概要
這篇論文提出了一個對於 NF 來說公平的排程器,旨在解決作業系統無法清楚知道 NFV 的需求,因此自定義排程器來決定 VNF 執行排程,以達到根據流量來定義排程,且不需修改系統排程機制。
對作者來說,假設有兩個 NF 擁有相同的 packet arrival rate,但其中一個 NF 的處理開銷是另一個的兩倍,而他們兩個的 output rate 仍須一樣,這才是公平。
NFVnice 是一個:
- user space 的 NF scheduler
- service chain management 框架
作業系統的排程器:
- 不知道NFs 之間的指標、primitives(packet flow 的不同)
- 無法考慮到 chain level 資訊
也就是,可能在一個 NF Chain 中,前面的 NF 處理很快,但是後面的 NF 處理不來,這樣就會造成 drop,是一種浪費。
在 NF 的領域,一個 NF 可能會有變異很大的 per-packet 開銷,像是有些可能需要做 DNS 查詢,比起那些單純做規則匹配的操作來說,這些 IO Wait 很大。
NFVnice 做到下面這些事:
- 基於封包到達率、處理開銷,自動調整 CPU 排程參數,以提供公平分配
- 在 user space 決定 NF 的 CPU share
- service chain level 的 congestion control 以達到 backpressure
- 將 backpressure 套用到整個 chain,而不只是鄰近的 NF,並且使用 ECN 管理不同 host 的擁塞
- 呈現不需要修改到系統的 scheduler-agnostic 框架
這些測試都是在 OpenNetVM 上(基於 DPDK),支援不同的 kernel scheduler。
在超載的狀況下,使用 vanilla CFS BATCH scheduler,將 packet drop 從 3Mpps 降低到 0.01 Mpps。
動機
現階段的瓶頸
作者針對 CFS normal, CFS Batch, Round Robin 這三者做了一些效能測試。
CFS
Completely Fair Scheduler 在 Linux kernel 2.6.23 開始將其設定為預設排程器。
它負責將 CPU 資源,分配給正在執行中的行程,目標在於最大化程式互動效能的同時,最大化整體 CPU 的運用。使用紅黑樹來實作,演算法效率為 O(log(n))。
timeslice 並不會固定,而是相對於正在運行中的其他任務,每次執行時有固定的 allotted timeslice,又或是程式自願提早 yield。
CFS Batch
這似乎是作者自行提出的,類似於 CFS,只是有更少的 interrupt,進而帶來更長的執行時間、更少的 context-switch。
Round Robin
每個程式都有其固定的執行時間,作者設定為 100 msec
測試參數
這是在使用 DPDK 技術的 NFV 平台上進行測試,且只有單核心。
Even load 時
- 每個 NF 都有 5 Mpps
Uneven load 時
- NF1: 6 Mpps
- NF2: 6 Mpps
- NF3: 3 Mpps
測試結果
Homogeneous
這情況下每個 NF 平均處理每個封包需要花費 250 CPU cycles。
可以看到 RR 排程器是按封包到達率去分配 CPU time(下右圖↘️)
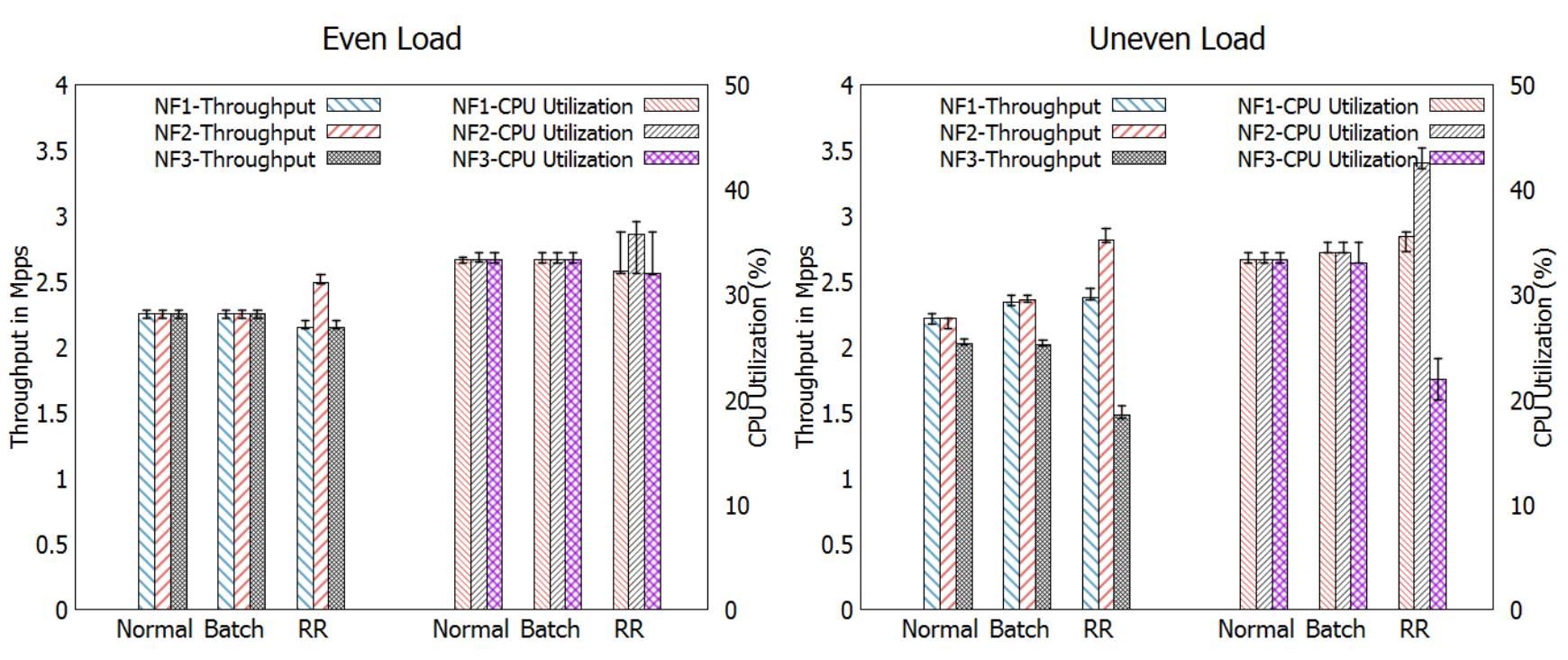
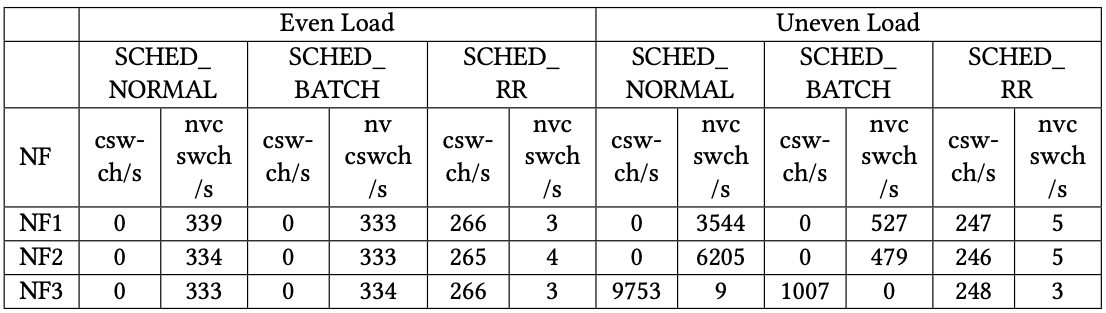
根據上圖,可以發現使用 RR 排程器時,大多都是 voluntary context switch。
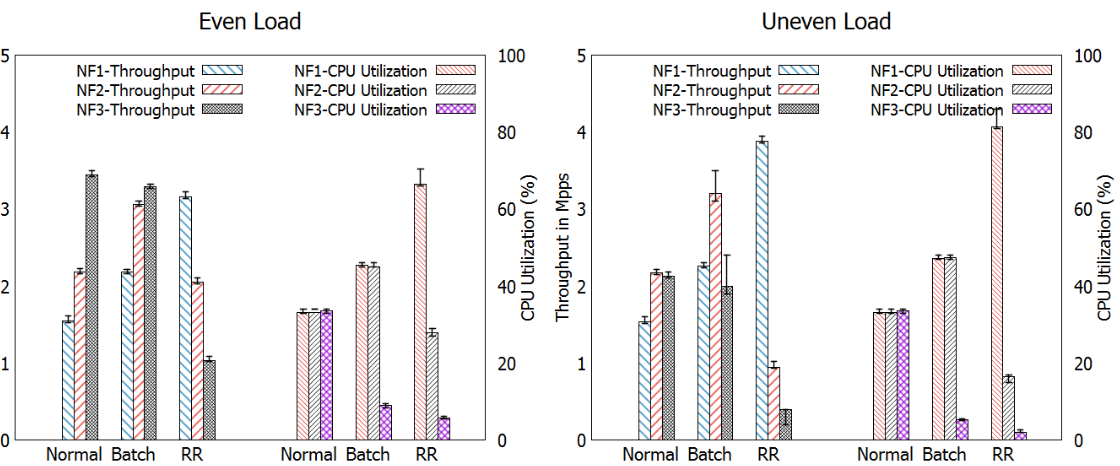
Heterogeneous
這情況下運算開銷為:NF1→ 500, NF2→250, NF3→50 CPU cycles。
明顯地沒有一個排程器能夠達到三者都有公平的輸出。
可以看到 Batch 的 throughput 跟 normal 差不多,但是 NF3 CPU 使用率卻異常的低,這是因為減少了大量的 context switch 進而降低 CPU 開銷。
RR 的結果跟 CFS 完全不同,這是因為 RR 有給每個 NF 相同的機會去執行,但是沒有限制執行的時間,因此會造成 NF3 的 Starvation
編按:為何沒有限制執行時間?為何 Starvation?
