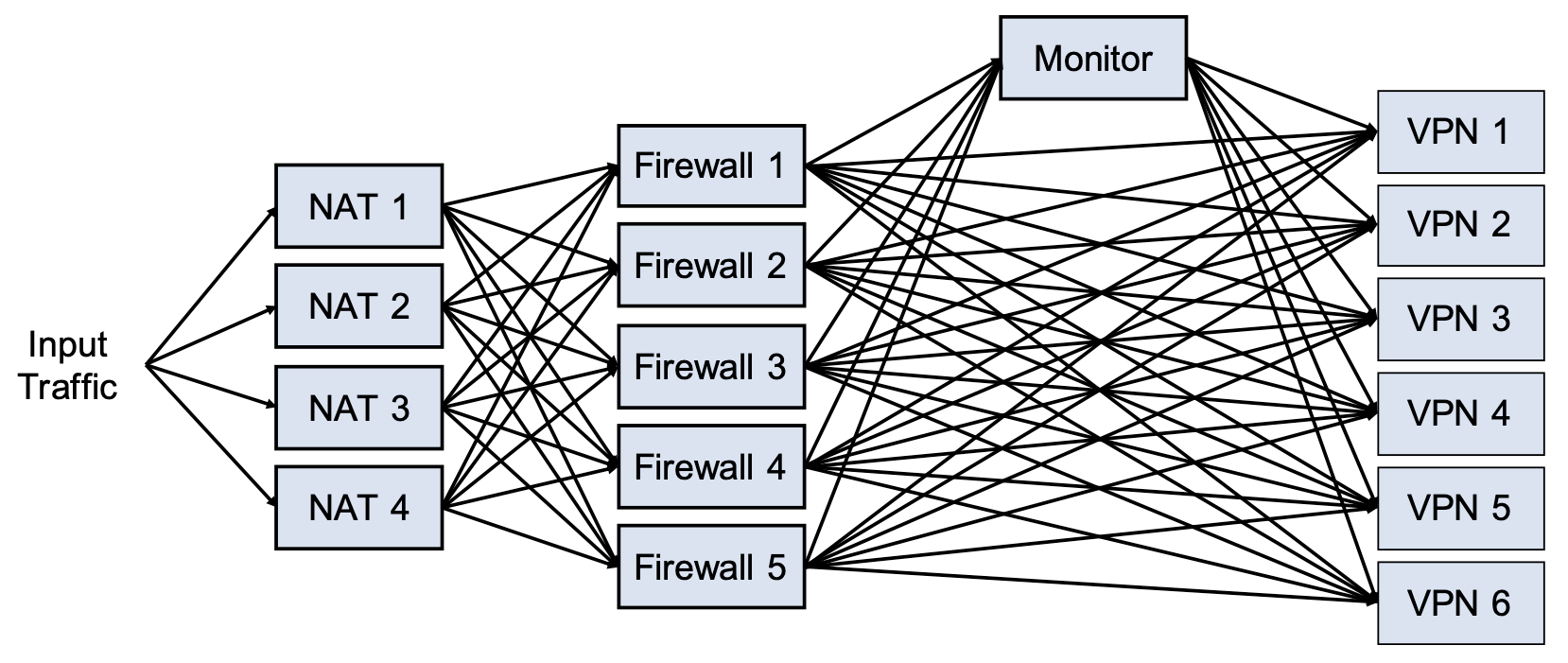
其拓樸如下圖,4 種 NF 共 16 個執行個體。
- 透過 hash 機制做負載平衡到 NAT
- 如果符合特定 Firewall 規則,封包會先被送到 Monitor
硬體環境
- Dell R730(MooGen)
- 10 cores, 32 GB RAM
- 2-port 40Gbps Mellanox ConnectX-3 Pro
- Dell T640(16 NFs)
- 2 * 10 cores, 128 GB RAM
- 2-port 40Gbps Mellanox ConnectX-3 Pro
6.2 診斷準確性
方法
礙於在真實世界遇到這些問題有難度,不如自己手動模擬問題的發生,因此後面的模擬都是手動注入的問題,再量測其結果。
實驗使用不大不小的 1.2 Mpps 封包,以避免大量封包造成其他問題的產生,而影響到量測準確性。
注入問題分成三類:
- Traffic burst
- 隨機選一些流發送突發封包,封包量從 500 ~ 2500
- Interrupts
- 隨機挑一個 NF,在 500~100 μs 內給予一個 interrupt
- NF code bugs
