概要
作者使用效能關鍵變數(performance critical variables)配合符號執行(symbolic execution)打造出效能合約(performance contract),在不用實際執行 NF 的狀況下,即可精準的描述 NF 的效能表現。
同時提出了 BOLT 工具用以協助效能合約,只要給出 NF 的程式碼,配合預先分析好的 NF 有狀態函式庫,就可以產生合約。
1. 介紹
NF 的發展從傳統的專用硬體設備逐漸轉向通用伺服器,這個改變帶來了
- 各種彈性
- 減少開發成本
- 加速交付到市場的時間
不過,對於 NF 的效能預估就更加困難了,如果無法準確的預估,對網路供應商在部署上會是個難題,其競爭對手也會藉機尋找漏洞來攻擊使其網路表現下降。
編按:為何無法準確預估會是個攻擊方向呢?
作者對 NF 提出了效能合約的概念:
- $N$:Network Function,可以是某種 NF 的實作
- $i$:封包種類,比如說 $i_1$ 表示有效封包到達 router 的類別
- $U$:效能表現的單位,比如說單一封包處理所需要的 x86 指令數量
- $C_N^U(i)$:合約
這些表達式是由效能關鍵變數(performance critical variables, PCVs)產生而來,其整理統計了 NF 的輸入資料、設定檔。舉例來說,效能合約可以產生函數 $p_1(l)$ 表示在匹配到目的 IP 位址前綴長度為 $l$ 時的效能表現,對於 NAT 來說,PCV 或許會是 flow table 的佔用率(編按:因為 NAT 會需要有 table 記錄內外對應關係)。
在這篇論文中,作者考量到三項效能指標:
- 指令執行量(number of executed instructions)
- 記憶體存取量(number of memory accesses)
- 執行循環次數(number of execution cycles)
整體來說,也就是考量到 NF 的軟體堆疊與硬體架構。
作者從 Vigor(SIGCOMM 2017) 中獲取靈感來源,其假設 NF 的程式碼能做到下面兩種分離,以確保記憶體安全:
- 已事先由專家撰寫、驗證過的常用 NF 資料結構的函式庫(library)
- 由 NF 開法者撰寫,使用函式庫的無狀態 NF 邏輯,透過 Vigor 使用符號執行(symbolic execution)來自動驗證
同樣的概念,BOLT 也需要手動分析常用的資料結構以建立效能合約(編按:當作基底,當有 NF 用到時便可以準確提供)。當有了 NF 的原始碼,且該 NF 有用到已分析的資料結構,便會自動產生 NF 的效能合約,當然也可以重複此動作以計算 NF chain 的效能合約。
為了幫助營運商、開發者駕馭 PCVs,在 BOLT 中有個元件叫做蒸餾器(Distiller),其跟蹤輸入的每一個封包,並且計算目標 NF 所產生的 PCV 值。
作者使用 DPDK 測試效能合約的準確性、可用性,共有四種 NF 都是使用 C 寫的:NAT、Maglev 般的負載平衡器、LPM (long prefix match) 路由器、MAC 橋接器。最大預測誤差為 7%,文末會講解如何降低到 0%。
整體來說,此篇論文有兩項貢獻:
- 提出 NF 效能合約的概念,可以使用 PCV 的函數表達之
- 藉由示範展示 BOLT 所產生的效能合約是準確的、人類可讀的
2. 效能合約
這個章節會提到效能合約的建立,並且使用範例來講解。
2.1 執行範例:LPM Router
下面的虛擬碼是 LPM IPv4 router,會用 Patricia trie(一種 radix tree)儲存轉發表。在第 6 行中,會將不是 IPv4 的封包丟棄,這個動作會有固定的效能開銷。在 lpmGet 中,迴圈的次數會是是依賴於資料的。
function processPacket (packet pkt)
if pkt.etherTYpe == IPv4 then
dst_port = lpmGet (pkt.ipv4.dst_addr)
FORWARD (pkt, dst_port)
else
DROP (pkt)
end
function lpmGet (bit ip[32])
node = lpmRoot
for i in 0..31 do
b = ip[i]
if exists node.children[b] then
node = node.children[b]
else
break
end
end
return node.port
為了方便說明,作者省略掉封包處理框架以及其他無關於 NF 的效能影響。
編按:也就是不考慮 NIC、記憶體等等的狀況
2.2 定義
- $i \in I$,類別,$i$ 可以是所有沒有 option 的 IPv4 封包,域(domain)$I$ 包含了程式 $N$ 的所有輸入空間。
- $p_i (v_1, v_2,…) \in F$,函數 $p_i$ 表示 $N$ 在處理 $i$ 類時的效能表現,$v$ 表示 PCV(其值的單位跟 $U$ 相同)
- $C_N^U:I \rightarrow F$:輸入類別與函數的映射
廣義來說,效能合約可以給任何程式 $P$ 使用,而不只是 NF。
PCVs 可以是除了輸入之外的任何東西,效能的呈現可以透過記憶體存取量、執行週期(execution cycles)數等等指標。
實際效能表現都將不會超過效能合約所預測的效能(預測都以最壞的情壞做打算)。程式 $P$ 可以是 NF chain、單獨的 NF、NF 的一部分、一種資料結構方法(其合約已經由專家得出)。

上圖是 LPM 的效能合約,使用 instruction 與 memory access 兩項指標來表示。
- 如果是處理無效封包,會需要 2 instructions 與 1 memory access。
- 如果是處理有效封包,會用到 $4 \cdot l + 5$ 個 instructions,其 $l$ 代表 IP 前綴長度。
此範例忽略了與 NF 程式碼不相關的所有東西,單一 PCV 指標 $l$ 主導了兩份效能合約。
2.3 合約中 PCV 的主張
設計效能合約時,需要在 合約細節 與 合約易讀性 之間取捨,像是要如何讓人可以簡單地解析、繪製相關表現。
不同的使用者會需要不同的平衡,像是:
- 開發者:會需要多點細節以利偵錯與最佳化程式碼
- 營運商:僅需要知道部署相關的資訊
作者希望在效能合約中能夠揭露實作相關的概念,像是碰撞率、前綴符合長度,這對開發者來說是好事,但對 NF 實作不熟的人恐怕不適合。作者認為在不揭露實作相關的複雜資訊情況下,又能設計出具有意義的效能合約是不可能的。
3. 產生效能合約
這個章節會講到建立效能合約的工具—BOLT。目前的原型指標有三個:指令執行量、記憶體存取量、執行週期數。
介紹順序:採用背景,如何取得資料結構的合約、如何取得整個 NF 的合約、如何取得 NF chain 的合約、一些實作細節。
3.1 背景
概念上來說,最簡單的方式是觀察各式可能的輸入最終造成的行為結果,不過這並不符合真實世界的情形。