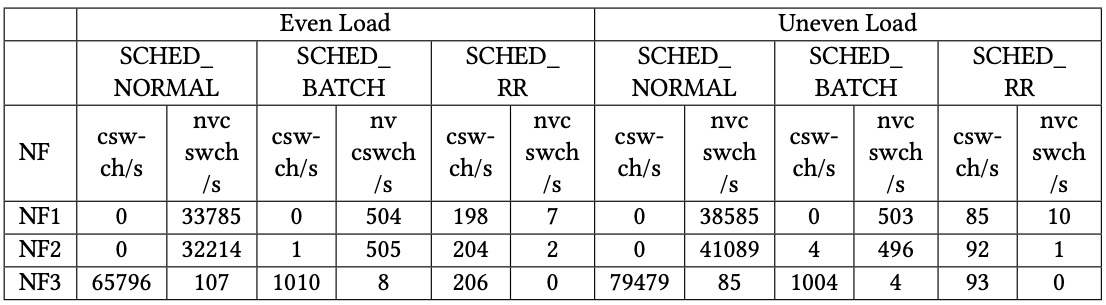
設計與實作
NFVnice 會做的事:
- 監控 NF 平均處理一個封包的時間
- 監控 queue 大小
- 監控 I/O 活動
- NF 在 chain 中的狀態:overloaded, blocked on packet/disk I/O
同時做了一個 lib 來支援 NFVnice 的運作: libnf
- 高效讀寫封包
- overlapping processing with non-blocking asynchronous I/O
- schedule/deschedule a NF
由於修改 OS schedule 是個頗艱難的事情,後續維護也是個難題,因此本篇不做這件事。
其中一個方法是根據 queue 的長度來決定 NF 的優先權(透過 system call),因此當 a NF 取得最高優先權並將封包處理完後,換給 b NF 執行時,此優先權就會轉移給 b。作者相信如此頻繁的更改所造的延遲會導致不穩定。此情況在複雜的 service chain 中會更加嚴重,像是 a NF 同時是某個 chain 的上游,又同時是另一個 chain 的下游。
NFVnice 有使用到 cgroups 去處理排程問題。
系統組成
NF 排程
NFVnice 使用 Linux 原生的 CFS Batch,並透過其 NF Manager 呼叫 cgorups 安排 shared CPU cores 大幅地提高排程效率。
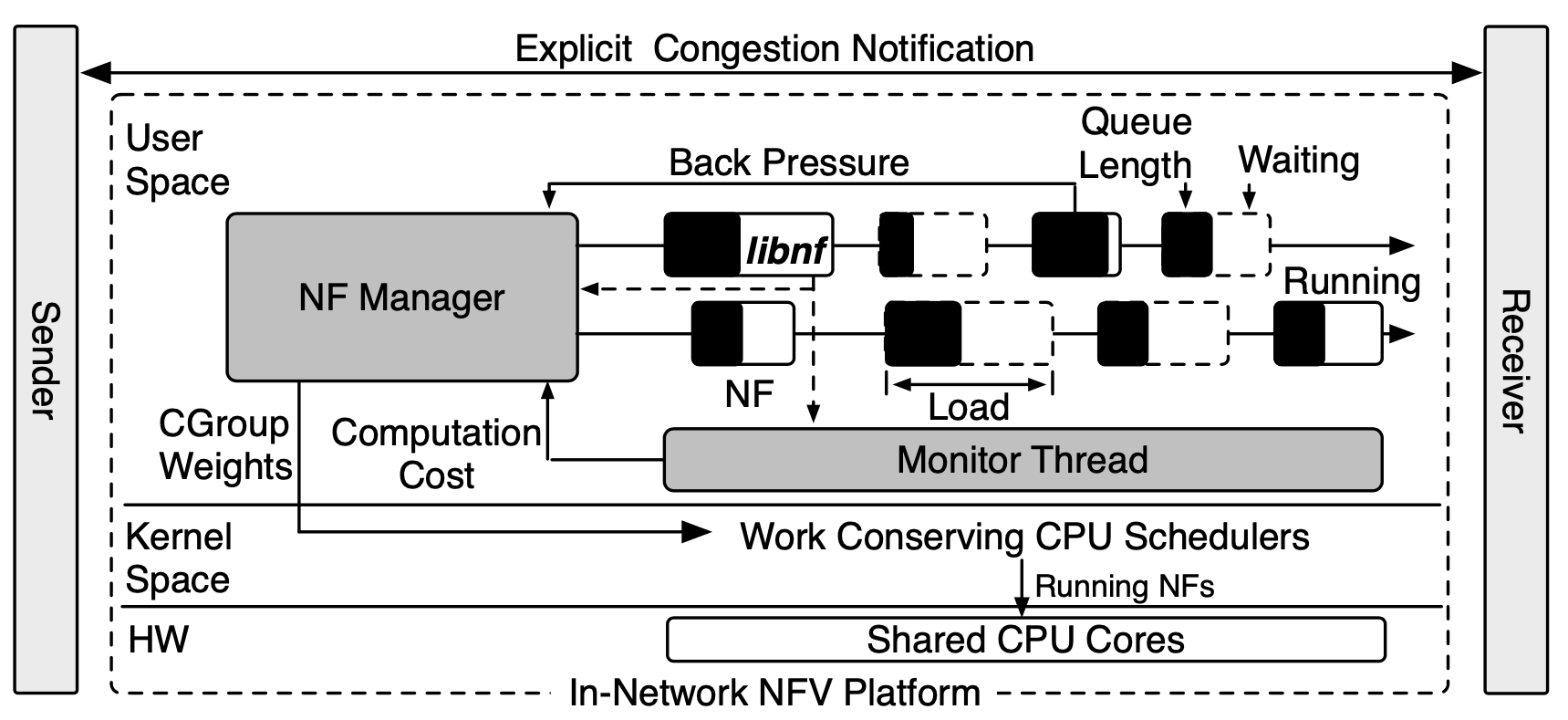
Activating NFs
NF 總是在 busy wait(因為 poll mode),如此是很浪費 CPU 的行為,因此設計出一套系統讓 NF 只會在封包到達時被喚醒是很重要的事,目前 netmap、ClickOS 都已經做到。
不過呢,他們作法太過簡略,只有開跟關兩種模式,不能做更加複雜的管理控制,這會導致不公平的 CPU 資源分配。
在 NFVnice 中,NF 的休眠是藉由 semaphore 來 block 的,此 semaphore 與 NF Manager 共享。此控制會參考該 NF queue 中的數量,以及其下游 NF 們的 queue 狀況來決定是否放行。
如此就不需要將 NF 資訊提供給系統排程器,也可以間接的影響其排程。
Relinquishing the CPU
NF 在處理完一個 batch 後(最多 32 個封包),會決定要不要繼續處理下一個 batch,這都透過呼叫由 libnf 所提供的介面來判斷。
檢查 NF manager 在 shared memory 中設定的 flag,如果被設定了就會在 semaphore 上 block 直到收到 Manager 的通知。
如此提供了一個簡便的方式去要求 NF 放棄 CPU 資源,而不用使得 kernel 的 CPU scheduler 需懂得 NF 的一些資訊。
CPU Scheduler
同時間可能有多個 NF 在執行,排程器得決定單一時間內哪個 NF 該執行、執行多久。
然而作者發現即時同步 NF 資訊給 kernel 消耗太多資源,弊大於利。