- 隨機挑一個 Firewall 注入 bug,其在處理特定流的時候會特別慢(0.05 Mpps)
- 實驗時會注入 50~150 封包量的流來觸發
作者的目標是:
- 找出 culprit flows(for traffic burst)
- 找出 culprit NF(for interrupts)
- 找出 culprit NF-flow pairs(for NF code bugs)
在實驗室的過程中,有確保注入的問題都有相隔一段時間,每次實驗進行五秒鐘,可蒐集 12.5 MB 資料。
準確性指標
由於比較對象 NetMedic 採用 ranked list 機制來判斷 culprits,本篇也採用相同方式以方便做比較。
Rank 的順序性依發生原因的可能性排列,也就是 rank 越低代表該 culprit 影響的程度越高,其計算方式是計算某項影響因子對特定元件與對所有相關元件的影響比例的倒數,詳細可參考該論文的 §5.3.3。
整體準確性
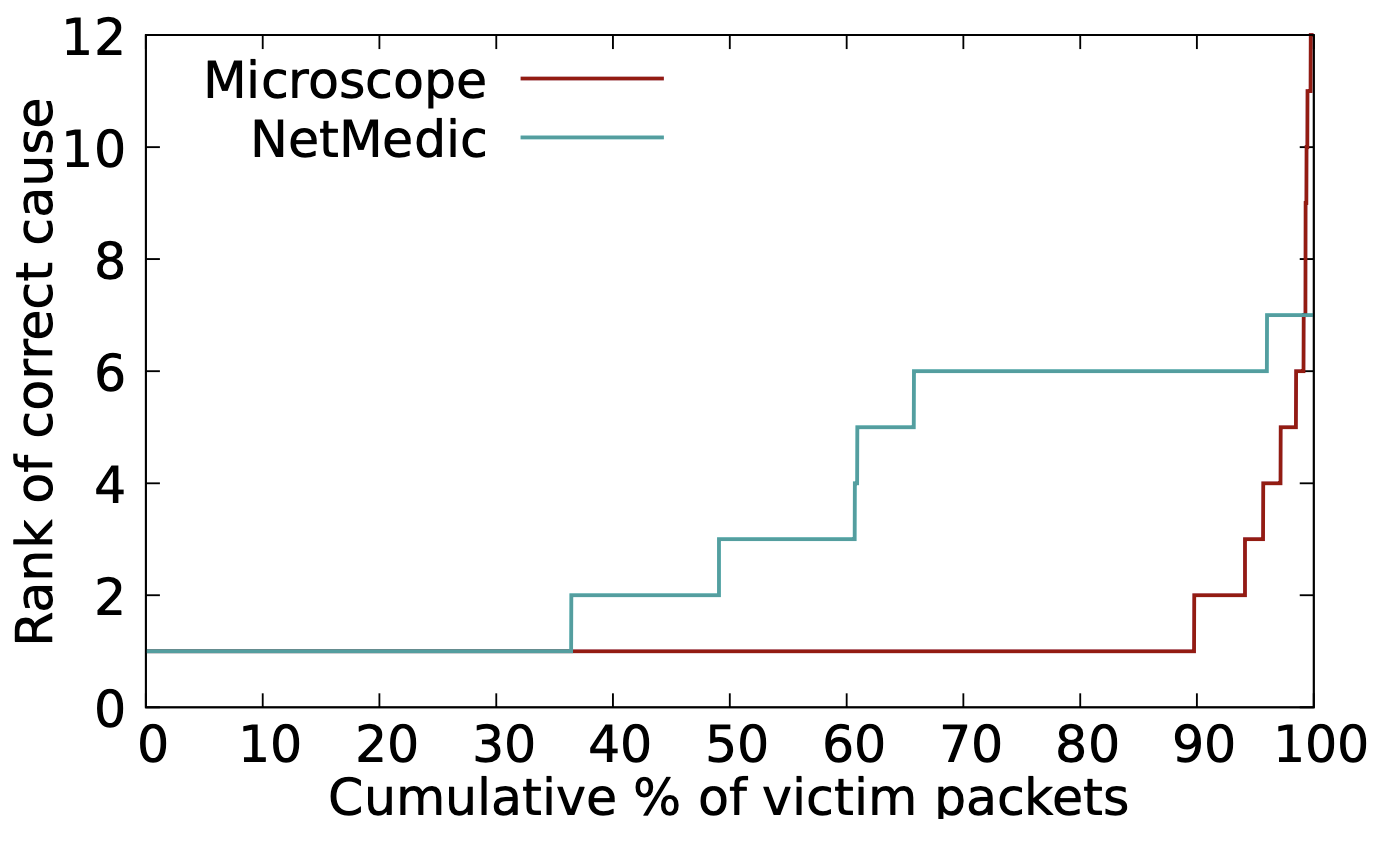
下圖為兩種方法的 CDF,Microscope 明顯勝過 NetMedic。