一個比較有效率的方式是將各種輸入分群成不重疊的類別,這樣子所有在同個類別的輸入在程式中就會有相同的執行路徑,也就是會有相同的執行行為。舉例來說,如果有一程式允許輸入 64-bit 長度的數字,但只會根據輸入是奇數或偶數而有兩種不同結果,雖總共會有 $2^{64}$ 種可能輸入,但實際上只有 2 類。
符號執行(symbolic execution, SE)是在尋找可行執行路徑、識別輸入類型的常用工具,其依賴於符號執行引擎(symbolic execution engine, SEE),利用符號來表達輸入,並且在程式中傳遞這些符號。
舉例來說,程式中有個 X, Y 變數,SEE 會設定一個 $\alpha$ 關聯到 X;如果在程式中 Y 的值是 X+1,則 SEE 會將 Y 關聯成 $\alpha + 1$。如果程式有分支,SEE 會用 constraint solver(Z3: An efficient SMT solver、A Decision Procedure for Bit-Vectors and Arrays)來確保只尋找可行執行路徑與識別輸入類型。但由於 path explosion 的關係,通常不能夠識別所有指行執行路徑。
編按:symbolic execution 簡稱為 symbex,可以藉由記憶體位置指定要探索、不探索的程式碼部分。 教學影片中也有用到此功能:Angr CTF 教学 ais3 crackme 根據原始碼,作者是使用 KLEE 這套引擎
Vigor 利用 SE 來驗證 semantic propterties 並且確保記憶體安全,上面提到其假設程式碼做到函式庫、無狀態 NF 程式碼分離。其中函式庫部分經由專家驗證,使得每個函式庫方法(method)都有其語意合約(semantic contract),雖然驗證過程頗枯燥,但只要做一次就能夠被多個 NF 所使用。
Vigor 的工具鏈中,有專為 NF 打造的 SEE 以確保不會發生 path explosion。同時會自動將無狀態 NF 的分析結果與 semantic contract 合併,以產出證明 NF 皆符合其目標 semantic properties 與記憶體安全的資料。需要注意的是,此篇論文並沒有用到 Vigor 的 semantic contract 也與其無關,僅是講解一下 Vigor 的功能。
BOLT 重用了 Vigor 的工具鏈,並採用相似的處理過程:由專家團隊設計常見的 NF 資料結構函式庫,並且產生對應的效能合約與符號模型(symbolic model)。NF 開發者就可以使用這些經過評估的函式庫,再經由 BOLT 產生效能合約。
編按:這邊有點像是 OpenBox(SIGCOMM 2016)的概念。
3.2 基本狀況:資料結構合約
這部分得手動產生,下表是 lpmGet 方法的效能合約:
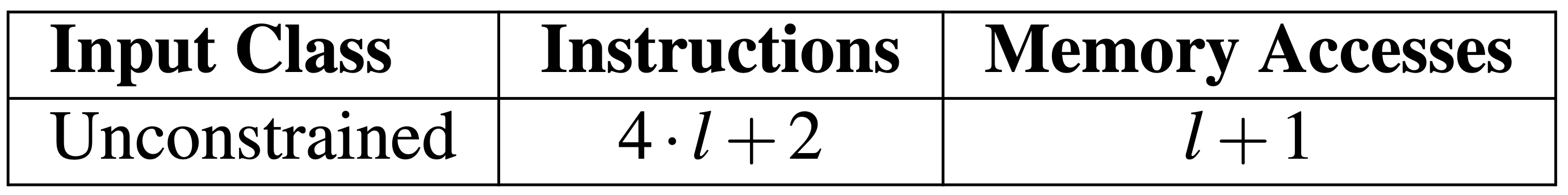
就像是整個 router 的效能合約,這個函數的效能合約僅由一個 PCV 參數 $l$ 表示匹配長度。
在分析過程中,最難的部分是挑選 PCV 指標,要在準確度與實用性之間取平衡。舉例來說,在 lpmGet 程式碼中,是照著長 32 bit 的 IPv4 不斷地尋訪整個 patricia trie,逐一判斷該 bit 是 0 或是 1。若要準確的判斷,則
- 每個匹配的 IP 前綴 bit 都可以當作是一個 PCV 指標。
- 若不想這麼複雜,則可以只用匹配到最長前綴的長度當作唯一 PCV 指標,這表示預測結果都會是在最壞的情況下,也就是可能高估 執行循環次數 或是 記憶體存取量。
3.3 NF 合約

替換有狀態方法:
BOLT 會根據所輸入的 NF 程式碼,來產出一個特製執行檔(special bulid),其所有對有狀態方法的呼叫在連結時期(link time)都會被替換成相對應的 symbolic model(第 2 行)。
編按:肯定都有相對應的 symbolic model 嗎?
舉例來說,在
LPM router中, 對lpmGet的呼叫就會被替換成下面程式碼:function lpmGet(bit ip[32]) { return <new symbol> }取得所有可能的執行路徑:
接著 BOLT 使用符號執行技術,完整地執行特製執行檔,並且透過無狀態 NF 程式碼取得所有可能的執行路徑(execution path)。(第 3 行)
套用到 LPM router,結果會是有兩條執行路徑(有效、無效的 IPv4 封包)。
除了得知每條執行路徑,同時間 BOLT 也會取得
symbolic path constraints(路徑約束),這才知道下次要怎麼做才能觸發這個執行路徑,其包含兩個種類:- NF 輸入的約束,使得其繼續執行特定的執行路徑
- 在呼叫有狀態方法的前、後,每個資料結構的抽象狀態約束(告訴 BOLT 無狀態與有狀態程式碼 與 執行路徑 之間的關係)
分析每條執行路徑:
首先,將路徑約束傳入 solver 以取得具體的輸入(第 6 行),包含:封包、由 symbolic model 產生的符號值,每個執行路徑都會產生一組。
對應到 LPM router 總共會有兩組具體輸入產生(有效、無效的 IPv4 封包)。
接著,每條可執行路徑都會使用具體的輸入來進行測試(作者稱之為回放,replay the NF execution),BOLT 在此同時會對其 instruction 進行跟蹤(trace)以取得 machine instructions。(第 7 行)
最後,BOLT 會統計 instruction 的開銷(第 13 行)直到呼叫到 modeled method。這時候它會根據抽象狀態上的約束,挑選正確的效能合約分支(第 11 行)。對應到
lpmGet,其沒有分支因此沒這困擾。
3.4 NF chain 約束
在 chain 的情況下,可能在 LPM router 前有個防火牆,把許多封包都擋下來,這時候使用封包特徵來去預測 LPM 的效能表現就變得不那 麼準確,因此作者提出了 chain 情況下的分析方式:
照原先分析方式,將每個 NFs 都分析過並取得效能合約
將互連的 NF 兩兩配對,每對中的 路徑約束 使用
AND邏輯操作合併起來,並與第一個 NF 所傳來的封包與第二個 NF 要接收的封包使用 相等約束 連接起來。編按:這邊作者似乎沒有講得很清楚,應該是想表達前面 防火牆 阻擋封包的問題。
使用 solver 檢查路徑是否吻合。
產生全域的 NF 配對效能合約,其加總所有相容的 路徑配對,忽略不相容的。
對於太長的 chain,BOLT 不會列舉所有可能的路徑,而是將相似且相容的執行路徑湊在一塊。只要其拓樸是 DAG,這方法將可以套用到更複雜的網路。
3.5 實作細節
指令回放(Instruction Replay)
作者使用 Intel Pin 二進位插樁(instrumentation)技術來檢測每個回放路徑,以沿著 memory location 記錄 x86 instruction。此時對於「分析用的程式碼(使用 models 連結)」與「實際運行的程式碼(使用真正的資料結構連結)」略有不同的處理方式,BOLT 採取保守策略,將
- 無狀態 NF 與 model 分開編譯
- 停用所有連結時期的最佳化
也就是 BOLT 最後所預測的效能都是在最糟的環境下,確保預估的效能永遠會比預期的好。
編按:為何要分開編譯?