Linux CFS Batch scheduler 通常用於長時間運行高計算量的工作,因為有較少的 context switch。
由於 NFVnice 會仔細地控制 NF 們的執行狀況、yield 時間,有較長的 timeslice、較少的 preemption 會比較好。
在大多數情況下,NF 放棄 CPU 是因為 Manager 的政策,而不是非自願性的 context switch。
Assigning CPU Weight
NFVnice 會即時估計每個 NF 的平均 CPU 需求,以調整排程權重。
為了避免極端值影響整體統計狀況,作者有維護一個直方圖(histogram)來預估不同比例時的 service time。
對於每個 shared core 上的 NF $i$ ,可以計算 $load(i)=\lambda_{i} * s_{i}$,其中 $\lambda$ 為 arrival rate,$s$ 為 service time,因此該核心 $m$ 的總共負載為: $$TotalLoad(m) = \mathop{\sum_{n}^{i=1}}load(i)$$ 若要控制核心 $m$ 上 $NF_i$ 的 CPU shares 則可以透過:
$$Shares_i = Priority_i * \frac{load(i)}{TotalLoad(m)}$$
Backpressure
NFVnice 的其中一項重點目標是減少浪費,像是如果在下游會被 drop 的封包,不如就在上游先 drop。作者使用 backpressure 來達成這樣的訴求,可以快速偵測瓶頸,減少 HOL blocking 的影響。
Cross-Chain Pressure
當有個 NF Manage 的 TX thread 偵測到 NF 接收 queue len 已經超過 high watermark、queue time 也超標時,會去檢驗該 NF queue 中所有的封包,以確認這些封包屬於哪些 chain,此時會將封包從最上游開始阻擋,直到 queue len 降低到 low watermark 之下才會重新啟用,如此有遲滯效應(hysteresis control)的關係可以減少模式的切換。
註:這邊用 HIGH_WATER_MARK 等用語,似乎作者之前玩過 Adaptive Communication Environment (ACE),是一套開源 C++ 網路應用程式開發套件,可增加可移植性、更好的軟體品質
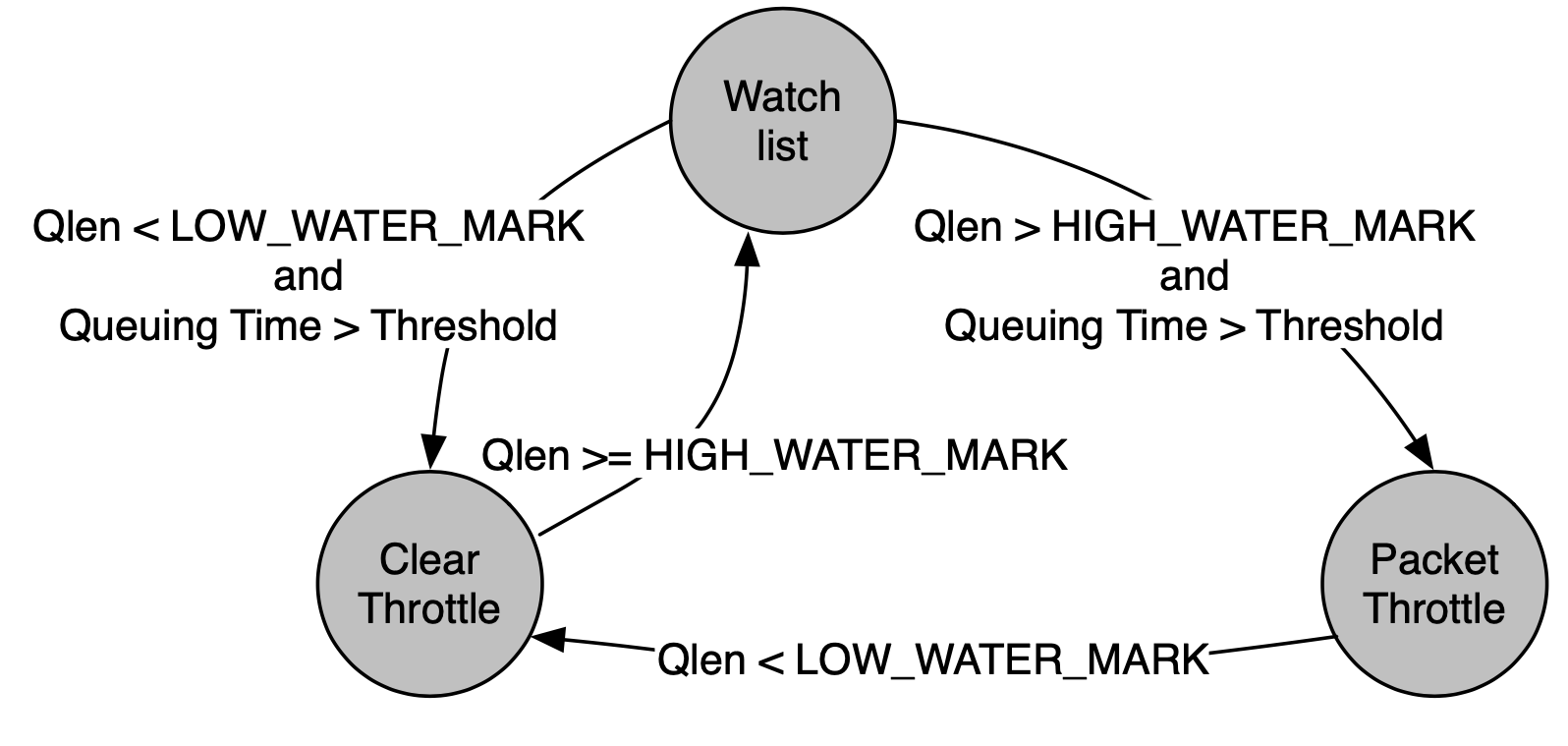
Local Optimization and ECN
NFVnice 也有提供簡單版的 local backpressure,像是 NF 的 output TX queue 滿了的時候會 block,這會發生在:
- 下游 NF 處理緩慢
- 負責這 queue 的 NF Manager TX Thread 超載
這全都是由 NF 自主觸發,不需經由 manager,因此用來解決 short burst、manager 超載時很好用。
作者考慮到 NFVnice middlebox 有可能只是跨越多台主機的鏈的其中一台主機,因此為了有效進行擁塞控制,也有採用 ECN 方式來緩解。
