概要
當今企業網路中,有 53% 的 NF 可以被平行化加速。因此作者提出了一個框架,採取一些手段使得 NF 們可以平行化處理:
- Policy specification scheme
- 描述 sequential 或是 parallel NF chaining 意圖
- Orchestrator
- 辨識 NF 的相依關係,並且自動將 policy 編譯成高效率的 service graph
- Infrastructure
- 輕量級封包複製、分散式平行封包傳遞、負載平衡合併封包
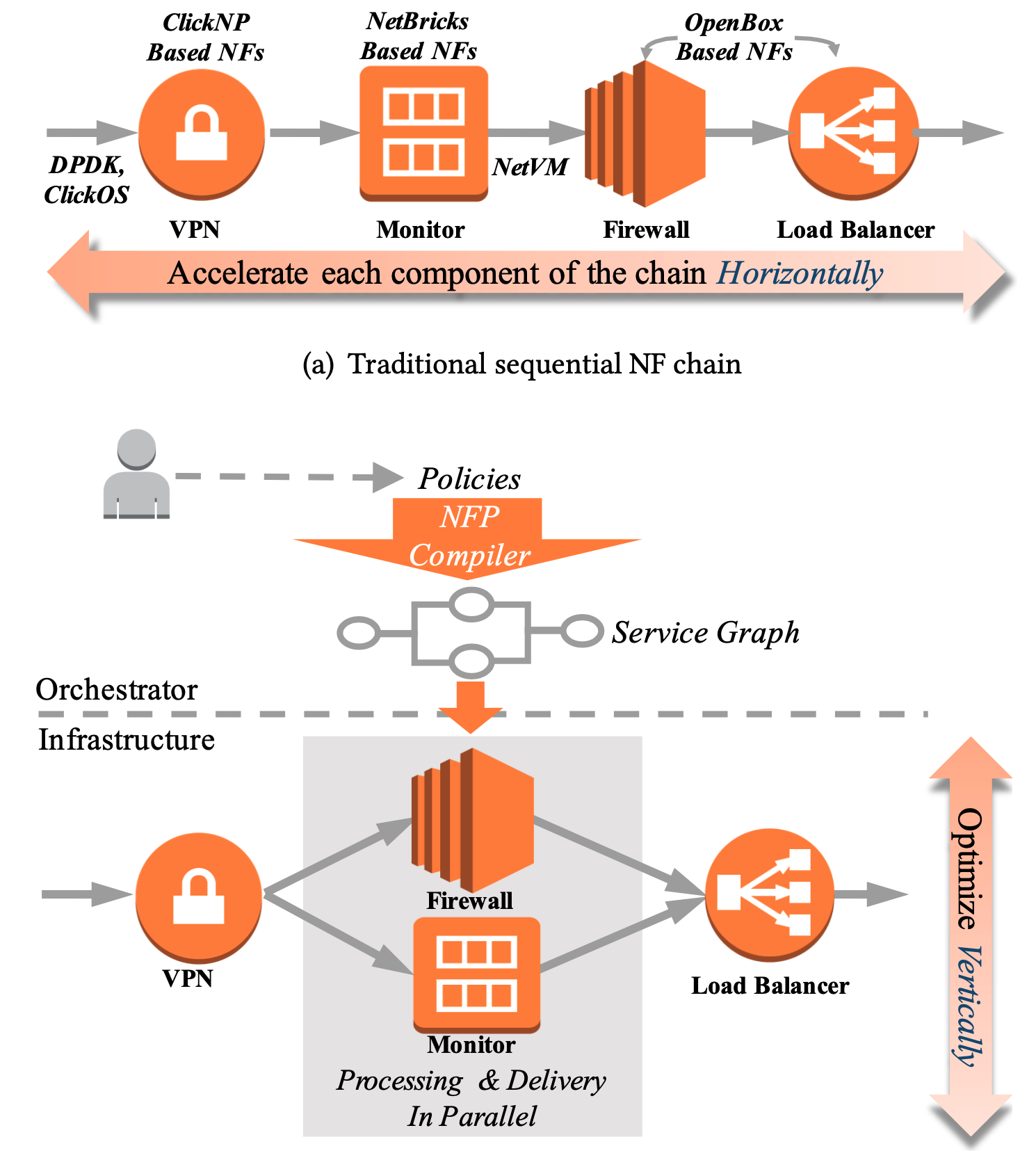
- 輕量級封包複製、分散式平行封包傳遞、負載平衡合併封包
介紹
對延遲要求的服務:
- 即時分析系統
- Online Data-Intensive (OLDI) application
- 網頁搜尋、線上零售商的簡訊(?
- 自動交易(algorithmic stock trading)
- 高效率分散式記憶體快取(distributed memory caches)
前人作品
獨立 NF 加速
- ClickNP: offload software logic onto programmable hardware (FPGA)
- NetBricks: 禁止使用 container 或 VM、將 NF 運行在單顆 CPU 上
封包傳送加速
- Intel DPDK
- ClickOS
- NetVM
模組化 NF
- OpenBox:模組化、分享 common building blocks
前人作品的缺點
仍有 sequential 執行問題,因此作者打算平行化處理那些可以被平行處理的 NF。
此想法來自 CPU 所使用的 ILP (Instruction-Level Parallelism) 技術。
背景與挑戰
背景
現今 NF 執行方式分兩種:
- pipelining model
- 在一條 chain 中使用多核心
- RTC (run-to-complete) model
- 整合整個 service 當作一個 process 執行(單一核心)
- 缺點:如果有一個 NF 卡住,那很難使用 scaling 方式擴展,因為一次擴展就是一整條 chain
- 例如 Bess
NFP 針對 pipelining model 做平行化加速!