使用硬體模型(Hardware model employed)
在 compute instruction 方面,縱使有亂序執行的影響,作者依據 Intel 手冊上的最壞開銷來做打算,以保守地估計效能。
在 memory instruction 方面,作者只有對 private L1 Data Cache 進行建模,而沒有對一些專利功能如 slice selection algorithm、memory-level parallelism 或 prefetching 建模。
也因此 BOLT 對作者實驗所量測的效能,必定會低於在實際環境中的表現。之後會提到在典型流量上會低估 4 倍,在病態的流量上會低估 9 倍。不過在搭配較好的硬體後,這些誤差可以獲得改善。
編按:實際上 L3 cache 有多個 slice。作者沒有提到怎麼對 L1D 進行建模。 不過根據 GitHub 上面釋出的程式碼,應該是直接給定固定的值(備註:
L1_LATENCY的值為 2)
包含 DPDK 與網卡驅動
BOLT 可以在兩種階段下分析 NF 程式碼:
- 只針對位於 DPDK 上的 NF 程式碼
- 整個軟體堆疊,包含 NF logic, DPDK, 網卡驅動
在第一種方式下,作者將 DPDK 的 傳送 與 接收呼叫都替換成可以注入封包符號(inject packet symbol)的自定義 model,接著過濾無狀態指令追蹤,使得只剩下在這兩個呼叫間的指令。
在第二種方式下,作者立基於使用 Vigor 的 A Formally Verified NAT Stack,使得 BOLT 的預測結果可以包含 DPDK 與 NIC 驅動。雖然整體看起來似乎複雜,但在簡單的 NFs 只需要一個讀寫 device register 的小子集,該子集有簡單的控制流程,因此可以對 無狀態 NF 程式碼做 符號執行。在這個情況下,分析可以從驅動程式接收函數開始,到相對應的傳送/接收函數結束。
編按:第二種方式不太懂作者是在談什麼東西 0.0
4. BOLT 蒸餾器
BOLT 在執行的過程中,可能會遇到有數千條執行路徑情況,但難以得知哪個執行路徑才是真實世界中常見的情況。為此 BOLT 提供了一個稱為 蒸餾器(Distiller)的工具,其功能有二:
- 判斷不同封包對不同合約的相依性
- 分析敏感度(各種合約佔比)
蒸餾器的輸入有 NF 程式碼、真實世界流量樣本(PCAP 檔案)。其量測在各種模型參數下樣本流量 對 NF 所產生的效能影響,作者的實驗方法是對無狀態 NF 程式碼稍作修改,統計迴圈疊代次數、匹配前綴長度。有了這些統計資料,便可以知道封包與所預測的效能之間的關係。蒸餾器並不會更改效能合約,僅是提供用戶推斷與封包相對應的效能合約。
蒸餾器也讓使用者可以進行敏感度分析。舉例來說在 LPM 中大多數匹配會在 16~24 bit 之間,更長的匹配會導致效能下降 32%,不過這僅佔 1% 的流量。
以營運商的觀點來說,可以用蒸餾器來平衡風險與資源利用率,以決定如何配置網路。
以開發人員的觀點來說,可以知道他們哪些假設是錯誤的,進而做出最佳化修正。
5. 評估
這章節分三個部分:BOLT 是否真的有效、介紹使用情境與如何幫助營運商、如何幫助開發人員。
5.1 是否真的有效?
使用四種 NF 測試:
- Br:MAC bridge
- LPM:使用 DPDK LPM 資料結構的 LPM router
- NAT:使用 A Formally Verified NAT
- LB:類似於 Maglev 的負載平衡器
環境:
- 兩台直連伺服器
- E5-2667v2, 32G RAM
- Intel 82599ES 10G
- Traffic Generator: MoonGen with PCAP file
- 一次一個封包,避免 queue 或 pipeline 影響
方法:
首先 BOLT 從多種執行路徑產生效能合約,包含:
- 指令執行量(instruction count, IC)
- 記憶體存取次數(memory access, MA)
- 執行週期量(execution cycles)
接著使用各種不同的輸入封包來量測真實數據,其輸入包括 未受約束的流量、廣播流量,以囊括成千上萬個可能的執行路徑。在量測的時候,IC 與 MA 會使用二進位插樁方式取得,至於延遲則是使用高精度 CPU 時脈工具 TSC 並且是在沒有插樁的情況下。
編按:為何跟廣播流量(broadcast traffic)有關係?這是什麼?
對於大部分的封包種類,可以使用預產生的 PCAP 檔案來達到想要的效果;不過有些種類例外,需要對 NF 做些小修改才能滿足實驗設定,這部分晚點會說明。
輸入封包種類:
對於每個 NF 來說,首先考慮 未受約束的流量(場景 Br1、LPM1、NAT1、LB1),給定各種封包種類,BOLT 可以做出最糟情況下的預測。
再考慮到需維護狀態表的 NF,BOLT 需假定其 MAC/flow table 都是滿的狀態下,在封包到達的時後,所有的項目都會互相碰撞,且所有的項目都是最老舊狀態,因此會導致大量的到期事件(expiry event)發生,此時 table 會完整地清空。作者無法產生會導致這種狀況發生的 PCAP 檔案,因此只好略為修改 NF 以符合這種病態情況。為了產生未受約束的流量給 LPM,作者使用了 CASTAN 框架,其是專門產生對抗工作負載(adversarial workload)給 NF 的框架。
編按:adversarial workload 在CASTAN 中的論文提到,指惡意製造能夠大量消耗 NF 資源的封包。
對於需維護狀態表的 NF,作者也測試了不會遇到雜湊碰撞、項目到期(entry expiration)等問題的情況:
- Bridge 中使用 broadcast (Br2) 與 unicast (Br3) 兩種測試
- NAT 中從內部來的 (NAT2)、從網際網路來的 (NAT3)、從網際網路來的但不屬於任何連線會被丟棄的 (NAT4)
- LB 中從外部來的新流 (LB2)、現有 unresponsive 後端伺服器的 (LB3)、現有 live 後端伺服器的 (LB4)、後端伺服器發出活動訊號(heartbeat)的 (LB5)
LPM 使用 DPDK 的兩層式查表,其結構是只要匹配長度 24 bit 以內只需要一次查找,超過就需要兩次查找。因此任何在受約束的封包種類中只要匹配長度大於 24 bit,其效能表現跟未受約束的一樣。此外,作者將 24 bit 以下的封包當作 (LPM2)。
編按:為何一樣?