Facilitating I/O
當一個 NF 堵塞時,可能的原因有:
- ring buffer 為空
- 等待 I/O 請求完成
// Read the next packet from the receive ring buffer
packet_descriptor* libnf_read_pkt();
// Output the processed packet to specified destination
int libnf_write_pkt(packet_descriptor*);
// Enqueue request to read from storage. Flow specific data can be stored in context
int libnf_read_data(int fd, void *buf,
size_t size, size_t offset,
void (*callback_fn)(void *), void *context);
// Enqueue request to write to storage. Flow specific data can be stored in context
int libnf_write_data(int fd, void *buf, size_t size, size_t offset,
void (*callback_fn)(void *), void *context);
當呼叫 libnf_read_pkt 時,如果 receive ring buffer 為空,則 libnf 會通知 manager 將此 NF block 住,直到有新封包到來。
加大(雙倍)buffer 大小,可以妥善運用 asynchronous 的優點,在當前封包處理阻塞時處理其他未受阻的封包。
編按:作者這邊沒有說明清楚是同個 NF 嗎? 我猜只要不同 flow 就行
最佳化
分離超載偵測、控制
由於 NFV 平台每秒需要處理數以百萬計的封包,作者將偵測與控制機制分開。
編按:有差嗎?
NF Manager 的 Tx 執行緒會在 NF queue 低於 high watermark 時將封包送入其 Rx queue,同時從返回值獲取 queue 的狀態,並將其存在 NF 的 meta data 中。
控制機制是由 NF Manager 的 Wakeup 執行緒負責,會掃描所有 NF 並分為兩類:
- 需要套用 backpressure 機制
- 需要被喚醒(need to be woken up)
同時也有提供 hysteresis control 的機制,不過作者並無詳加說明。
分離負載評估、CPU 分配
前面有提到負載的計算是: load = packet_arrival_rate * per-packet_processing_time
由於資源排程需要修改 sysfs (cgroups),這很重要,因此需與處理封包的 data path 分離。
編按:有差嗎?
libnf 僅收集封包處理時間,而NF Manager 會計算負載並分配 CPU shares。