挑戰
- Policy 設計以描述 service graph
- 傳統用來描述 sequential NF 位置的方式難以在平行化環境下使用
- Orchestrator 設計以建構 service graph
- 需要辨識 NF 的相依性、自動化編譯 policy 成 service graph
- 手動分析太慢,作者希望自動分析
- Orchestrator 設計以最佳化 resource overhead
- 平行化執行可能導致多個封包被複製,浪費記憶體、頻寬資源
- 解法:智慧的辨識是否需要複製、僅複製 header 欄位來解決
- Infrastructure 設計以支援 NF 平行化
- 支援輕量化封包複製、合併模組以合併被平行處理的封包
- 合併可能成為瓶頸,因此需要負載平衡
- 中央化的虛擬 switch 可能成為瓶頸
Policy 設計
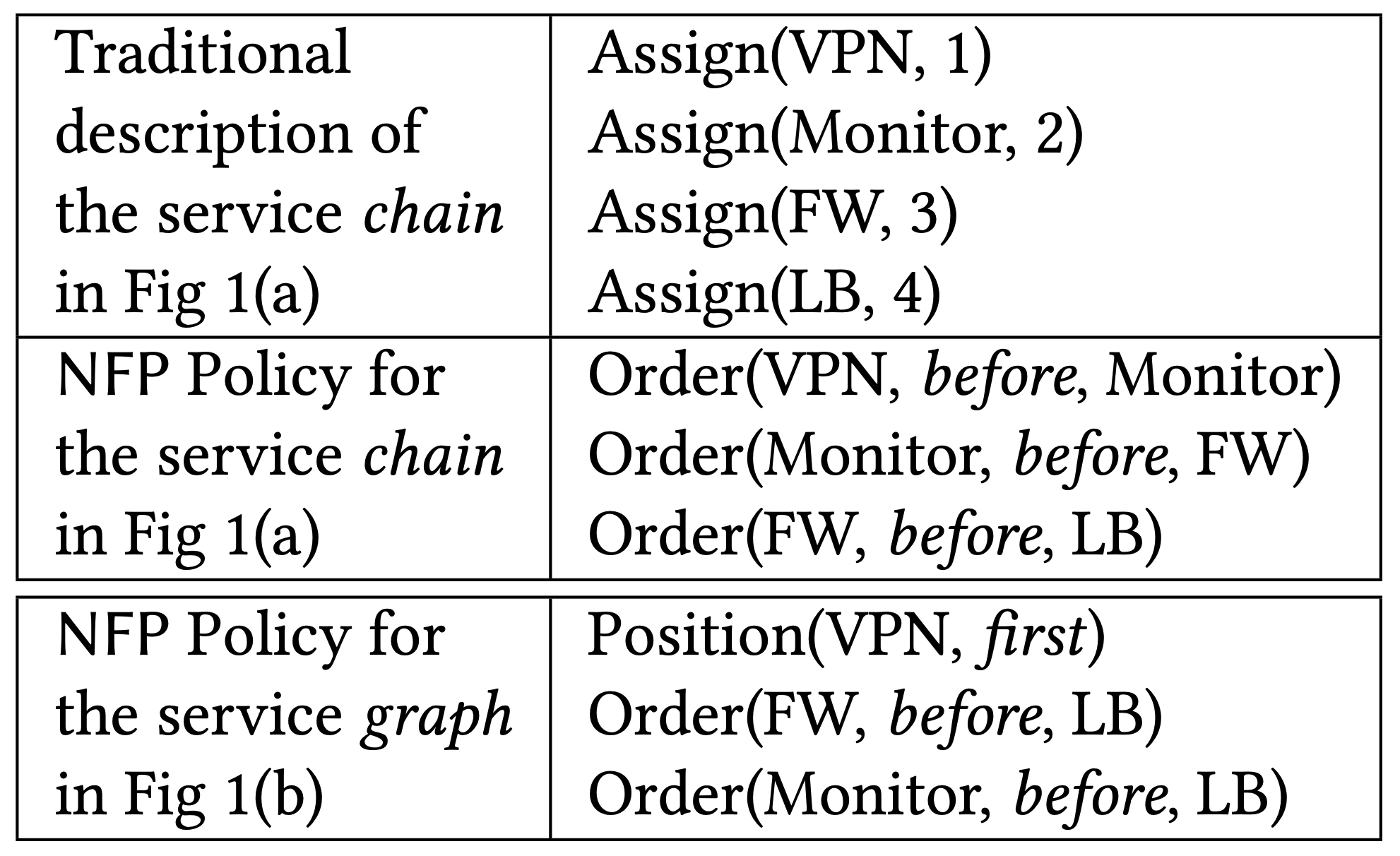
Order 表示先後順序
- Orchestrator 會想辦法找尋把 order 變成可平行化處理的機會(變成 priority),並且在 back order 的會有較高優先權(?
Position 表示絕對順序
- 只分成 first, last
Priority
作者說兩個 NF 在平行處理時可能會有衝突,因此設 priority 來決定誰的決定比較重要
編按:什麼衝突?
- 例如 IPS 說不用 drop 但 Firewall 說要
編按:可是不是 drop 優先權最高嗎?