可以看到在所注入的問題中,Microscope 有 89.7% 的機率都是在 rank 1 就正確識別出該 culprit,另外 10% 是每次總有兩個以上的 culprit 被發現而其他問題被視為較高可能性的 culprit(但實驗只有注入一個問題)。
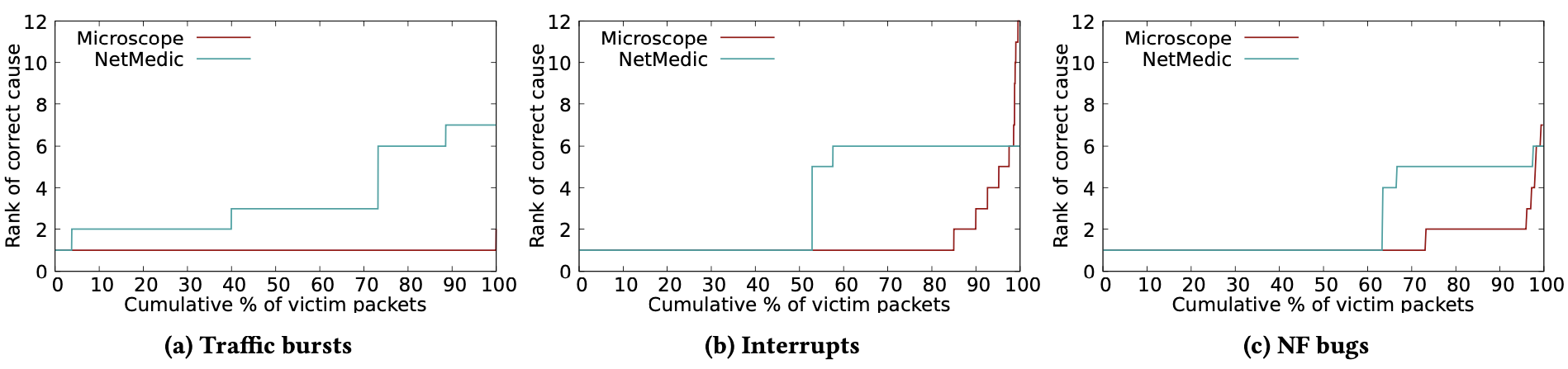
個別準確性
可以看到在三種實驗中,Microscope 表現都優於 NetMedic。
- 在 interrupt 中
- 有一部分原因是 NetMedic 不太能成功捕獲有時間差的問題,如同 §2 中所描述。
- 在 NF bugs 中
- Microscope 首先歸因於 traffic burst,再來才是 NF bugs。
- NetMedic 正找到 NF bugs 的 culprit 都落於 rank 4~6
- 雖然這是 Firewall 出問題後才影響 VPN,但兩者間有一定的時間差,導致無法正確進行錯誤關聯
Runtime overhead
峰值約有 0.88% ~ 2.33% 的效能下降
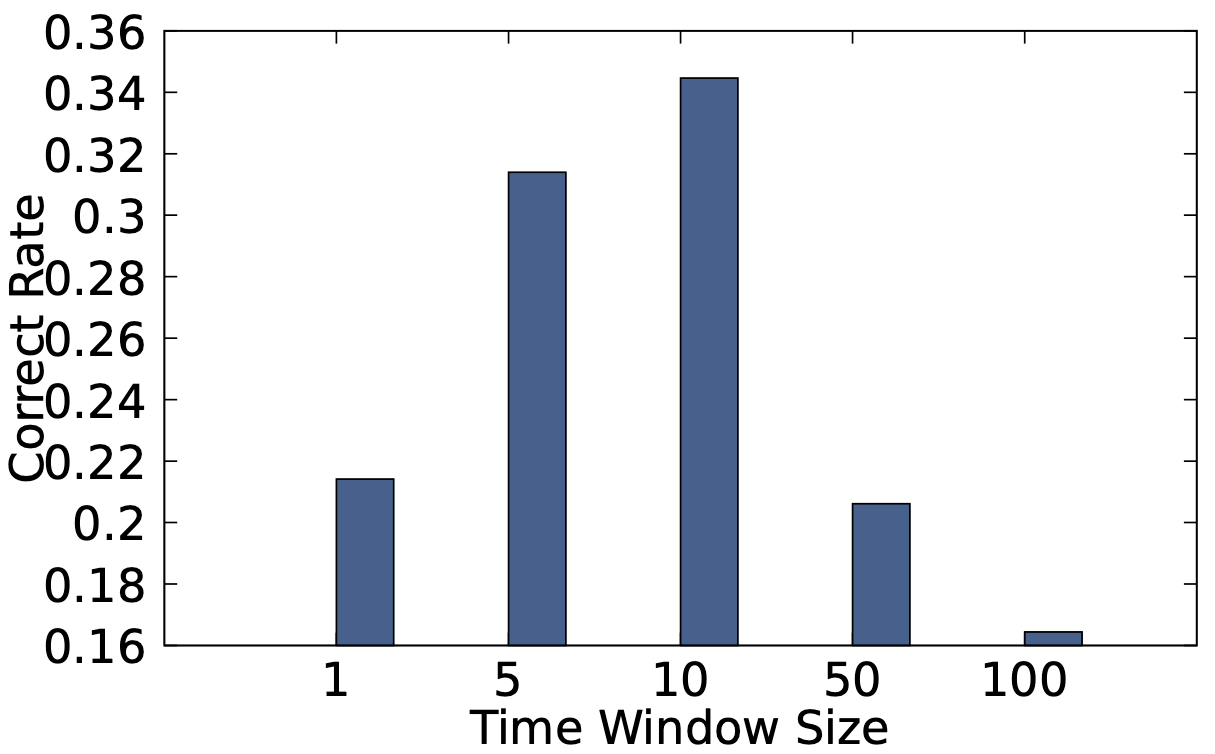
不同 Time Window Size 對 NetMedic 的影響
不論在什麼 Time Windows Size 下 NetMedic 都比 Microscope 差。