位處 data plane 的 libnf 只做每毫秒一次的輕量取樣,方法是透過查看 NF 的封包處理函數在處理前後的 CPU cycle 計數器,並將其存在直方圖當中(histogram),在記憶體中與 libnf、NF Manager 共享。
為了量測準確,採用 100 ms 的 moving window 取中位數,並在每 10 ms 更新一次 cgroup 用的權重。
評估
測試環境
設備
- CPU: E5-2697, RAM: 157 GB, OS: Ubuntu with Linux kernel 3.19.0-39-lowlatency
- back-to-back dual-port 10 Gbps DPDK compatible NICs(避免 switch overhead)
- Traffic generator
- Moongen
- Pktgen
- Iperf3
- Scheduler
- Round Robin (RR)
- SCHED_NORMAL (termed NORMAL henceforth)
- SCHED_BATCH (termed BATCH)
因為透過 NF Manager 排程喚醒,NF 都是 interrupt driven。每次都是自願的 yield,然而在 transmit ring (TX queue)滿了的時候,NF 會暫停封包的處理直到有空間為止。
效能
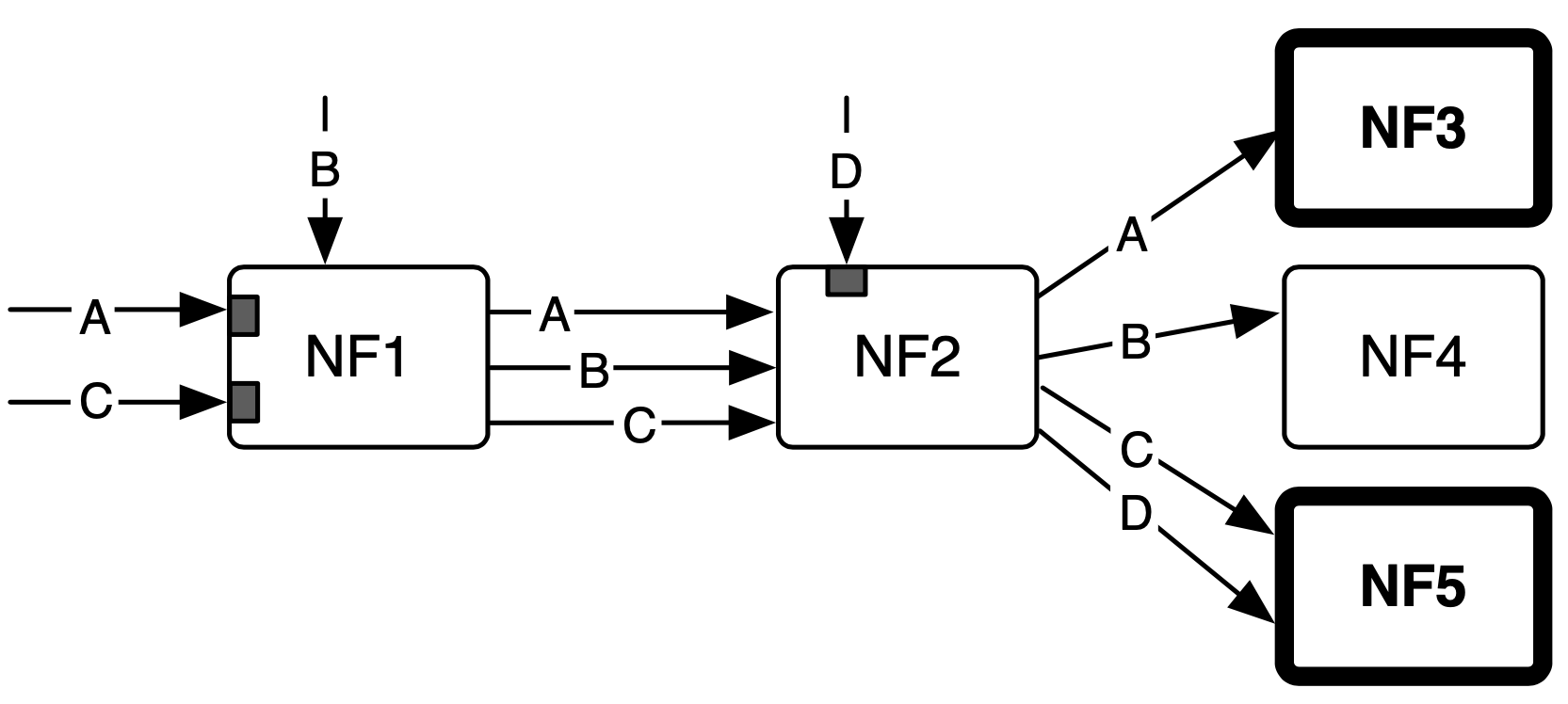
單核心上的 chain
作者給了一個 chain:
- NF1: 120 cycles
- NF2: 270 cycles
- NF3 550 cycles
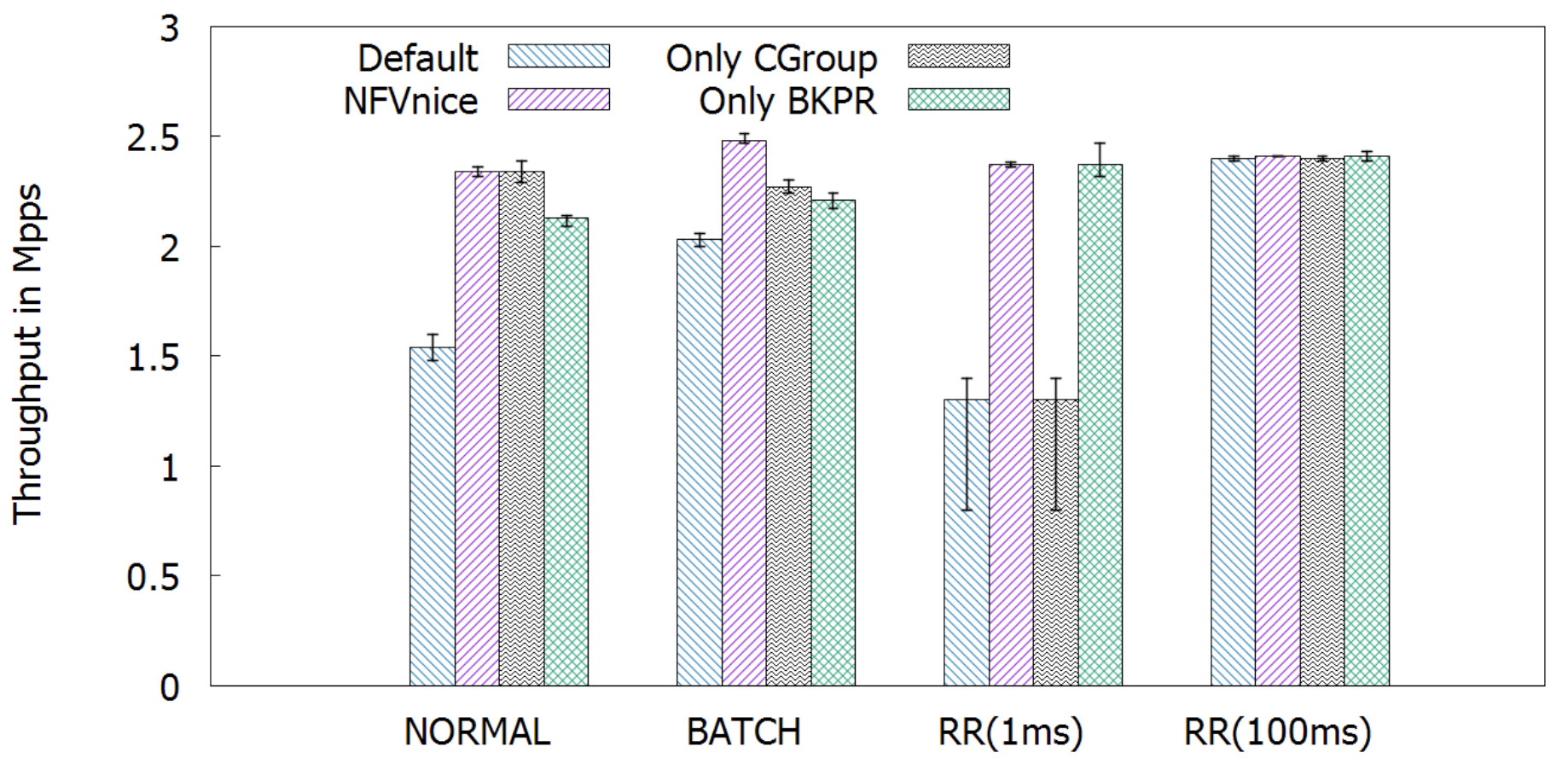
從上圖可以看到 NFVnice 的 through 表現最好(尤其是在 RR 1ms 的時候),為了更加清楚 cgroups、backpressure 的貢獻,作者將兩者獨立出來。可以看到 backpressure 的貢獻最多。
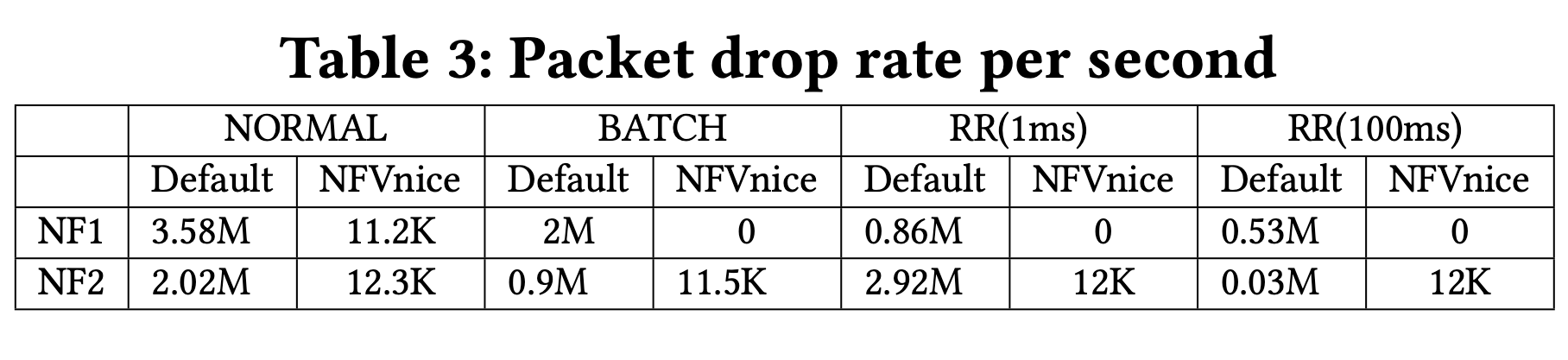
上表可以看到 default 的 drop rate 是以百萬在計算的,而 NFVnice 只有以萬在做計算,甚至有些是 0。因此可以確定 NFVnice 可以有效的避免資源浪費,正確的分配 CPU 資源。
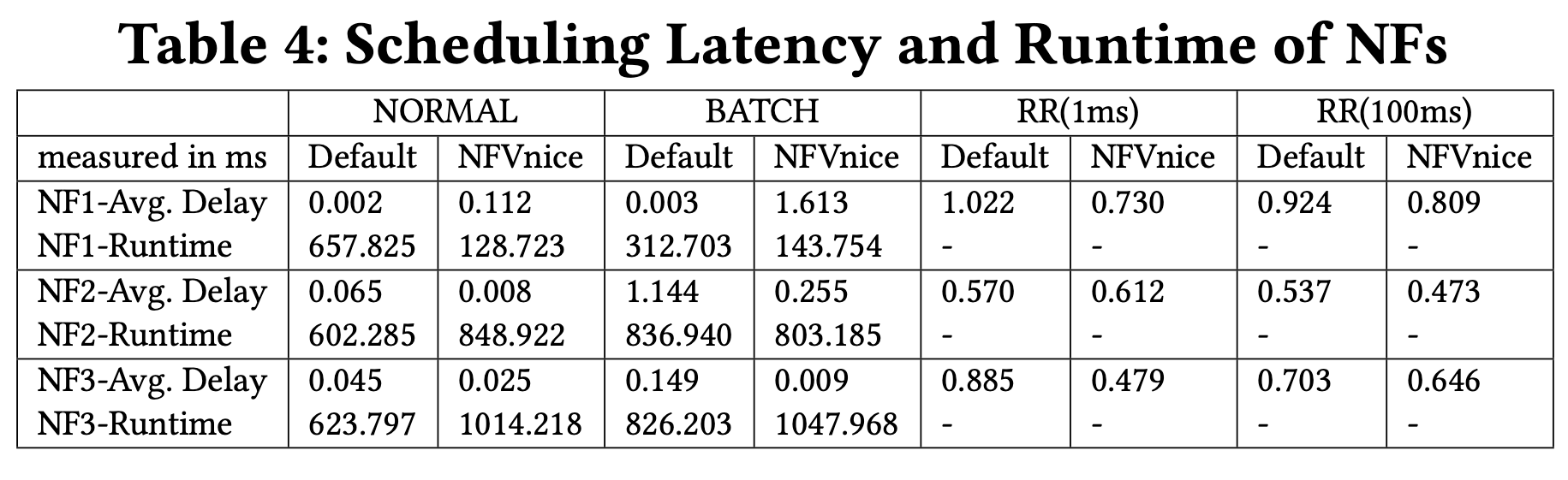
首先可以看到 Runtime (執行時間)的部分,只有 NFVnice 有按照不同 NF 所需的處理時間去分配資源,這才不會造成後續的 NF 因為資源不足 drop 封包。
再來是 schedulig Delay(從封包到達到開始處理的時間),平均延遲是 NFVnice 比較低,但作者沒說明為何 NF1 的 delay 都會比較高,我猜是沒封包就被休眠的關係。
多核心擴展
作者用此展現 NFVnice 的資源分配能力與避免浪費的能力。
有條 chain 上面有三個 NF,CPU cycles 數量分別為:550, 2200, 4500,分別分配在三個不同的核心上。
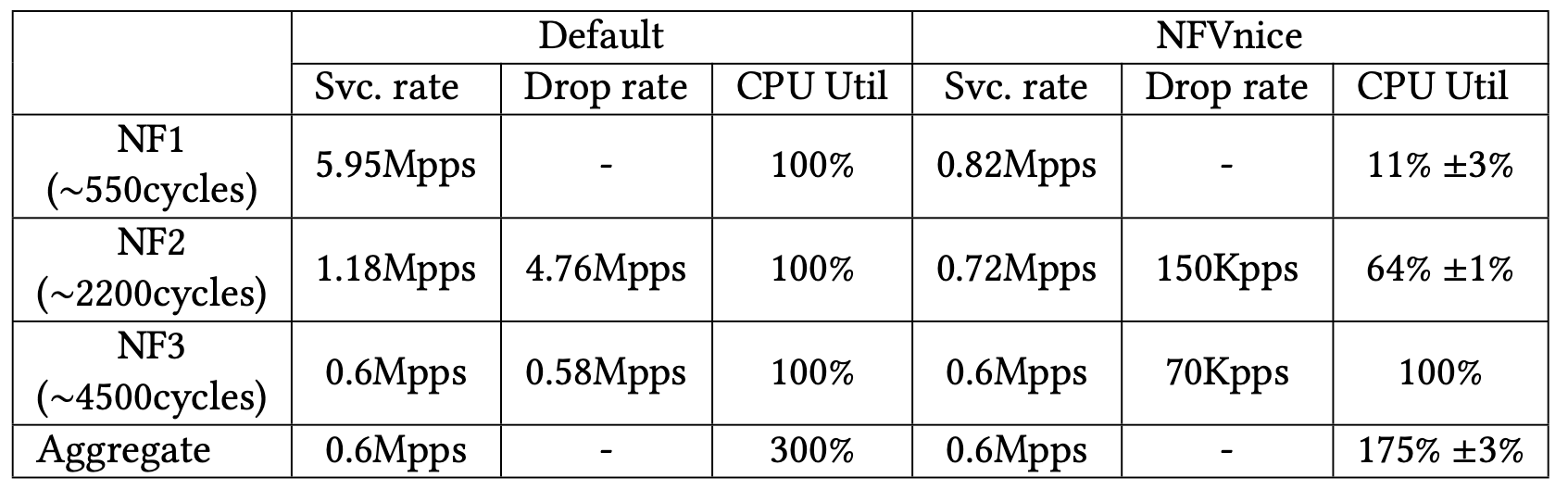