硬體無關指標的結果:
下圖為 IC 與 MA 的結果,分別最多只高估了 7.5%、7.6%。
可以看到未受約束維護狀態表的 NF 病態情境下(Br1, NAT1, LB1),比其他情境都高了 8 個數量級($10^8$),一個封包甚至大約需要一分鐘來處理。
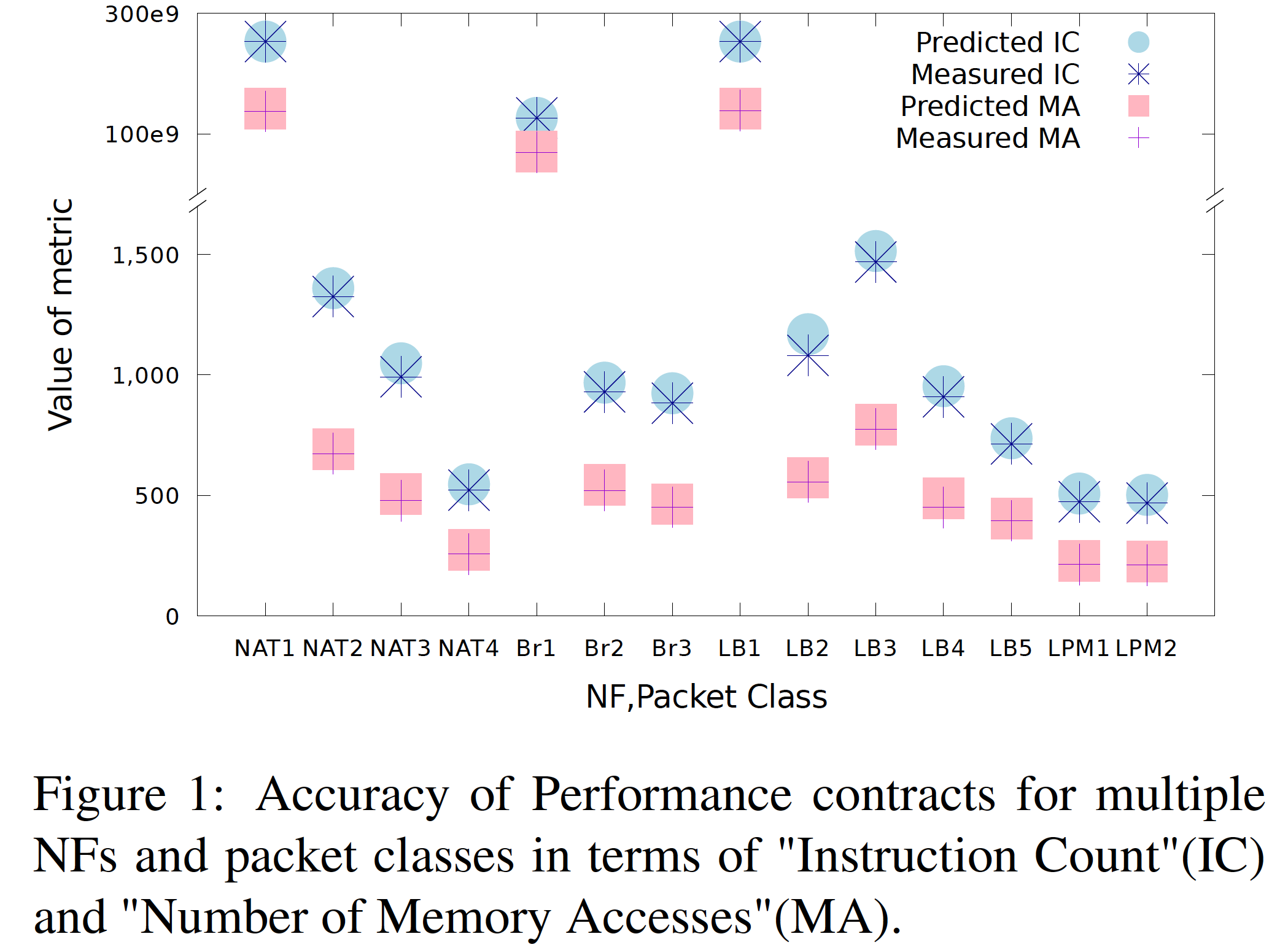
作者將高估誤差歸因於兩個可能:
- 在 [NF chain 約束] 提到會把相似且相容的路徑湊在一塊
- 分析的程式碼與實際執行的不同(實際的有最佳化過)
硬體相關指標的結果:
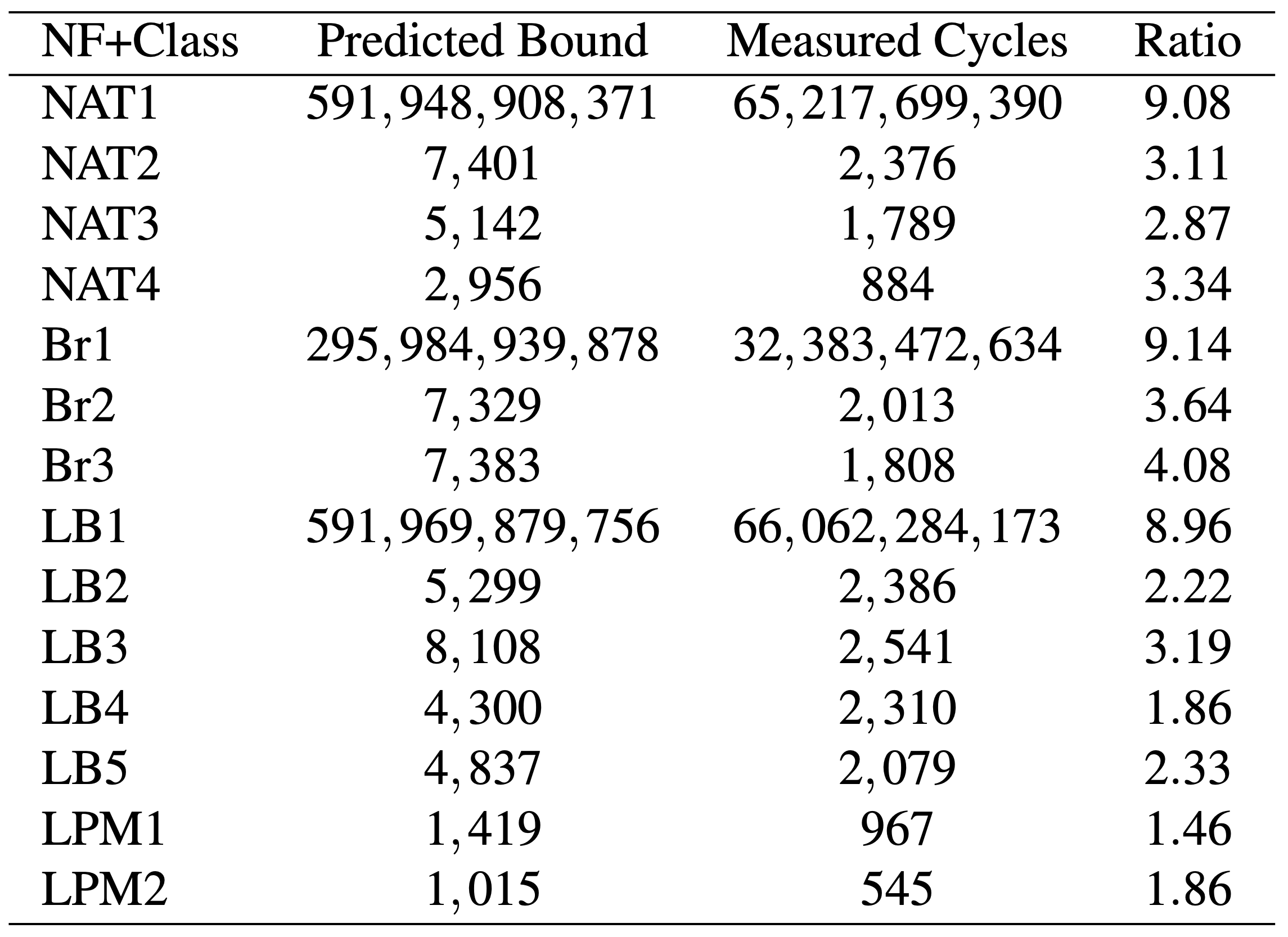
可以看到 BOLT 在典型流量中預測結果為實際的 4.08 倍,在病態流量中是 9.26 倍。
這並不意外,如果有更好的硬體模型,準確率是可以上升的。為了簡單地驗證這個假設,作者弄了一個小實驗,總共三支程式:
- P1 遍歷不連續分配的 linked list
- 預測延遲誤差 5%
- 缺了 MLP (memory level parallelism) / prefetching
- P2 遍歷連續的 linked list
- 預測為實際結果的 6 倍
- 有 prefetching,缺 MLP
- P3 遍歷陣列
- 預測為實際結果的 9 倍
- 有 prefetching、MLP
這個小實驗顯示了「硬體表現的跟模型越像,BOLT 越準確」。
5.2 NF 營運商使用案例
知道 NF 在遭受攻擊時的效能表現
有了效能合約(測試過所有可行執行路徑),營運商可以更容易知道在遭受攻擊時的效能表現。
作者使用 MAC 橋接器當作例子,其在學習 MAC 位址時使用雜湊函數加上隨機產生之密鑰,以防止碰撞攻擊。如果在雜湊表中 put 操作期間,雜湊表遍歷儲存桶超過某個閾值,密鑰就會重新產生,雜湊表也會隨之重新雜湊。這是為了防範知道雜湊函數卻不知道密鑰的攻擊者,然而重新雜湊的開銷大到會有非常明顯的效能影響,如下圖。
編按:put 期間遍歷是為了什麼?一般來說 ARP spoofing 不太會有這樣的行為才對呀🤔

上圖可以看到重新雜湊開銷非常的高,為了盡量避免誤判情勢而導致重新雜湊,BOLT 與蒸餾器的公用就顯得重要。下圖由蒸餾器產出,在均勻分布狀況下,從 CCDF 可以看到只有少於 0.2% 的封包會有 6 個以上的遍歷,因此若將閾值設定為 6,則可以試算指令開銷都會小於 $1939 = (144 \times 5 + 50 \times 6 + 918)$ , where $e = 0, c = 5, t = 6$