因為在 Time Window Size 等於 10 ms 的時候效果最好,後續實驗都用 10 ms 當基準。
6.3 詳細評估
- Burst size 的影響
- 使用的 burst size 介於 2000~5000 個封包之間
- 用 5000 封包時,判斷結果最準確
- 隨著封包量下降,準確度下降,因為佇列的長度就變短了
- Interrupt 長度的影響
- 使用長度介於 300 ~ 1500 μs 之間
- 1500 μs 時,判斷結果最準確
- 隨長度下降,準確度下降,因為 buffer 的封包變少了
- Propagation hops 的影響
- 隨著 hop 數提升,準確度下降
- 因為當問題會隨之傳播,使得 victim 也變成 culprit(編按:不確定是否理解正確)
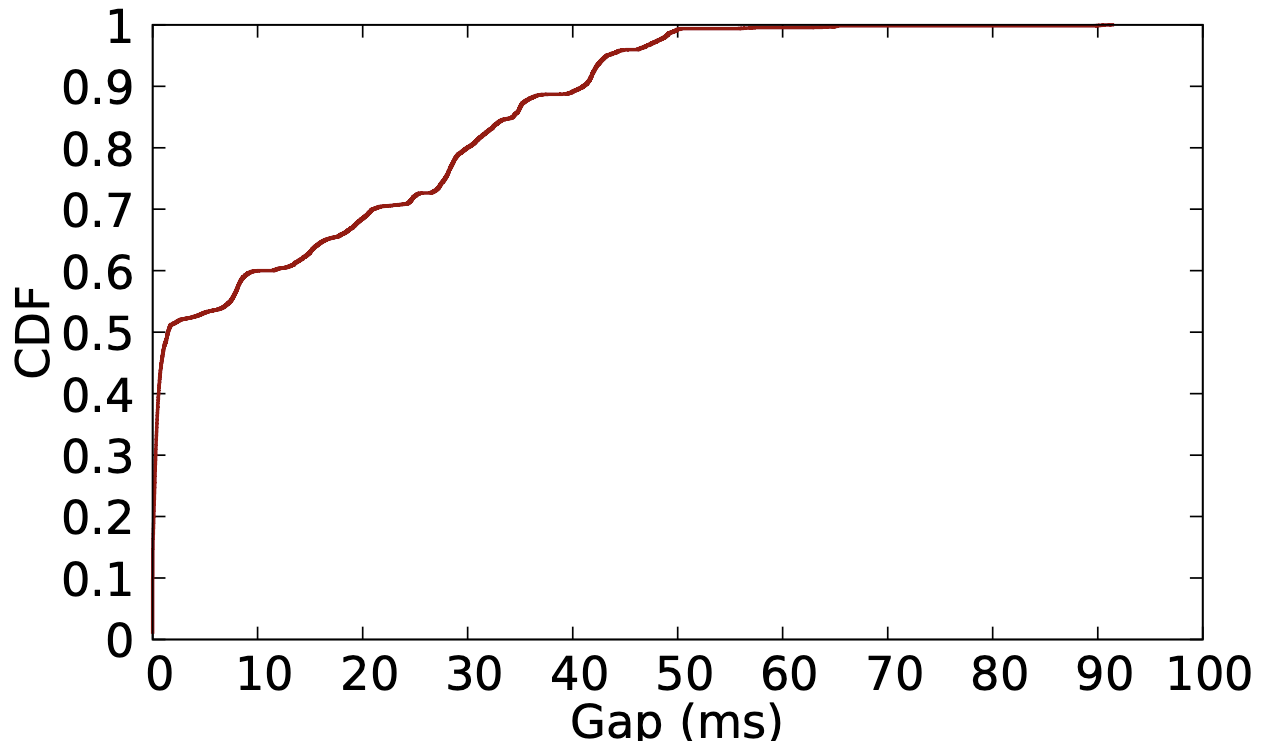
Culprit 與 Victim NF 間的時間差
有一半都是低於 1.5 ms 的,在 1.5 ~ 50 ms 則是均勻分佈,因此不好挑一個適合的 window size。
名詞解釋
Heavy Hitters (HHs)
在網路流量中異於常人的多的流量(outliers),可能由是一個或多個連線組成,通常會用一個閾值來劃分。
如果要分析網路流量而找出 HH,通常記憶體開銷會非常大且耗時,因此通常是離線分析為主。
Hierarchical Heavy Hitters (HHHs)
階層式的聚合某些特徵來當作同一種類的 HH,例如具有共同的 IP prefix 就可以當作是一個階層,這樣的特徵稱之為 dimension。
Dimension 可以為 IP prefix, port range, protocol 等等,因此多個 dimension 組成的 HHH 就稱為 multidimensional hierarchical heavy hitters。
參考:
- Online Identification of Hierarchical Heavy Hitters: Algorithms, Evaluation, and Applications, SIGCOMM 2004
- Finding Hierarchical Heavy Hitters in Streaming Data
- A SDN Soft Computing Application for Detecting Heavy Hitters
comments powered by Disqus