可以看到在 NFVnice 那邊,雖然 NF1、NF2 的 CPU 使用率不高,但是總產出與 Default 一樣。
再來作者考慮另一個情境,使用兩條 chain 分配在四顆核心上
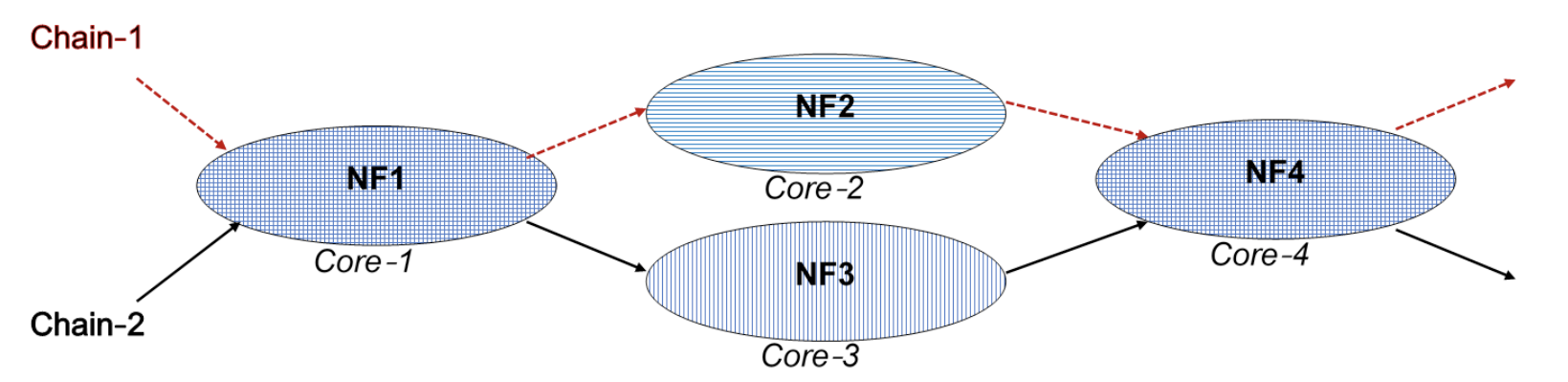
使用 Moogen 平均分配流量到兩條鏈上:
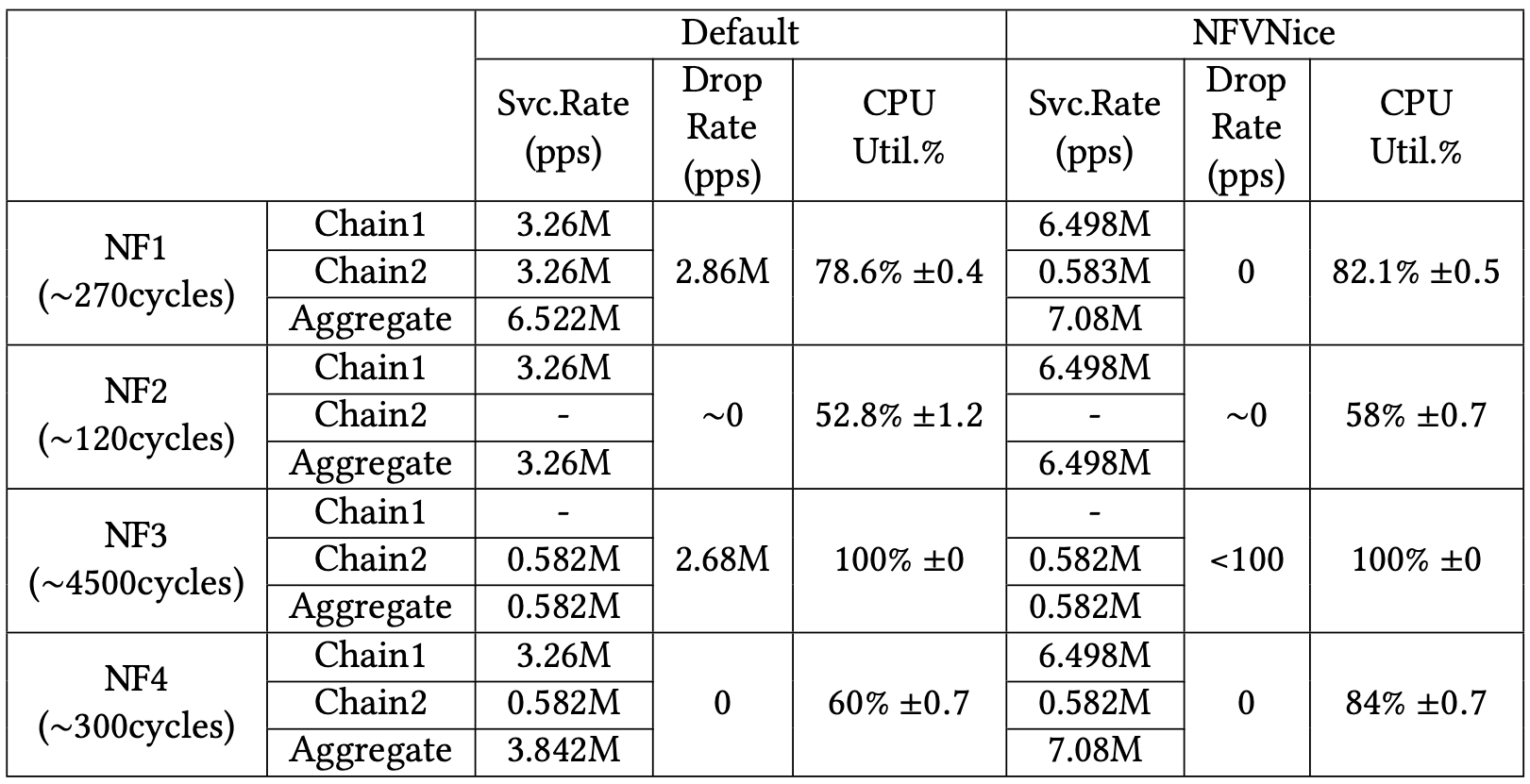
可以看到在 Default 排程底下的 NF3 丟包許多,因此在 NFVnice 中就減少 chain 2 在 NF1 處理封包的量,相對增加 chain 1 在 NF1 的處理量,進而提升整體產出👍。
也就是 NFVnice 不只減少浪費,還促進資源分配。
編按:但作者沒說為何 NF1 的 CPU 沒有滿?🤔
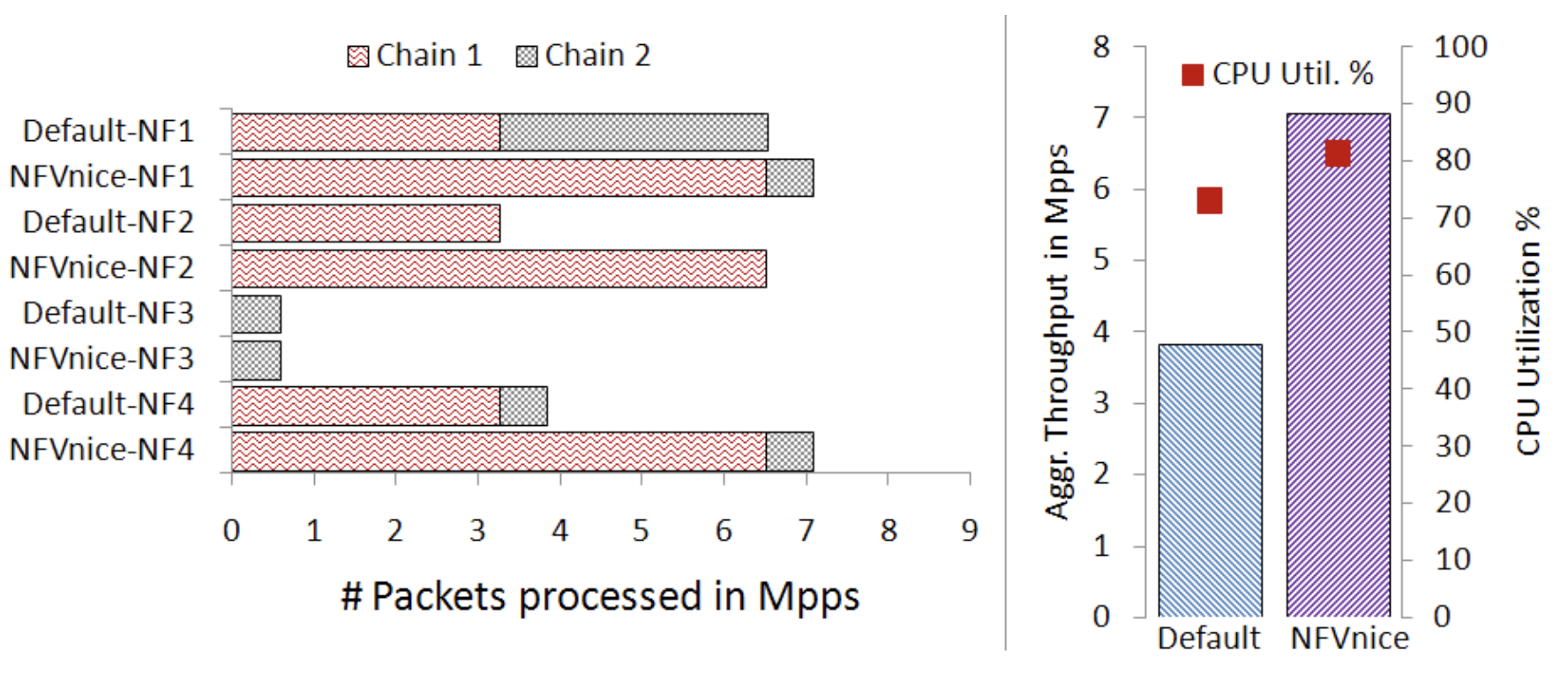
NFVnice 顯著的特色
可變封包處理開銷
這次使用一條鏈,三個 NF,但是對每個 NF 來說封包處理開銷可能會有 120, 270, 550 這三種可能,因此單位時間內總共會有 9 種狀況發生。
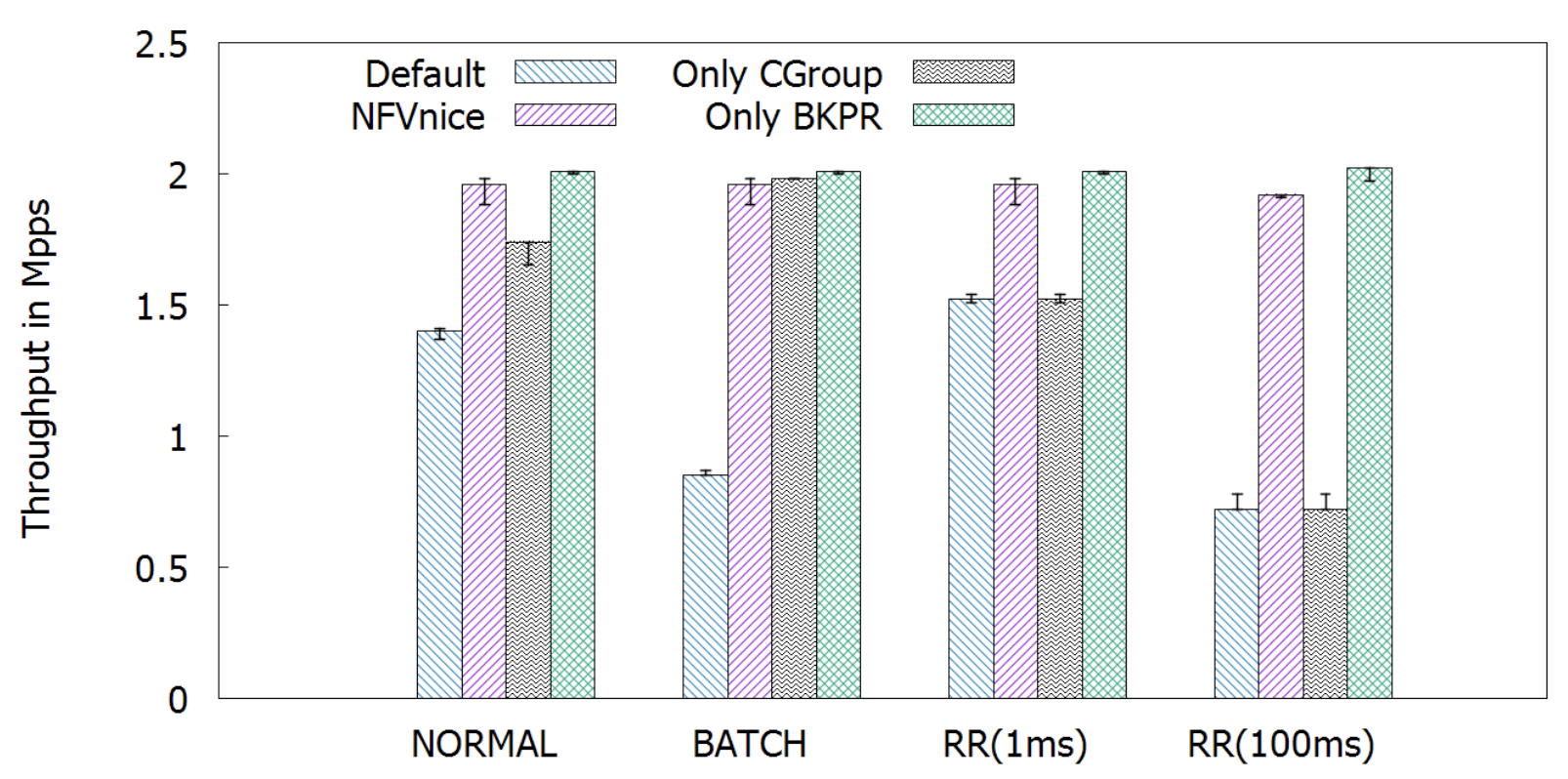
左圖是之前看到固定 CPU cycle 處理的圖表,右圖是這次實驗的圖表。
由於不固定長度,因此不好預測 NF 處理封包的時間,cgroups 在 RR (100ms) 表現奇差。
然而對 backpressure 卻沒什麼影響,也因為 NFVnice 有使用 backpressure 因此受到的影響不多。
作者說經過仔細精確的調整後可以讓 NFVnice 受到的影響更低,但也會消耗更多運算資源,有點得不償失。
異質 Service Chain (Service Chain Heterogeneity)
這次也是一條鏈,三種高中低不同花費的 NF,因此總共有 3! = 6 種可能。
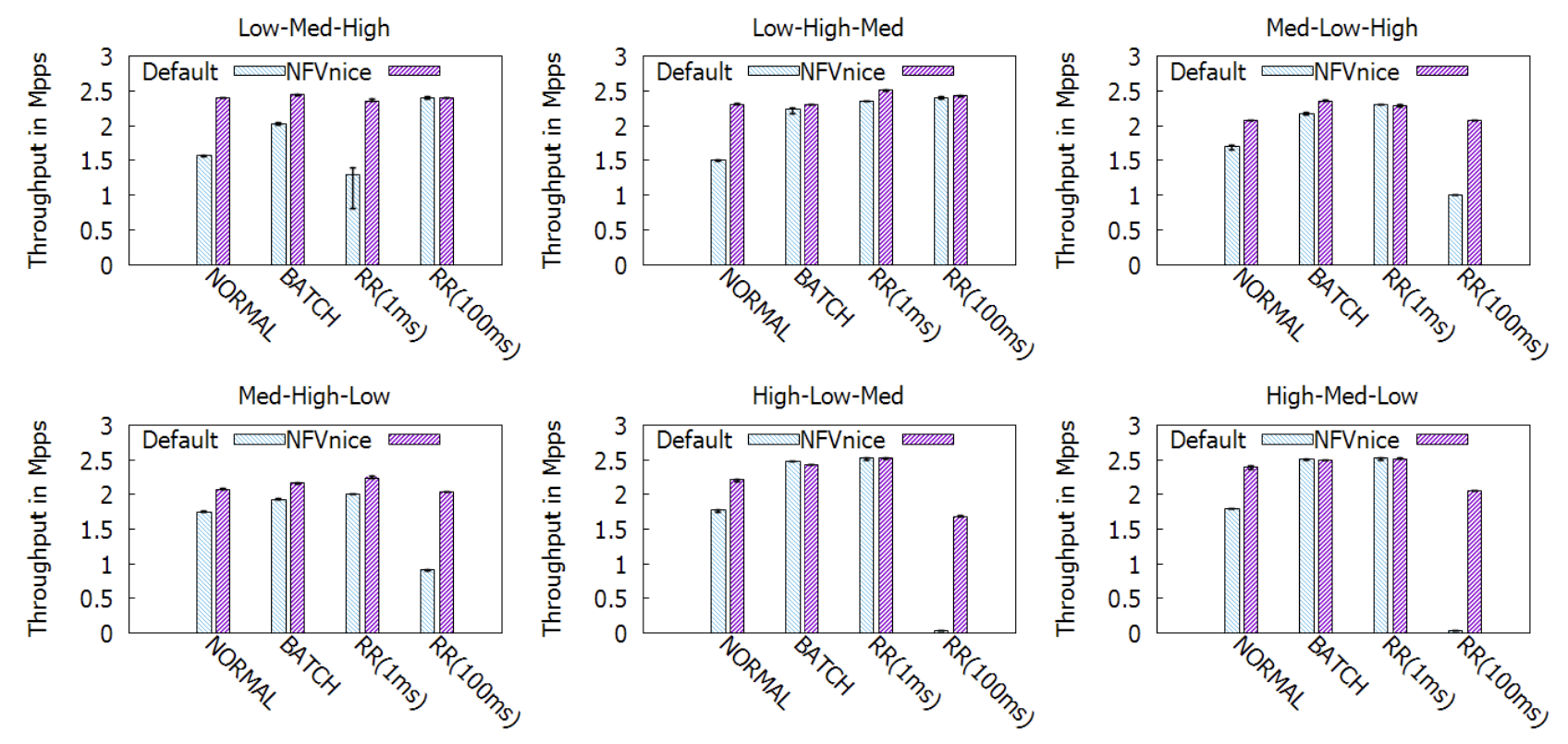
NORMAL 跟 Batch 的表現相仿,原因在第二章節有提到,因為他們兩種排程器主要差異只有在 timeslice 的大小。
至於兩個 RR 的表現則是完全相反:小 timeslice 的在瓶頸在上游時表現較好(在下游的話處理不來就被丟包了),大 timeslice 的在瓶頸在下游時表現較好(若瓶頸在上游則所有資源都卡在上游而沒時間處理下游)。作者說這原因是因為資源浪費、資源分配不均所造成的。
異質工作量 (Workload heterogeneity)
這次使用三個相同開銷的 NF,只是順序不同,因此有 3! = 6 的連接順序,這會使得不同 flow 的走向會導致不同瓶頸點的產生。
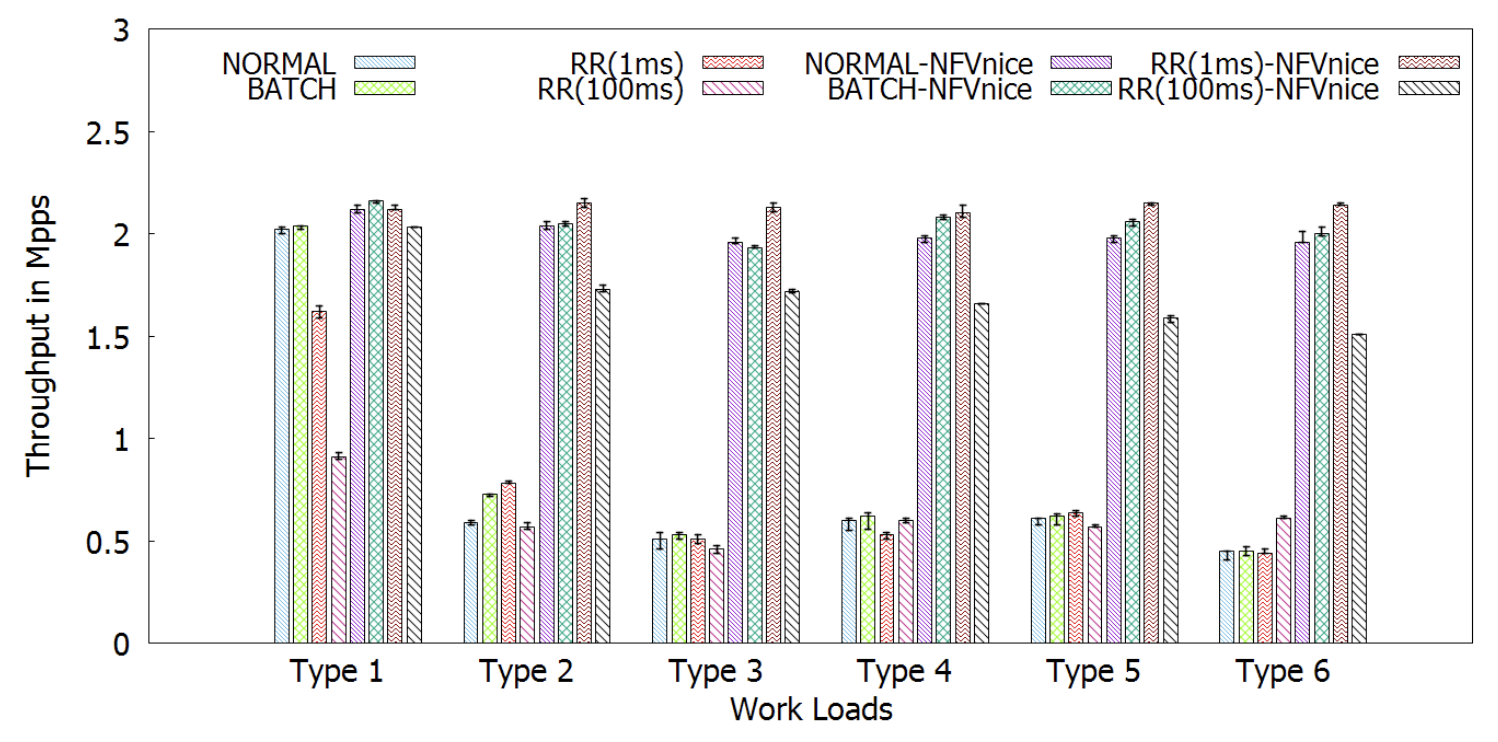
可以看到如果大於一條 flow 的時候,因為有了瓶頸的產生,原生的處理方式效能就很差。
Performance isolation
當 TCP 流與 UDP 流共處時,由於 TCP 有擁塞控制機制會減少傳送量,但是 UDP 沒有因此會一直不停地送,導致 TCP 流量會不斷地減少。作者說這在基於軟體的環境會更加嚴重
編按:為何會更加嚴重?