編按:這些計算是哪來的,為何 known 跟 unknown 有所不同? CCDF 指 complementary cumulative distribution function,是對連續函數,所有大於 a 的值,其出現機率的和:$F(a) = P(x > a)$。
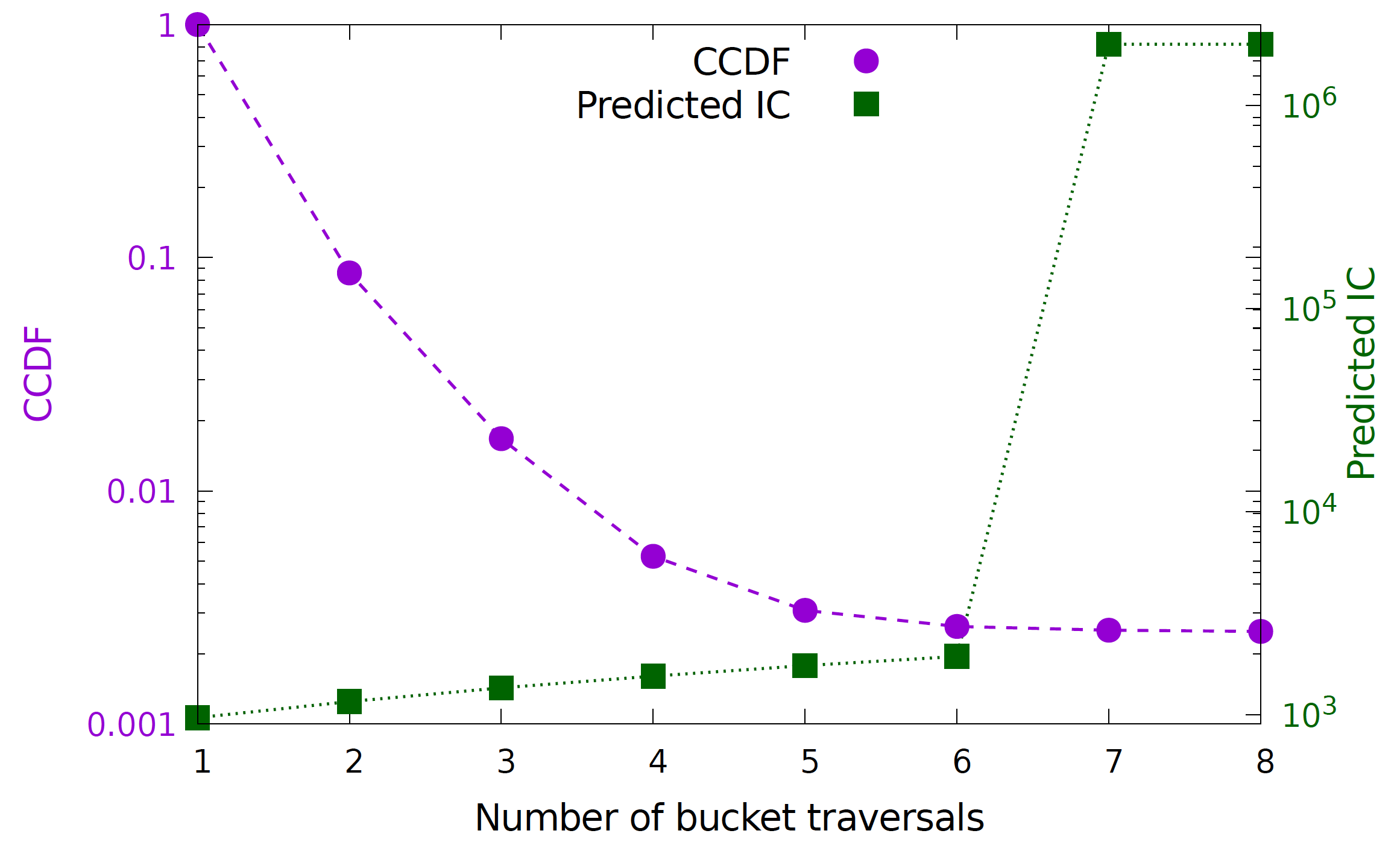
推斷網路效能的能力
通常來說營運商都會串連 NF 成 chain,這時候效能合約中的最壞情況可能就會被其他 NF 改善。(參考 § 3.4)
舉例來說,有個 firewall 與 static IP router 要串連在一起,比較特別的是這個 IP router 跟 LPM 不一樣的是它會查看 IP option TIMESTAMP,因此開銷會比較高,下圖有兩者分別的效能合約與預測合併時的效能合約:

因為 firewall 已經事先 drop 有 TIMESTAMP 的封包了,所以合併開銷並沒有說太高,下圖是量測結果:
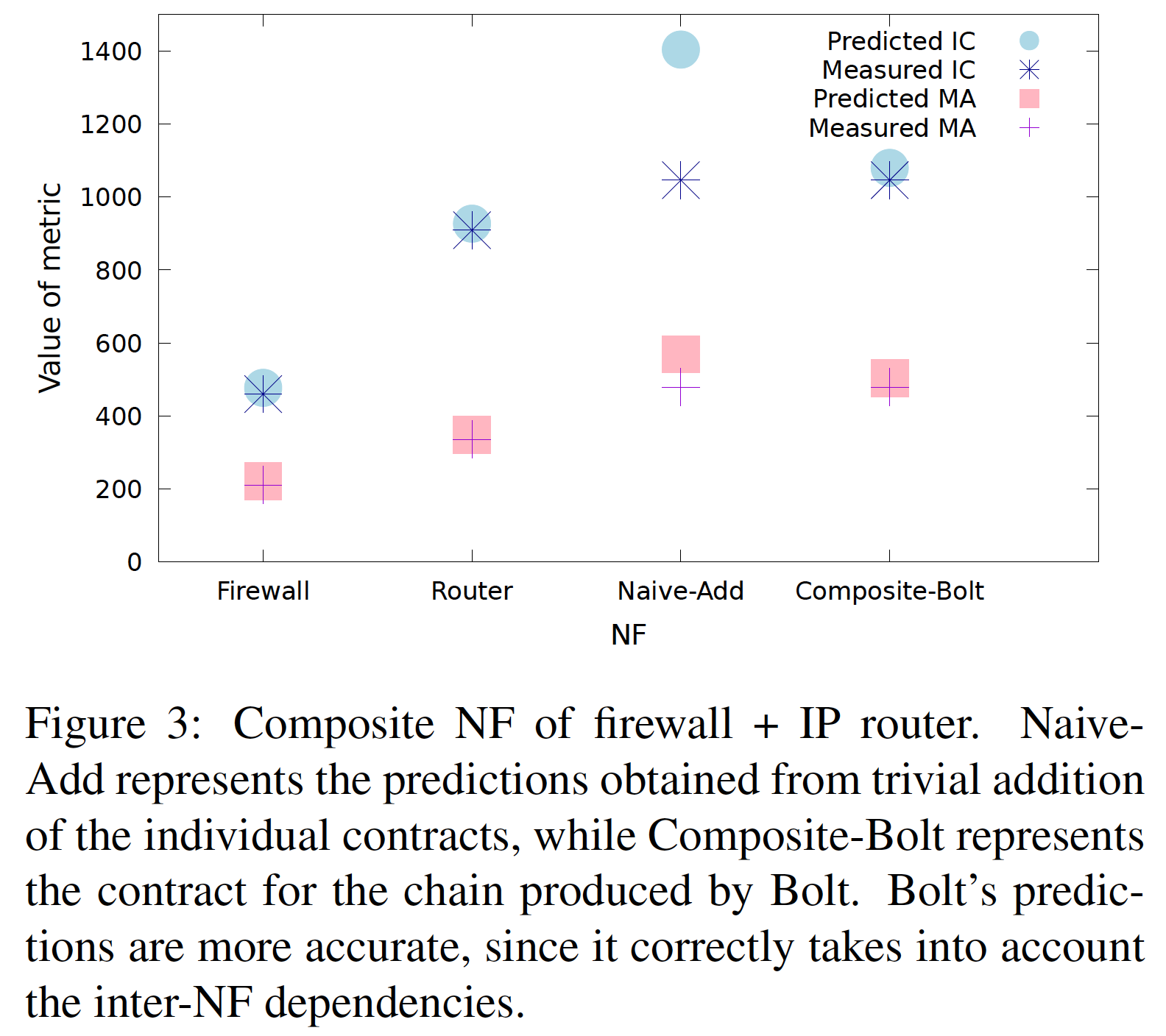
其中 Naive 是直接累加兩個 NF 的效能合約,因此頗失準。在 BOLT 考慮到合併 NF 的狀況下,準確度就大幅提升了。
編按:這邊沒有考慮到競爭問題,可以參考 Contention-Aware Performance Prediction For Virtualized Network Functions
5.3 NF 開發者使用案例
替組態所造成的瓶頸偵錯
作者舉例將 BOLT 套用到 VigNAT 上時,可以較容易查明問題的來源。
當 VigNAT 在變動幅度大(high churn)的環境下,會導致大量持續的延遲發生(> 3 μs),不過以 CCDF 的角度來看約只有 1.5 % 的封包有這樣的趨勢,且造成了長尾效應,見下圖紫色 Original 線:
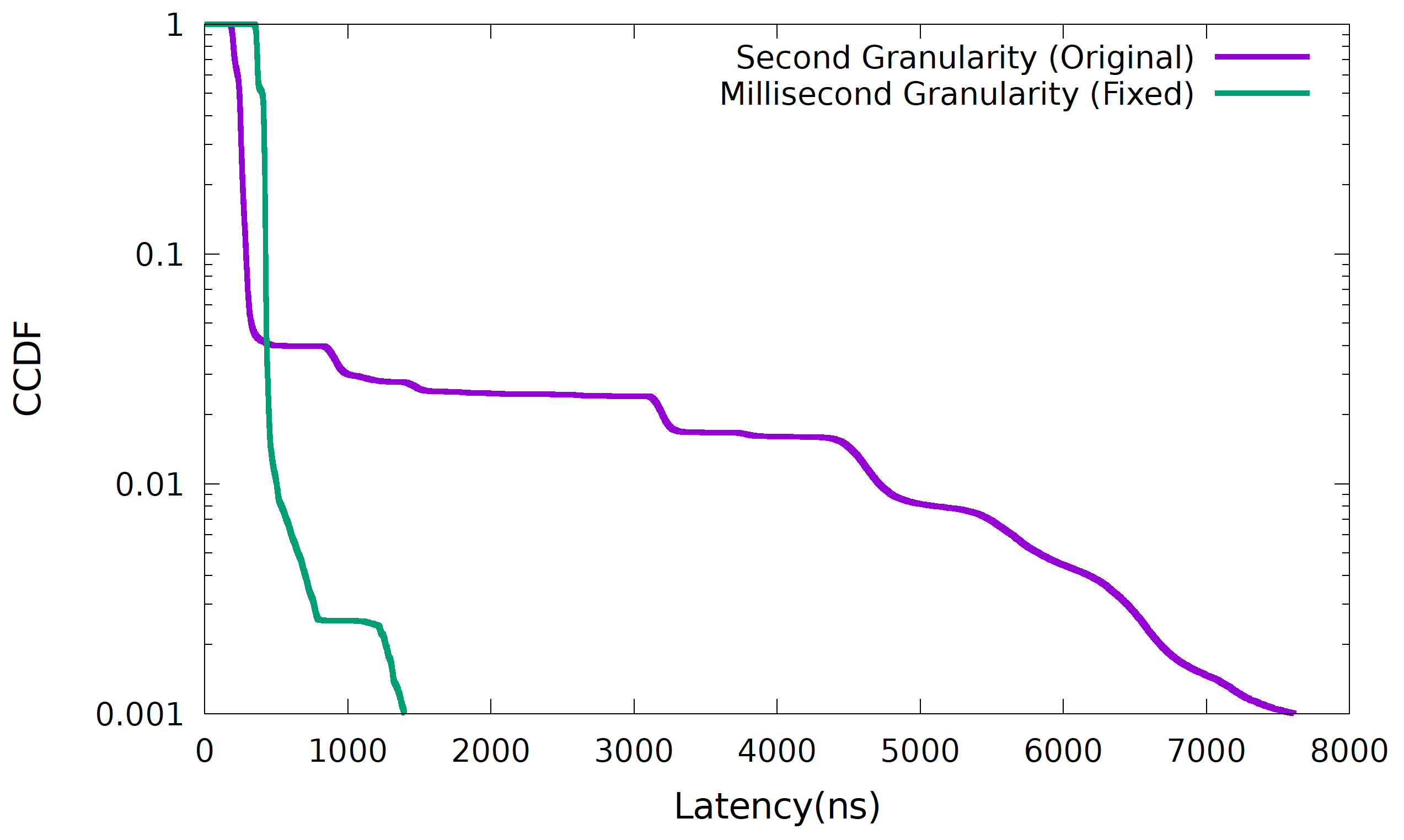
圖 4. 封包延遲的 CCDF
建立效能合約後(見下表),可以知道造成長尾效應的原因可能是有大量的 flow 同時過期,因為 PCV 指標 e 主宰了整個效能合約(編按:可能是 e 比其他指標大了一個數量級)。

表 6. VigNAT 的效能合約,e 代表過期 flow 的數量,c 代表雜湊碰撞的數量,t 代表儲存桶遍歷
蒸餾器也更加證實這點猜測,因為過期 flow 的分佈與低落效能的預測大致相似。