Orchestration 設計
平行化分析
作者從其他論文上整理了一些常見 NF 的 action。
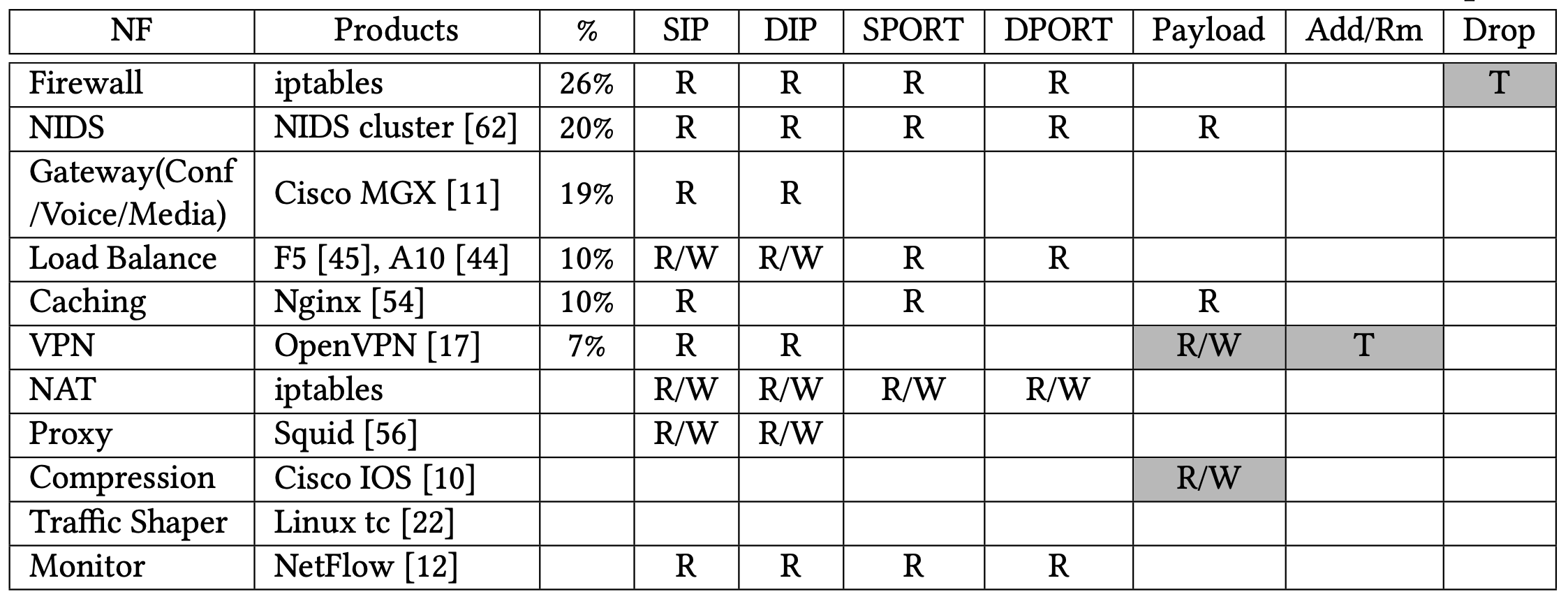
NF action table
為了避免 race condition,作者做了一張表來描述平行化的可行性:
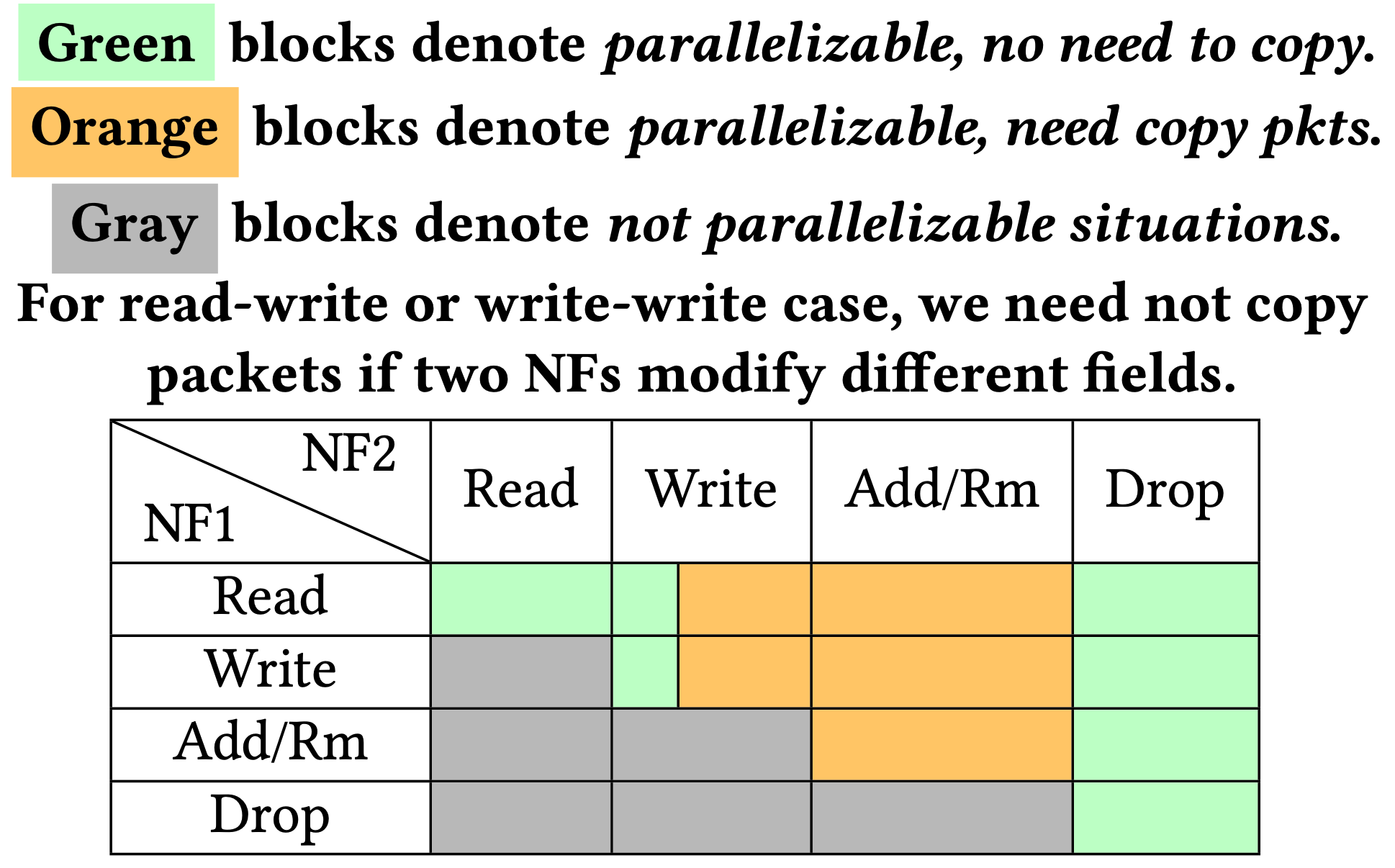
action dependency table
Resource Overhead 最佳化
Dirty Memory Reusing
- 如果兩個 NF 分別對不同的欄位做讀寫,那沒必要複製封包
- 雖然這兩個 NF 在不同 CPU 核心上存取可能會遇到 cache line 競爭,不過實際測量起來對效能沒有顯著影響
Header-Only 複製
根據表 2 顯示,只有 7% 的 NF 會修改 payload,且 header 通常來說只佔總封包大小的 8.8%,因此作者提出了只複製 header 的方式來允許平行化。(同時得修改成正確的 length)
編按:不過這不會對一些判斷長度的 NF 產生影響嗎?