實驗環境為 1 條 40 Gbps TCP 流經由 (NF1, NF2),在第十五秒時開始出現 10 條 UDP 流經由 (NF1, NF2, NF3),並在 NF3 時遇到瓶頸 (280 Mbps) 因此大多數在此被丟包,並在 40 秒時停止傳送 UDP。
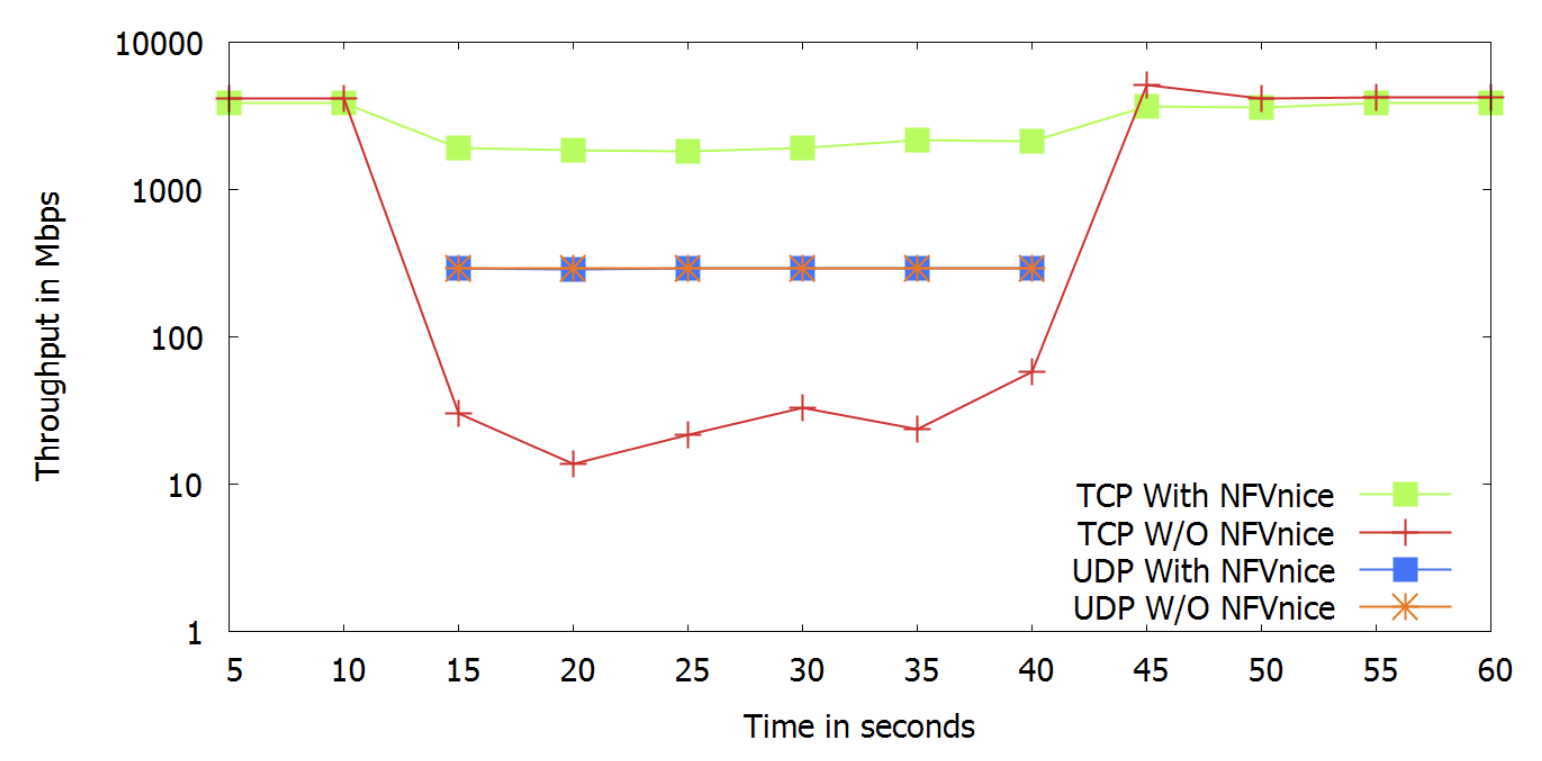
所幸 NFVnice 的 backpressure 機制,會抑制在下游遭遇瓶頸的 UDP flow,因此在上游就先把 UDP 擋掉,才不會影響到 TCP。
有 NFVnice 的話 TCP 輸出還有 3.3 Gbps,沒有的話則剩下 20 Mbps。
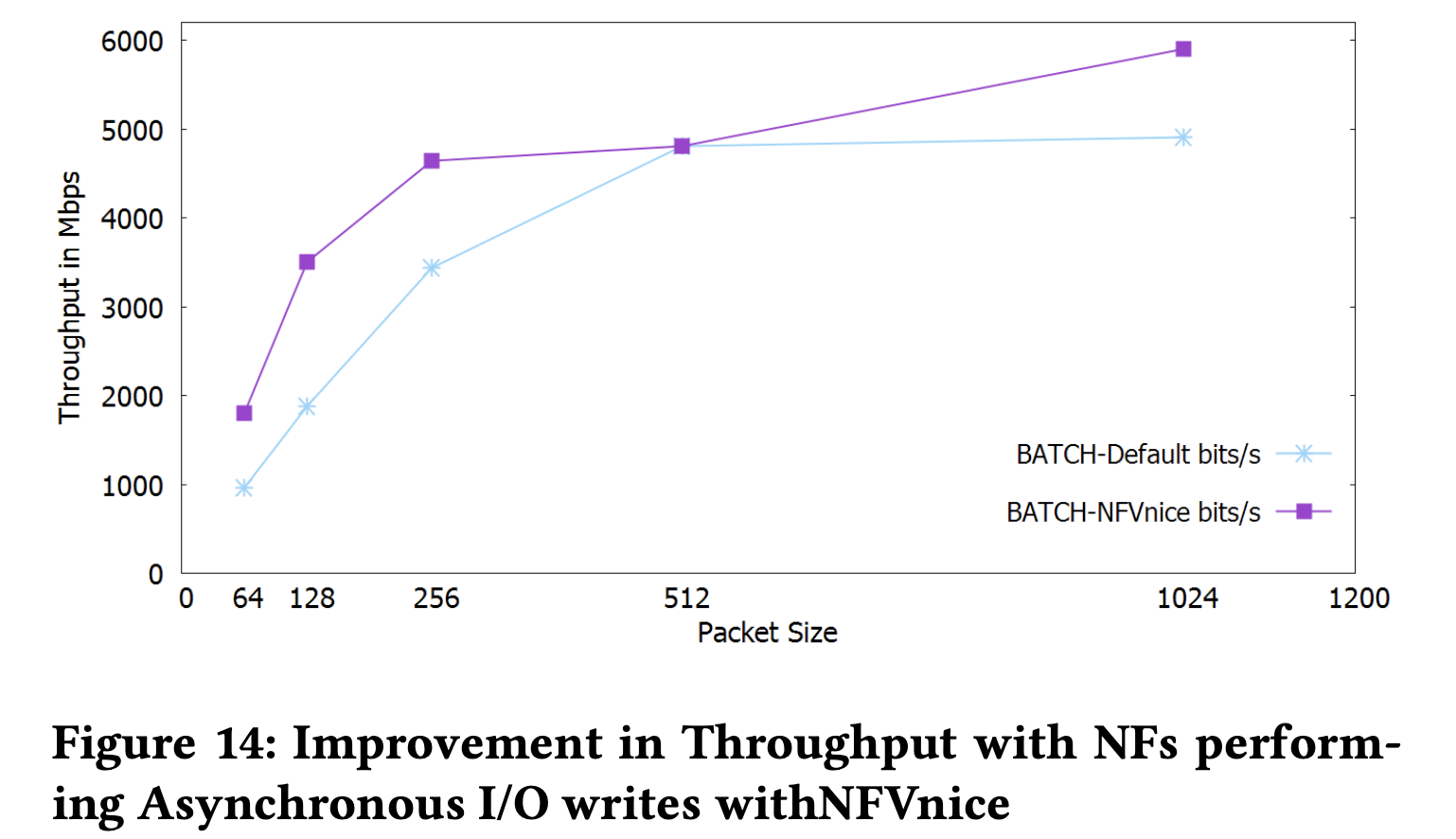
有效率的 I/O 處理
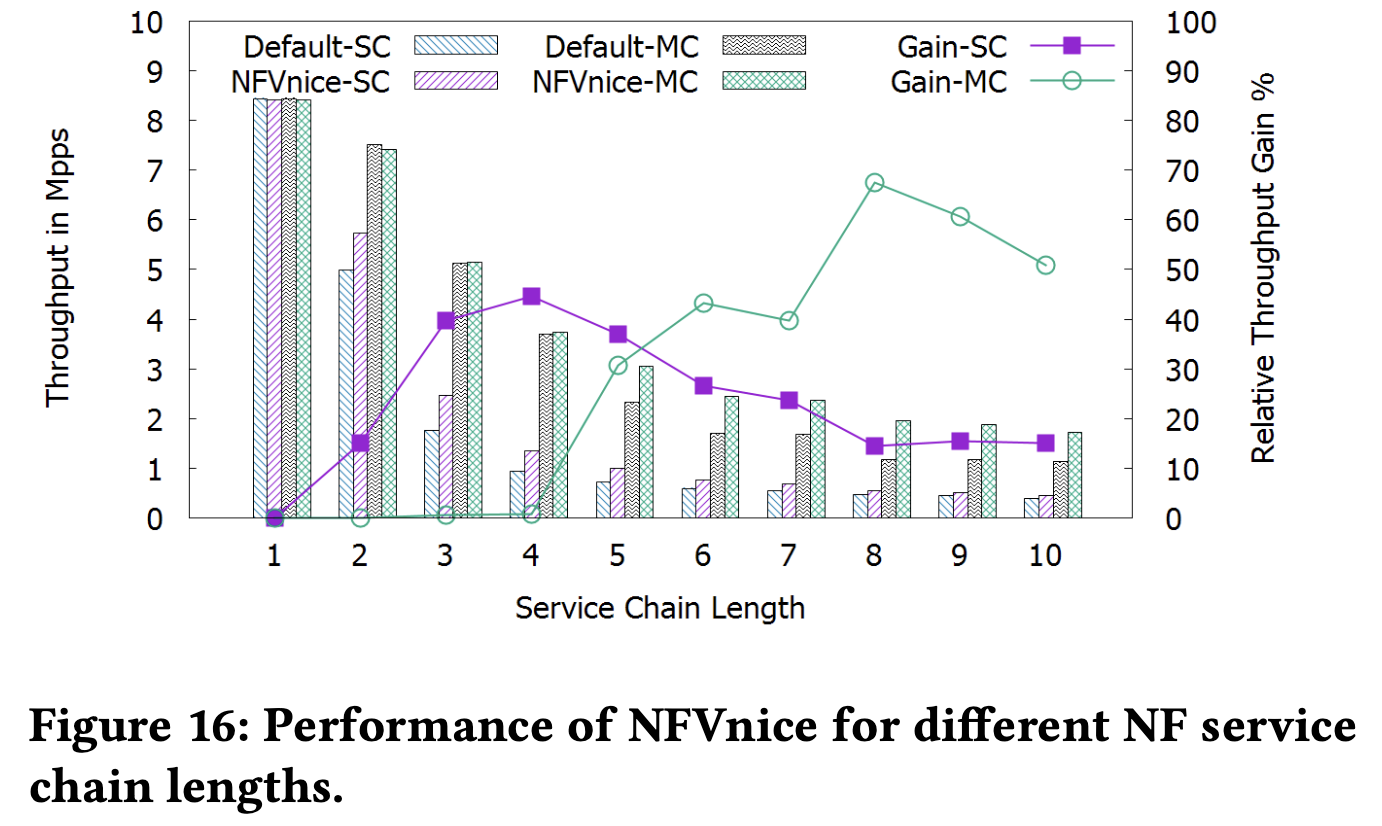
支援長鏈
名詞解釋
head-of-line blocking (HOL blocking)
隊頭阻塞是一種性能受限的現象。它的原因是一列的第一個數據包(隊頭)受阻而導致整列數據包受阻。
例如它有可能在緩存式輸入的交換機中出現,有可能因為傳輸順序錯亂而出現,亦有可能在HTTP流水線中有多個請求的情況下出現。
nice(Linux 指令)
每個執行中的程式都會有一個 niceness 值,系統的 scheduler 在對每個行程在排程時,就會參考這個數值來決定執行的先後順序,但實際決定的是 priority 值,nice 可以影響 priority,但 scheduler 可能會忽略 nice 值。
最高優先為 -20,最低優先為 19,0 以下必須使用 root 權限。
實際效益:
計算方式為 20 - p
A 程式 nice: 0,B 程式 nice: 15
則 CPU time 分配比例為: (20-0) / (20 - 15) = 4
最大差距為: (20 - (-20)) / (20 - 19) = 40
設定程式 nice:nice -n <nice_value> ./myProgram
Priority
PR is the priority level (range -100 to 40)
normal process: PR = 20 + NI (NI is nice and ranges from -20 to 19)
real time process: PR = -1 - real_time_priority (real_time_priority ranges from 1 to 99)
在 top 指令中,PR 欄位越低優先權越高,RT 代表 PR 為 -100。
參考資料:Linux 系統調度簡介
cgroups
control gorups 是 Linux 核心提供的一種機制,這種機制可以根據需求把一系列系統任務及其子任務(process group)整合或、分隔到按資源劃分等級的不同組內,從而為系統資源管理(CPU, RAM, Disk I/O)提供一個統一的框架。
簡單說,cgroups 可以限制、記錄任務組所使用的物理資源。本質上來說,cgroups 是核心附加在程式上的一系列鉤子(hook),通過程式執行時對資源的排程觸發相應的鉤子以達到資源追蹤和限制的目的。
功能:
- 資源限制: 可以對任務是要的資源總額進行限制
- 優先級: 分配的 CPU 時間片數量和磁碟 IO 頻寬,實際上就等同於控制了任務執行的優先順序
- 資源統計: 用來度量系統實際用了多少資源,比如 CPU 使用時長、記憶體用量等。這個功能非常適合當前雲端產品按使用量計費的方式。
- 控制: cgroups 可以對任務執行掛起、恢復等操作。
相關概念:
- Task (任務)
- 在 Linux 系統中,核心本身的排程和管理並不對程序和執行緒進行區分,只是根據 clone 時傳入的引數的不同來從概念上區分程序和執行緒。這裡使用 task 來表示系統的一個程序或執行緒。
- Cgroup (控制組)
- cgroups 中的資源控制以 cgroup 為單位實現。Cgroup 表示按某種資源控制標準劃分而成的任務組,包含一個或多個子系統。一個任務可以加入某個 cgroup,也可以從某個 cgroup 遷移到另一個 cgroup。
- Subsystem (子系統)
- cgroups 中的子系統就是一個資源排程控制器(又叫 controllers)。比如 CPU
子系統可以控制 CPU 的時間分配,記憶體子系統可以限制記憶體的使用量。( cat /proc/cgroups):
- blkio
- 對塊裝置的 IO 進行限制。
- cpu