編按:看不懂這句話,低落效能預測在哪?感覺這是對每個時間區間取樣,大多數時間不會有到期的 flow 產生,而是集中在少數時間
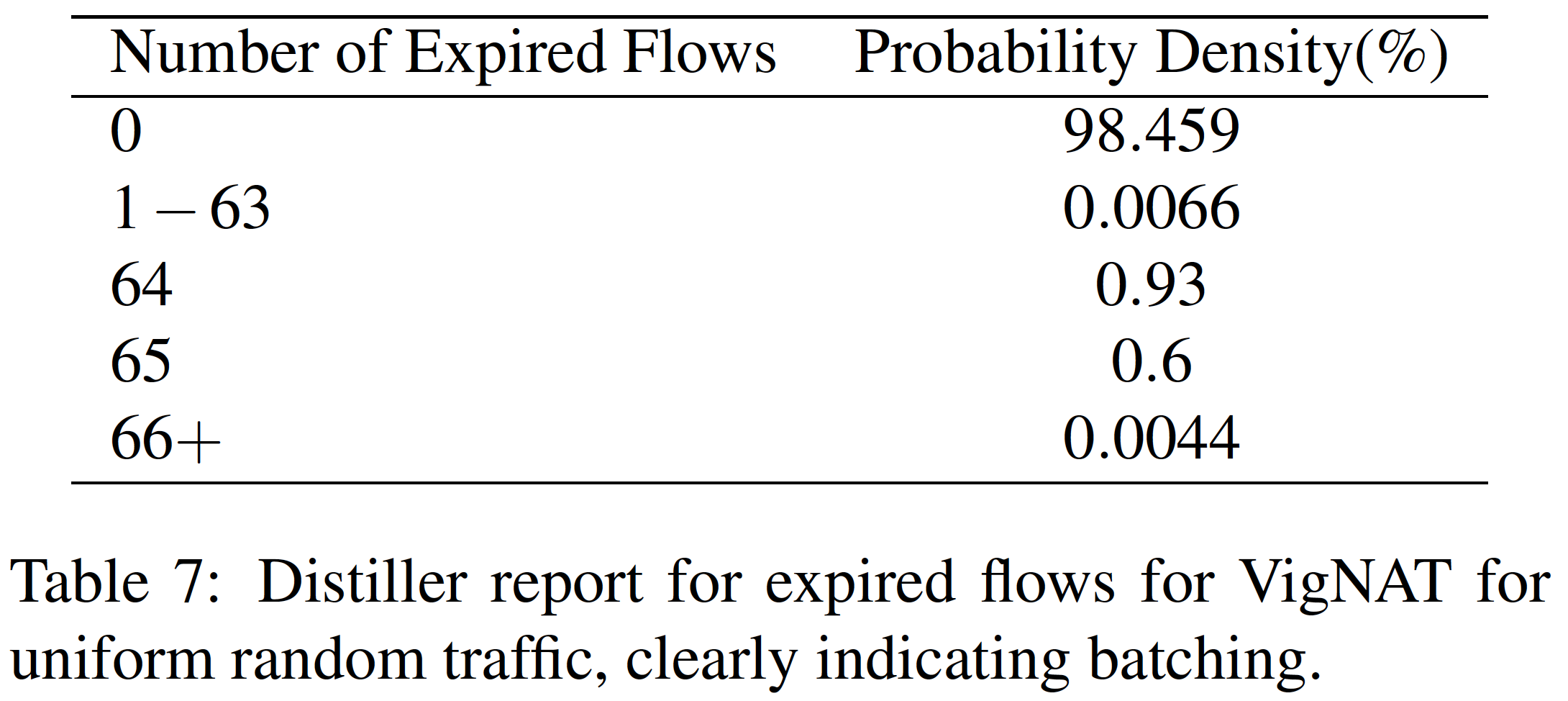
作者發現,VigNAT 並不是故意批次處理到期的 flow,而是時間取樣精度只到秒,因此在跨秒區間到達的封包就會遭遇到大量的到期 flow 處理,進而導致延遲的發生。
因此只要將時間取樣精度調整到毫秒單位,即可避免這種問題發生。再看回到圖 6 的綠色線就是調整過後的結果。下表為調整過後的過期分佈:

挑選合適的實作資料結構
為了因應不同的流量場景,開發人員時常會遇到資料結構選擇障礙。BOLT 此時就提供了簡化決策過程與 A/B 測試的麻煩。
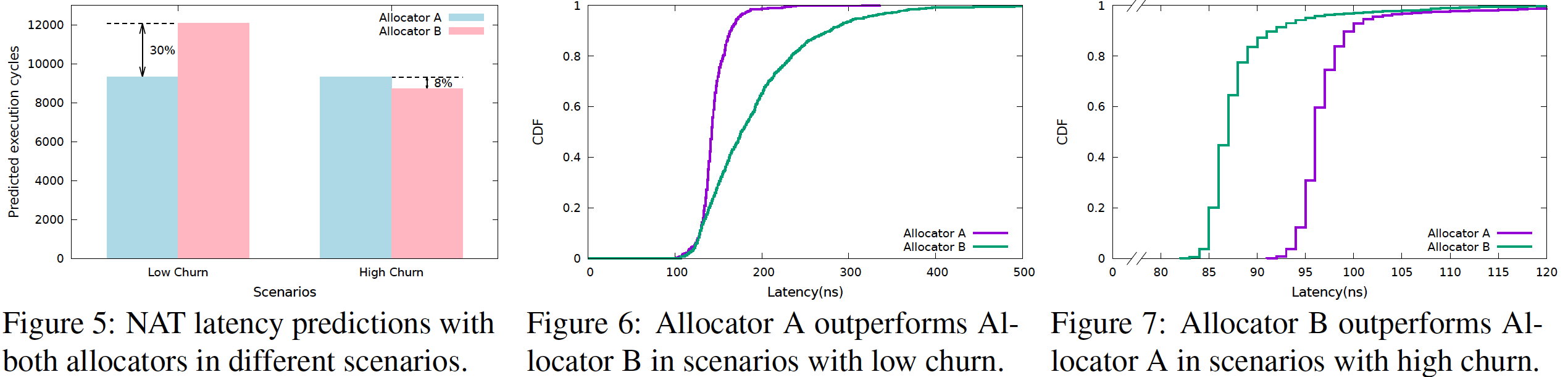
舉一個 NAT port 分配的例子,兩種實作都有相同的複雜度 O(1),但是仍有一些效能上的差異:
- Allocator A:
- doubly-linked list
- 在分配與解除分配 port 上有著相似的常數
- Allocator B:
- 陣列配上 singly linked list
- 在解除分配 port 上的常數跟 Allocator A 差不多
- 在 flow-table 佔用率不高時,分配較快;佔用率高時,分配慢不少
下面這張圖可以看到:
- 不同情況下,執行循環各有不同(圖 5)
- 在較長壽(也就是 low churn)的狀況下,Allocator A 延遲好過 30%(圖 6)
- 在較短命(也就是 high churn)的狀況下,Allocator B 延遲好過 10%(圖 7)
6. 當前限制
由於 BOLT 是使用 Vigor 打造而成,如果沒有做到下面這兩點,將無法進行分析:
- 在程式上把有狀態、無狀態分離乾淨
- 用到預先分析完成的函式庫
當前的 BOLT 尚未支援那些在多執行緒間共享狀態的 NF,作者認為這個難題是需要產生跨 CPU 核心的並行資料結構。
當前的 BOLT 原型僅支援使用 DPDK 且只使用單核心的 NF。因為 DPDK 繞過的 Linux 核心,因此 BOLT 不需要考慮核心相關議題。在 DPDK 的最佳實踐中,建議將 NF 綁定到單一核心上,以避免 L1 cache 受到其他程式的干擾。
因此如果沒有做到這兩點,BOLT 的預測就會不夠準確:
- 避免在處理封包時有 Linux 系統呼叫(編按:這會有 kernel space 切換,因為用了 uio,DPDK 都在 user space)