NF 可平行化辨識
Orchestrator 會維護一張 NF action table(AT)、一張 action dependency table(DT)。
因此透過這兩張表搭配下面演算法來得到 NF 之間是否可以平行化處理:

為了使新的 NF 可以融入 NFP 當中,網路業者需要:
- 手動產生 NF 的 action profile
- 或是經由 NFP 的自動分析工具
Service Graph 建立
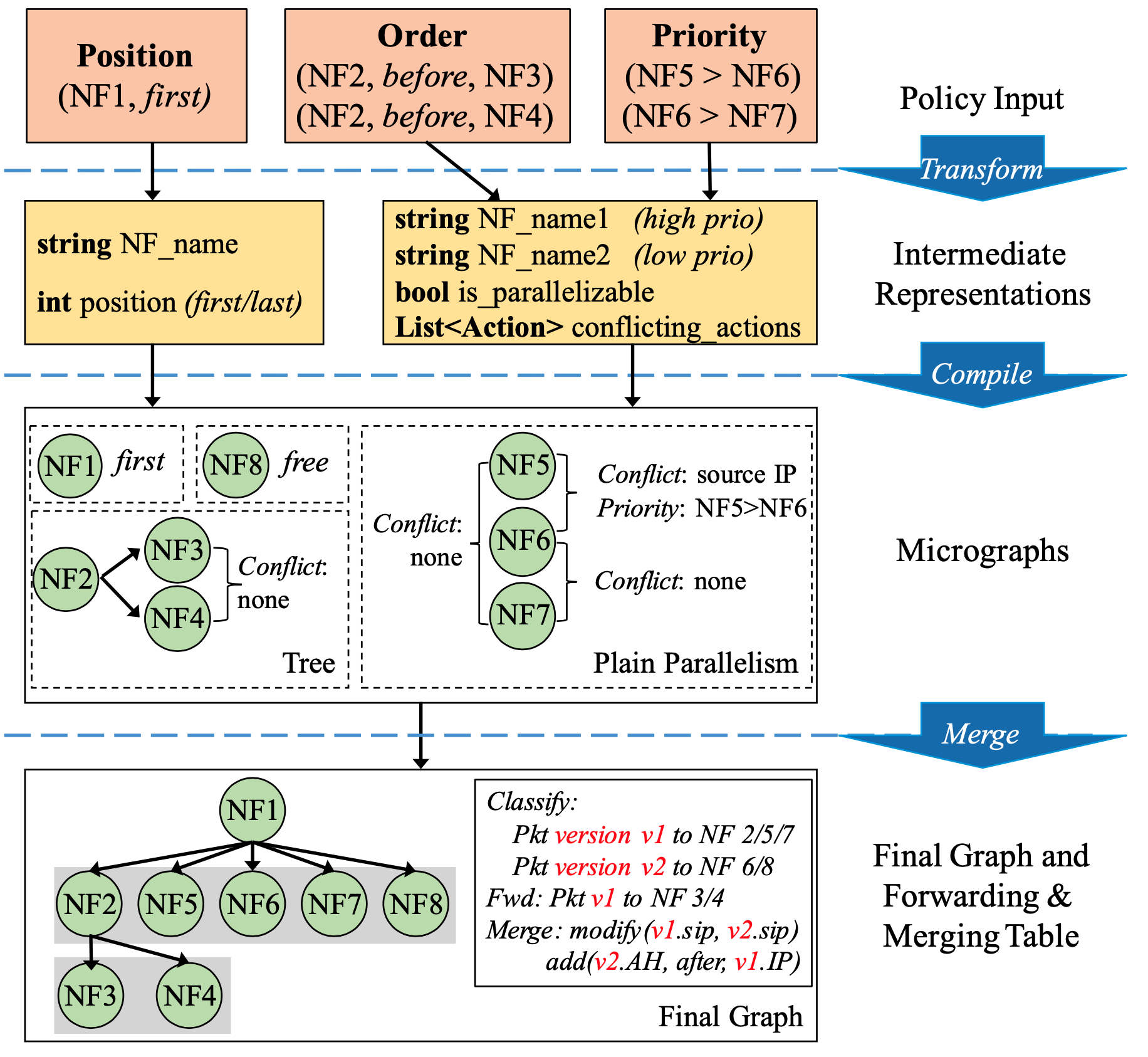
將 policy 轉換成預先定義好的 intermediate representations → 編譯 intermediate representations 成獨立的 micrographs → 整併成最終的 service graph
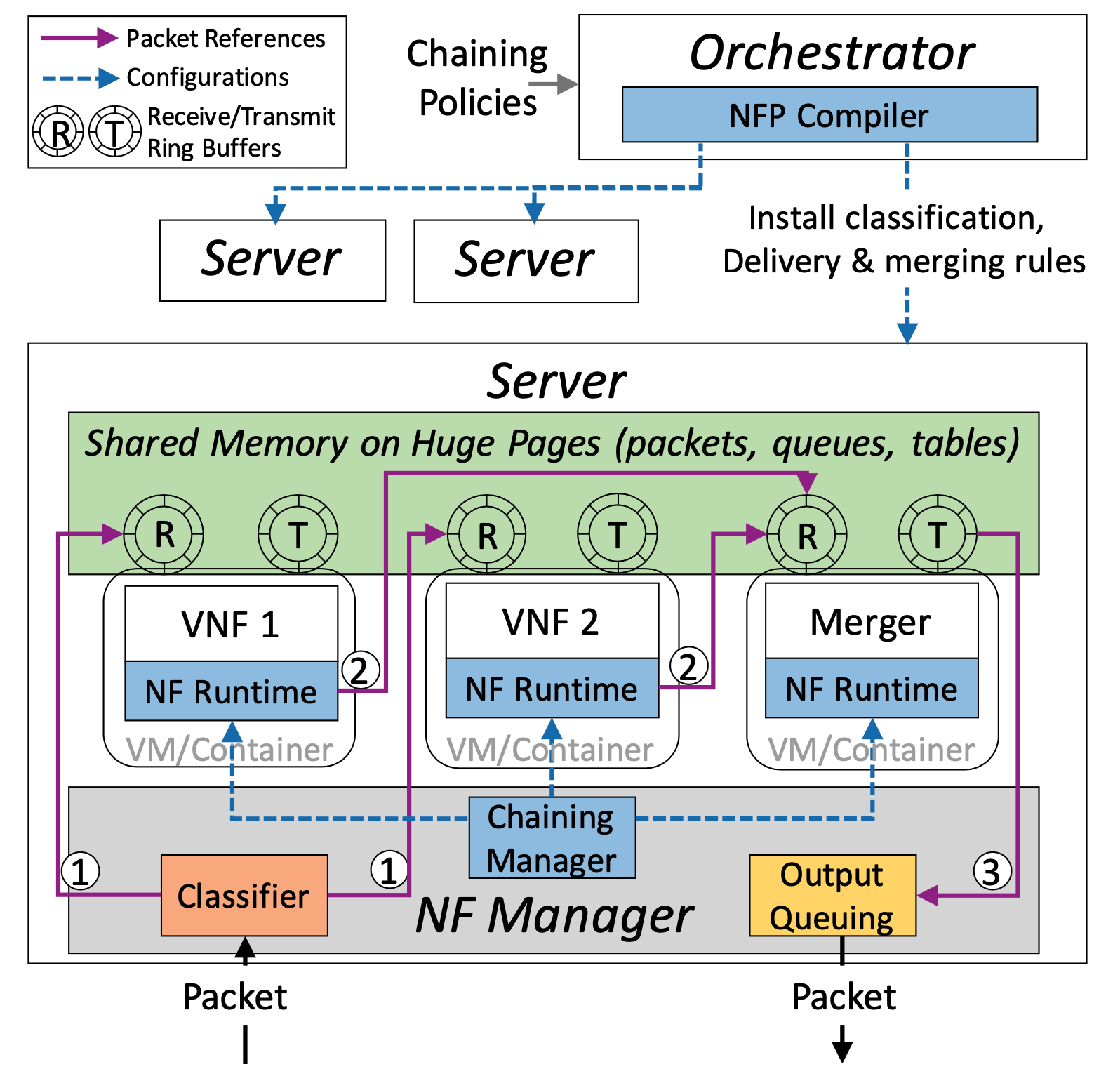
Infrastructure 設計
- 使用了 NetVM 提出的 zero-copy packet delivery
- NF 互相共享位於 huge page 當中的 ring buffer
挑戰:
- 當其中一個平行的 NF drop 封包時