- 限制 CPU 時間片的分配,與 cpuacct 掛載在同一目錄。
- cpuacct
- 生成 cgroup 中的任務佔用 CPU 資源的報告,與 cpu 掛載在同一目錄。
- cpuset
- 給 cgroup 中的任務分配獨立的 CPU(多處理器系統) 和記憶體節點。
- devices
- 允許或禁止 cgroup 中的任務訪問裝置。
- freezer
- 暫停/恢復 cgroup 中的任務。
- hugetlb
- 限制使用的記憶體頁數量。
- memory
- 對 cgroup 中的任務的可用記憶體進行限制,並自動生成資源佔用報告。
- net_cls
- 使用等級識別符(classid)標記網路資料包,這讓 Linux 流量控制器(tc 指令可以識別來自特定 cgroup 任務的資料包,並進行網路限制。
- net_prio
- 允許基於 cgroup 設定網路流量(netowork traffic)的優先順序。
- perf_event
- 允許使用 perf 工具來監控 cgroup。
- pids
- 限制任務的數量。
- blkio
- cgroups 中的子系統就是一個資源排程控制器(又叫 controllers)。比如 CPU
子系統可以控制 CPU 的時間分配,記憶體子系統可以限制記憶體的使用量。( cat /proc/cgroups):
- Hierarchy(層級)
- 層級有一系列 cgroup 以一個樹狀結構排列而成,每個層級通過繫結對應的子系統進行資源控制。層級中的 cgroup 節點可以包含零個或多個子節點,子節點繼承父節點掛載的子系統。一個作業系統中可以有多個層級。
CPU Shares
為 cgroups 中 CPU subsystem 中的一項設定,預設值為 1024。
假如系統中有兩個 cgroup,分別是 A 和 B,A 的 shares 值是 1024,B 的 shares 值是 512,那麼 A 將獲得 1024/(1204+512)=66% 的 CPU 資源,而 B 將獲得 33% 的 CPU 資源。shares 有兩個特點:
- 如果 A 不忙,沒有使用到 66% 的 CPU 時間,那麼剩餘的 CPU 時間將會被系統分配給 B,即 B 的 CPU 使用率可以超過 33%
- 如果添加了一個新的 cgroup C,且它的 shares 值是 1024,那麼 A 的限額變成了 1024/(1204+512+1024)=40%,B 的變成了 20%
從上面兩個特點可以看出:
- 在閒的時候,shares 基本上不起作用,只有在 CPU 忙的時候起作用,這是一個優點。
- 由於 shares 是一個絕對值,需要和其它 cgroup 的值進行比較才能得到自己的相對限額,而在一個部署很多容器的機器上,cgroup 的數量是變化的,所以這個限額也是變化的,自己設定了一個高的值,但別人可能設定了一個更高的值,所以這個功能沒法精確的控制 CPU 使用率。
ECN, ECE, CWR
顯式擁塞通知 Explicit Congestion Notification
具備 ECN 功能的主機為具備 ECN 功能的 TCP 連線傳送 TCP 區段,其 IP 標頭中的 ECN 欄位設定為 10 ( ECT0) ) 或 01 ( ECT(1) );具備 ECN 功能而且遇到擁塞的路由器會將 IP 標頭中的 ECN 欄位設定為 11。
當接收端 TCP 對等體傳送 ACK (其中包含 ECN 欄位設定為 11 (CE, Congestion Encountered) 的已接收 TCP 區段) 時,會設定 TCP 標頭中的 ECE 旗標,並繼續在後續 ACK 中設定 ECE 旗標。
當傳送主機接到設定了 ECE 旗標的 ACK 時,所表現的行為就好像已經捨棄了封包,開始縮減其傳送視窗,並執行慢速啟動演算法及擁塞避免演算法。在下一個區段,傳送端會設定 CWR 旗標。在接到設定了 CWR 旗標的新區段時,接收端會停止在後續 ACK 中設定 ECE 旗標。
為何使用 low-latency kernel
real time 需求的人,像是聲音錄製
如果一般用途的人用了會發現效能嚴重下降,因為 context switch 增加了許多。
RDTSC 指令
CPU 的 timestamp,這個 timestamp 會記錄從上次重設後的 clock cycle 數。
自從 Intel Pentium 加入 RDTSC 指令以來,這條指令是 micro-benchmarking 的利器,可以以極小的代價獲得高精度的 CPU 時鐘週期數(Time Stamp Counter)。
comments powered by Disqus