- 禁止其他程式搶佔 CPU 核心(編按:也就是設定 isolcpus)
之前有提到過,對 BOLT 來說那些與硬體不相關的指標會是準確的,僅有約莫 7% 高估的原因為:
- 在 §3.4 中提到「將相似且相容的執行路徑湊在一塊」,§3.2 的方法二也是
- 分析期間停用連結時期的最佳化,以確保預測永遠會高估
根據作者的經驗,第一項會是影響準確度的關鍵,如果使用足夠多不知覺的 PCV 指標是可以大幅降低預測誤差的。
至於硬體相關指標方面,在 §3.5 [使用硬體模型] 中提到只要用了合適的硬體模型即可,不過卻沒有考量到多個 NF 在同一裝置上資源競爭的狀況,此狀況在 Contention-Aware Performance Prediction For Virtualized Network Functions 有設法預估。
這些有狀態資料結構效能概要是人工分析組合語言產生的,非常的耗費人力且容易有錯誤,作者希望之後能自動化。
BOLT 目前需要 NF 原始碼才能進行分析,因為這能夠大幅降地人工分析程式碼的門檻,並且挑出具有價值的 PCV 指標,否則就只能從編譯器提供的除錯資訊(編按:例如 gcc -g)中獲得,或是只好逆向工程。
目前作者使用的 SSE 是分析 LLVM bitcode,因此需要特別的組建(build)程序才能獲得。其他的引擎像是 Selective Symbolic Execution 可以直接對 X86 二進位檔案進行分析,因此作者的考量或許可以獲得改善。
編按:bitcode 為 LLVM IR 三種形式中的其中一種,可參考 Intermediate representation
clang -S -emit-llvm main.c即可獲得人類可讀 IR,詳情可參考此篇
BOLT 目前僅針對三種指標進(IC, MA, cycles)行效能預測量化,作者打算在之後的版本延伸到叫通用的指標如 吞吐量、端到端延遲。
作者認為目前有的重大挑戰有:
- 模型化 PCIe 匯流排(NIC 與 queue 延遲)
- 模型化 instruction & memory 階段的平行化(吞吐量)
7. 相關研究
效能評估與診斷
目前已經有一些發表專注於產生、分析攻擊軟體效能的對抗工作負載。
- 手動產生,專注於資料結構、網路應用程式(如 IDS):
- Denial of service via algorithmic complexity attacks. In USENIX Security Symp., 2003.