- merging 模組負荷過重
- centralized virtual switch 需要改善
封包分類
分類器需要有下列資訊:
- 總共有多少個封包複製
- 要如何合併被複製的封包們
- service graph 的第一個 hop
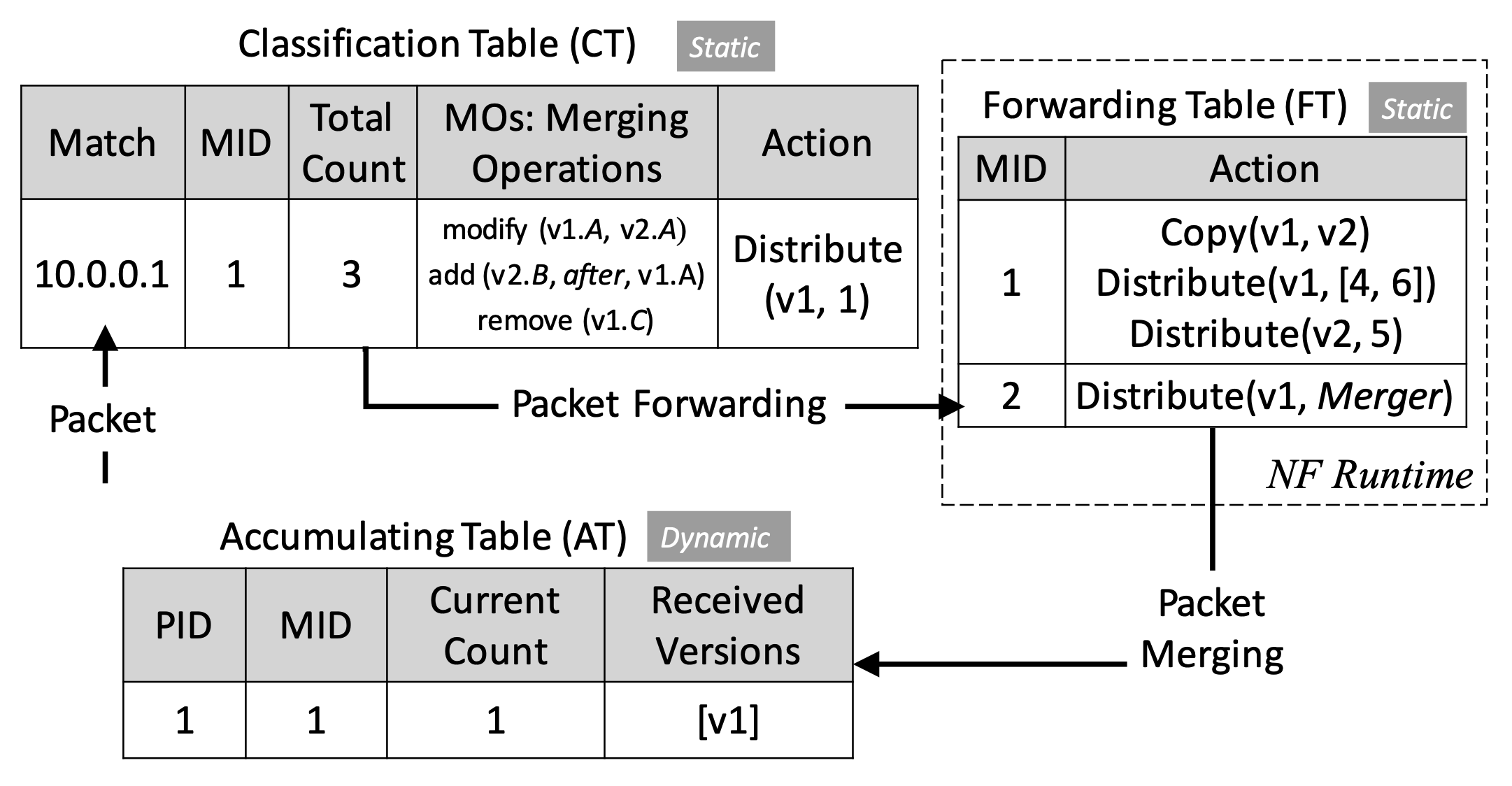
Classification Table 是由 Orchestrator 產生,接著安裝進分類器。
需被送進相同 service graph 的封包們會有相同的 Match ID (MID),這樣之後被 merge 時才知道怎麼做。
在封包被送進 service graph 前,會先加上 20 bit 的 MID 資訊,這總共可以表達 1 百萬組 graph。
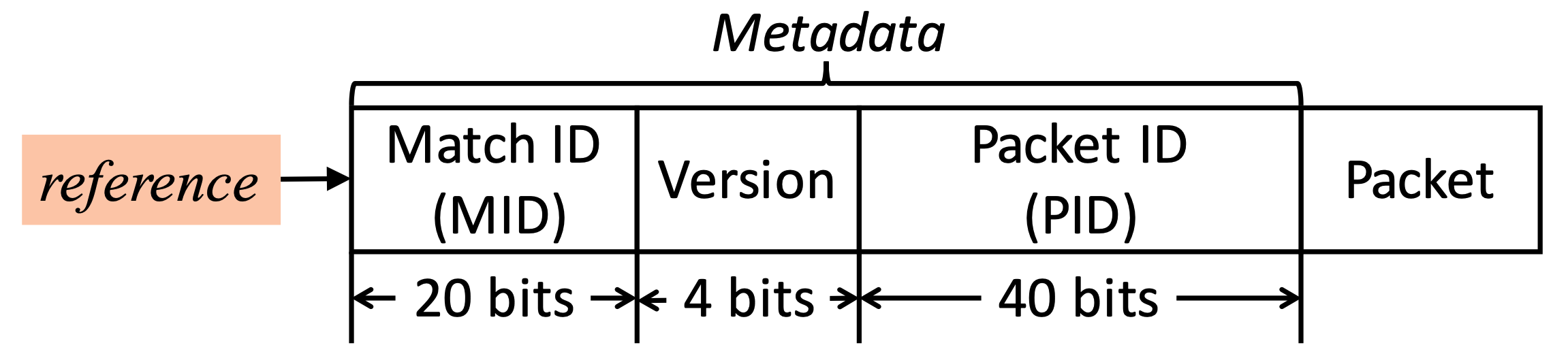
再來有版本號(version)用來表示哪個複製。
Packet ID(PID)則是使用 hash 方式產生 40 bit 的資訊。
封包在 NF 間傳送
為了使 NF packet forwarding 過程更加順利,並且減少對 NF 開發者的負擔,作者為每個 NF 打造了一個 NF runtime,用來達成 traffic steering。
該 runtime 會複製 packet reference 到下一個 NF 的 ring buffer 當中,以達成 forwarding。每個 runtime 會維護一個 forwarding table (FT),其會有 local view,而 global view (global forwarding table)則是在 service graph 產生後就有了,會被安裝在 chaining Manager 當中,其再將 global table 分成 local table 安裝在每個 NF runtime 當中。
NF runtime 會根據不同情境做不同事情:
ignore
- 當封包被 drop,則傳送 nil 到下一個 ring buffer
distribute (version, target)
- 不需要複製時,傳送當前版本號到 target(一個或多個)平行化 NF
Copy
複製當前封包,更改版本號
作者只複製 header 部分,並且更改 length 到目前 header 的 length
並且在系統初始化時就預先提供 memory block 以存 input 或 copied packets,以避免動態分配記憶體的開銷
編按:這不是更浪費 RAM?且 glibc 的 arena 機制本來就會先要一塊大的,如 fast, unsorted, small, large 等等。
封包合併負載平衡
合併
Merger 會維護一份 dynamic Accumulating Table (AT),裡面記載目前收到的 copy 數量,滿了才會進行合併。
Merging Operations (MOs) 則會寫該怎麼進行合併,像是只合併哪些欄位等等,共分三種:modify、add、remove。
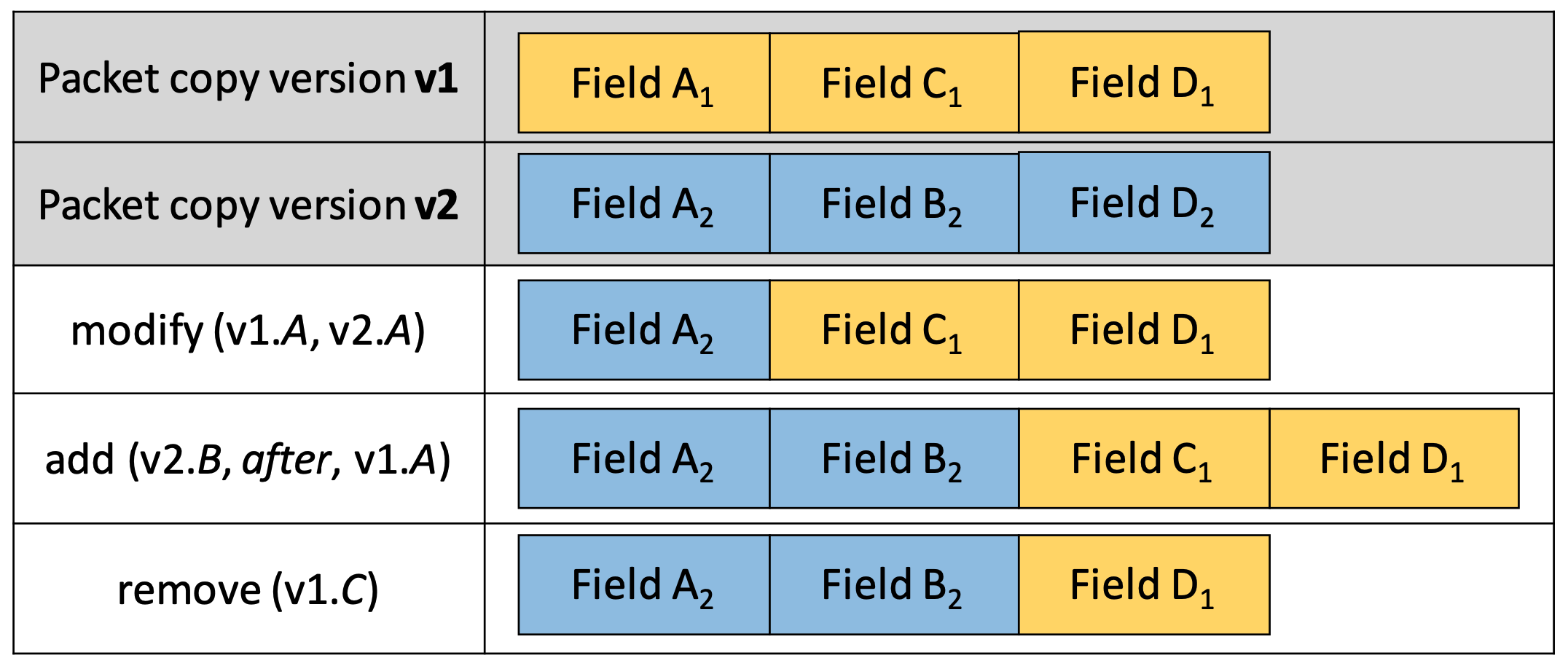
有一種方式是透過 xor 來進行封包變更合併,不過這種方式沒辦法處理 header 新增、移除的情況。
作者將 merger 做成 NF 以方便管理。
負載平衡
Merger agent 會負責負載平衡,並且確保不同的 copy 會流向相同的 merger,此部分利用 PID hash 達成。
將 NF 整合進 NFP
有個自動化分析工具,可以根據分析 NF 的程式碼,查看呼叫了哪些函式,已得知做了哪些 action。
(但是如果已經編譯好了呢?