- Making DPI engines resilient to algorithmic complexity attacks. IEEE/ACM Trans. on Networking, 2016.
- Backtracking algorithmic complexity attacks against a NIDS. In Annual Computer Security Applications Conf., 2006.
- 使用 fuzzing 技術自動產生,並尋找資料結構、方法的瓶頸
- Synthesizing programs that expose performance bottlenecks. In Intl. Symp. on Code Generation and Optimization, 2018.
- Automated domain-independent detection of algorithmic complexity vulnerabilities. In Conf. on Computer and Communication Security, 2017.
- Testing the results of static worst-case execution-time analysis. In Real-Time Sys- tems Symp., 1998.
- 自動偵測網頁服務 DoS 攻擊
- Detecting and exploiting second order denial-of-service vulnerabilities in web applications. In Conf. on Computer and Communication Security, 2015.
- 自動產生 NF 的對抗工作負載
- Automated synthesis of adversarial workloads for network functions. In ACM SIGCOMM Conf., 2018. 👍
上述這些僅專注在產生對抗工作負載,然而效能合約則是專注於所有負載下的效能表現。
- 效能上限
- The worst-case execution-time problem — overview of methods and survey of tools. ACM Trans. Embed. Comput. Syst., 2008. (WCET)
- 旁道攻擊也使用靜態分析技術
- Symbolic path cost analysis for side-channel detection. In Intl. Symp. on Software Testing and Analysis, 2018.
- 預測大規模資料分析應用的效能
- Efficient performance prediction for large-scale advanced analytics. In Symp. on Networked Systems Design and Implem., 2016.
- Architecting for performance clarity in data analytics frameworks. In Symp. on Operating Systems Principles, 2017.
- 可以預測效能,但需使用 TiML functional language,其對型別檢查嚴格
- 執行期間效能監控、瓶頸偵測
- 替封包加上標籤,以利包含效能方面的網路政策執行
NF 的程式分析
- 靜態分析 NF 的 per-flow 與全域狀態,以利遷移、重新發布到不同伺服器
- 使用 SE 找 bug、驗證正確性
- Automatic test packet generation. In Intl. Conf. on Emerging Networking Experiments and Technologies, 2012.
- Automating the testing of OpenFlow applications. Intl. Workshop on Rigorous Protocol Engineering, 2011.
- A NICE way to test openflow applications. In Symp. on Networked Systems Design and Implem., 2012.
- 使用 SE 檢驗網路屬性
- Scalable symbolic execution for modern net- works. In ACM SIGCOMM Conf., 2016. 👍
- 使用 SE 驗證 NF
- A formally verified NAT. In ACM SIGCOMM Conf., 2017. 👍
- Software dataplane verification. In Symp. on Networked Systems Design and Implem., 2014. 👍
名詞解釋
Stub
Test stub 是指模擬正在測試的模組所依賴的軟體元件的行為,專門提供罐頭回答,而不會因為不同情況而有不同回應。用來當作臨時替代的模組,並提供與實際模組相同的輸出。
舉例來說,線上翻譯 API 是以次數計價,在本機應用開發中並不需要真的去呼叫此 API,可以自己寫一個偽的。
參考資料:
Satisfiability modulo theories (SMT)
在計算機科學和數學邏輯中,可滿足性模理論問題是邏輯公式相對於用等式的經典一階邏輯表達的背景理論的組合的決策問題。在計算機科學中通常使用的理論示例有實數理論,整數理論以及各種數據結構(如列表,數組,位向量等)的理論。SMT 可以被認為是約束滿足問題的一種形式,因此可以被認為是約束規劃的某種形式化方法。
目前最常見的求解器(solver)是微軟釋出的 Z3 Theorem Prover,可在多平台上用多種語言呼叫,下面為 Z3 範例:
命題與論證邏輯
$\neg (\neg(a \wedge b) \equiv (\neg a \lor \neg b))$
(declare-fun a () Bool)
(declare-fun b () Bool)
(assert (not (= (not (and a b)) (or (not a)(not b)))))
(check-sat)
結果:(不滿足)
unsat
解方程式
$\begin{cases} a+b=20\ a+2b = 10\ \end{cases}$
(declare-const a Int)
(declare-const b Int)
(assert (= (+ a b) 20))
(assert (= (+ a (* 2 b)) 10))
(check-sat)
(get-model)
結果:(滿足,並且舉例)
sat
(model
(define-fun b () Int
-10)
(define-fun a () Int
30)
)
參考資料:
Time Stamp Counter (TSC)
在 x86 處理器上面的暫存器,用來計數 CPU cycle,用於 RDTSC 指令。不過在多核心、超執行緒的架構下,因為無法同步頻率而造成失準。
為了避免亂序執行技術所帶來的影響,可以使用 CPUID 或 RDTSCP 來確保指令同步執行。
參考資料:
Intel Pin
動態二進位插樁框架,可在 IA-32、x86-64 等環境下執行。可用來在 Linux、macOS、Windows 平台下對編譯過後的執行檔(不需要原始碼)進行分析。
使用 Pin 打造的工具包括:Intel VTune Amplifier、Intel Inspector、Intel Advisor、Intel Software Development Emulator (SDE).
其相關論文 2005 年時發表在 ACM SIGPLAN Notices,名為 Pin: building customized program analysis tools with dynamic instrumentation。
參考資料:
Device Register
在電子裝置上的可程式化區域,提供給程式設計師安裝程式、輸入指令,並且與個人作業系統、週邊裝置進行互動。舉例來說,程式設計師可以在平板電腦接上個人電腦後,要求兩邊的資料進行同步。
裝置通常有多個暫存器以提供各式各樣的功能,其中一個常見的為提供資料的讀取與寫入的 data register,如果使用者需要這項功能,需要知道要對誰操作,同時這個 register 也會提供儲存容量等資訊。
另一個常見的 register 為 control/status register,可以選擇、顯示目前的模式,也可以讓使用者輸入指令操控裝置。
參考資料:
Bitcode
comments powered by Disqus