實作
作者使用 Docker,privilege mode 以存取 host 的資源。
效能評估
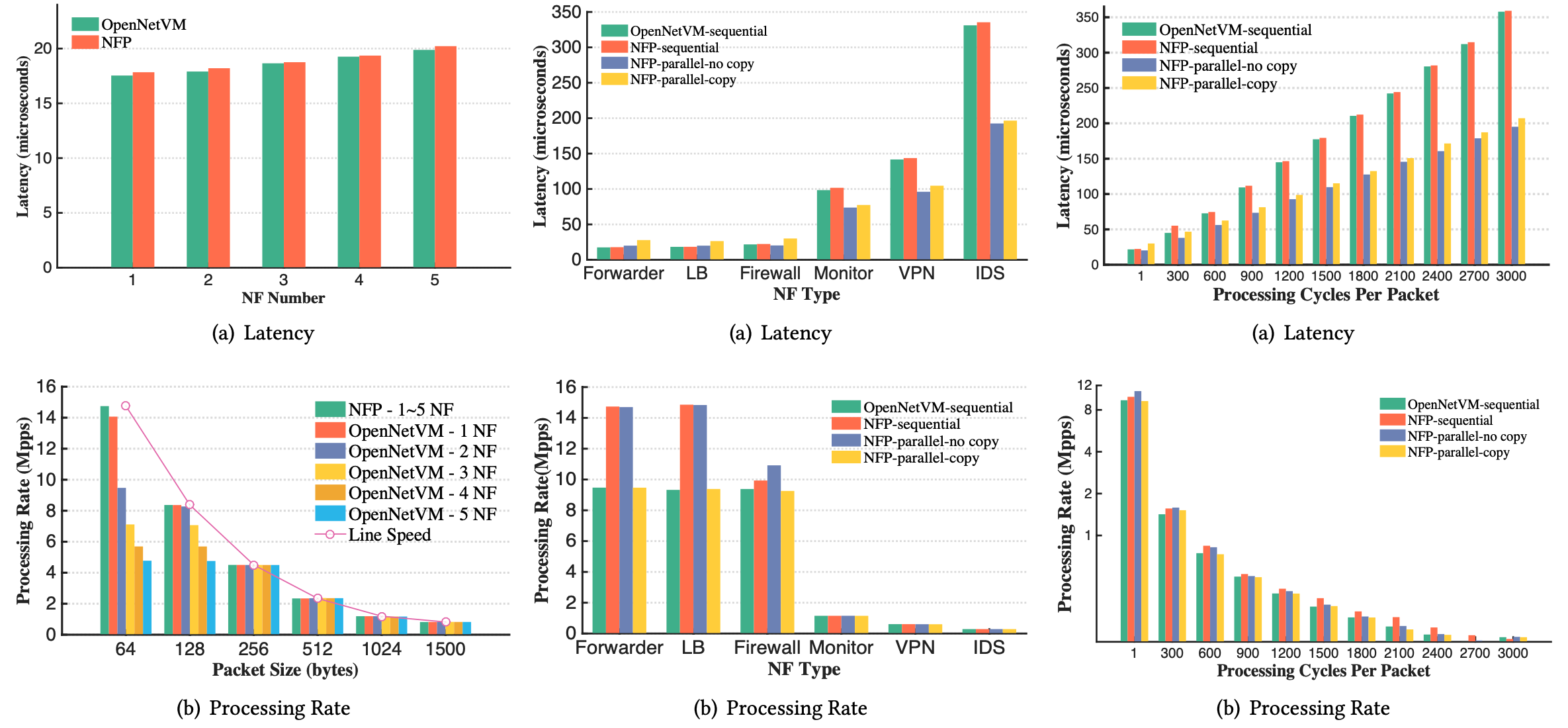
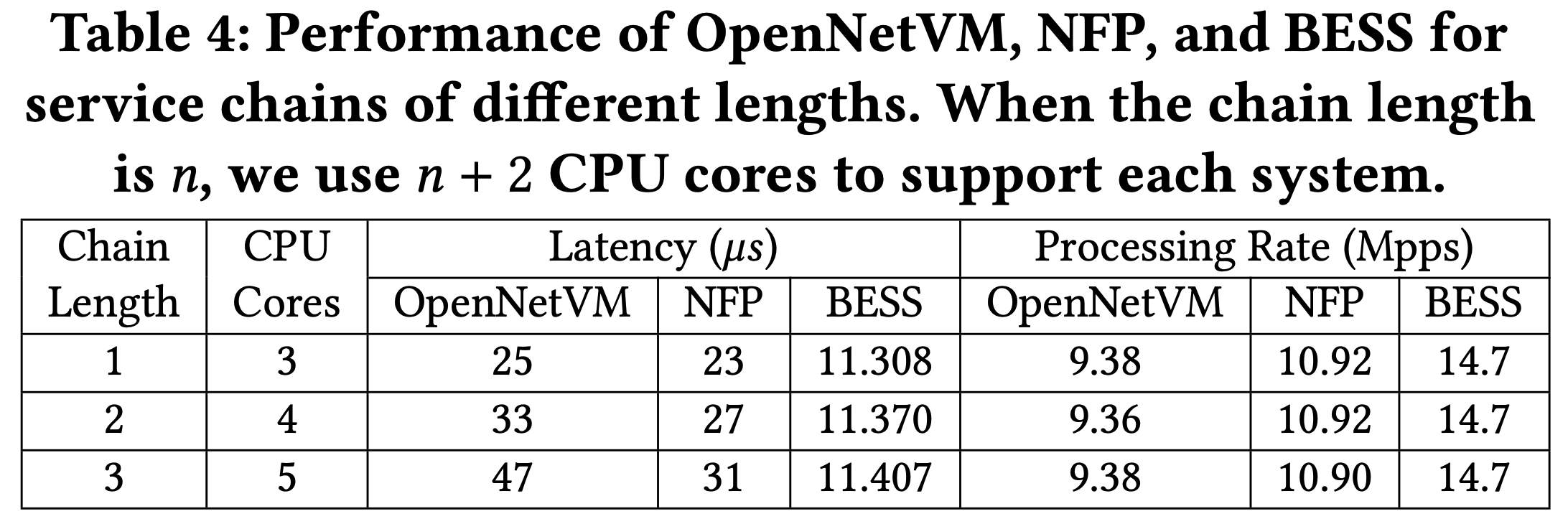
可以看到 BESS 那麼好,是因為他整合成一個 process!
comments powered by Disqus