- 論文連結,ICDCS 2019
- 論文筆記
- 實驗室 meeting 簡報連結
- Notion 筆記
這篇論文主要是由北京清華的學生們寫的,2019 年時發表在 IEEE 39th International Conference on Distributed Computing Systems (ICDCS)。
有鑒於當前的 NFV 飽受高延遲之苦,尤其是當鏈越長延遲也就越明顯。在傳統的做法上不是使用特殊硬體進行加速,就是對沒有相依關係的 NF 進行加速。但這兩種方式都因為 NFs 是模組化的關係仍無法有效消除之間個隔閡。因此作者打算透過調整 NF 順序、消除不同 NF 內重複解析的工作來降低 NFs 運作時的延遲。
此論文有將程式碼透過 GitHub 釋出,測試平台為 BESS 與 OpenNetVM。作者透過自創的 SpeedyBox 架構,包含 Local Match-Action Table (MAT)、Global MAT 與 Event Table 三個主要技術來達成降低延遲的發生。
Introduction
在未來 5G 世代,edge cloud 網路延遲標準為 0.5 ms,對 NFV 來說是個嚴峻的挑戰,尤其是目前不同的 NF 可能不會在同一台主機上,這麼一來一往的傳輸中延遲又會增加。
先前的的論文有嘗試解決 NFV 延遲方面的問題,方式不外乎有兩種:
- 透過 FPGA 等專用硬體配上共享記憶體
- 平行處理一些沒有相依關係的 NF
但是這兩種加速方式都有一個共同的前提,「NF 是模組化的」,因此 NF 間的隔閡勢必是存在的,像是每個 NF 可能都會對封包表頭、內容欄位進行重複解析、分類、棄包(鏈後方的 NF 如果會 drop 那前面 NF 所做的事情就有點白費功夫)。當然為了安全、方便開發考量,作者不可能真的完全移除 NF 之間的隔閡。
因此作者分析了當前企業網路的 NFs,觀察到 per-flow 方式解析的 NF 行為會保持一致,直到有個 event 發生,導致 NF 行為改變。因此若沒有 event 的觸發,就可以將進入鏈的第一個封包經過一連串 NF 所產生的行為蒐集整合起來使用,原文為「consolidate the aggregated actions across NFs as the initial packets of a flow traverse the chain」。
然而在進行此實驗的同時,會遇到下面兩種問題:
- 如何以最低成本收集不同 NF 的行為?
- NF 各式各樣,必先找到共通點
- 如何在新的 consolidated path 中表現出鏈的 stateful 行為?
- 現代大多數的 NF 都是 stateful 的,因此很重要
- 有了 stateful 的關係會變得更加複雜,其他類似的論文很多都沒解決 stateful 問題
為了解決這些問題,作者提出了一個名為 SpeedyBox 的架構,主要架構有三個:
- Local Match-Action Table (MAT)
- Global MAT
- Event Table
SpeedyBox 並不會造成太多 overhead,也不會改變 VNF Chain 的最終行為(產出),並且提供友善的 API 來達成這些功能,作者特別提到針對 Snort 這款 IDS 的改裝只用了 27 行程式碼。
Context & Challenges
冗餘問題
在典型的 service chain 當中(像是 NAT→ Load Balancer → Monitor → Firewall),常會有冗餘的處理過程:
- 重複解析與分類(repeated parsing and classification)
- 這四個 NF 都需要對封包進行解析,要做 4 次
- 理想狀態:只做一次就好
- 封包太晚被丟棄(late packet drop)
- 封包走到 Firewall 才被丟棄,前面三個 NF 的處理都白費了
- 理想狀態:越早被丟棄越好
- 封包被多次覆寫(packet overwrite)
- NAT 可能針對 destnation 的 IP 位址與 port 進行修改
- 然而 Load Balancer 也可能會針對這些欄位做修改
- 理想狀態:只改一次就好
- 隔離所造成的冗餘 IO(redundant IO caused by isolation)
- 目前主流是透過 VM 或是 container 技術來進行隔離,對冗餘 IO 有不可避免的影響
- 但隔離是必要的,這是為了安全考量,因此冗餘不可能完全消除
- 不過,仍是可以透過減少浪費的 communiaction 來降低冗餘
對於冗餘的處理,根本問題是在模組化與效能之間做取捨。
不同情境中的類似方法
在 OVS 1.11 版中有提出 Megaflows 的概念,也是在第一個封包經過後會建立快取(快速通道),往後經過匹配成功的封包就會走這條快速通道(類似搭飛機 VIP 免查證通關),可惜這是 stateless 的作法。
作者舉例像是 Google 提出的 Maglev Load Balancer 就不適用,該演算法是基於 consistent hash 去做改良,但因為有對 runtime backend server fails 做改善因此會是 stateful。
設計概要
架構
- Local Match-Action Table (MAT)
- 每個 NF 都會對應到一個 Local MAT
- 每個 flow 的第一個封包經過鏈時,都會呼叫相對應的 API 來記錄其觸發的行為與狀態
- 這些行為與狀態會儲存在 Local MAT 當中
- Global MAT
- 當第一個封包通過後,Global MAT 會從各個 Local MAT 中收集資料
- 收集並整理完後,會建立一條經最佳化的快速 data path
- 每個 flow 的第二個封包開始都會經過這條 data path
- Event Table
- Event Table 會持續的對封包進行檢查,看有沒有觸發任何
event - 這是用來確保 stateful 的相關功能能夠正常運作
- 如果有觸發
event就會更改 Global MAT 中相對應行為
- Event Table 會持續的對封包進行檢查,看有沒有觸發任何
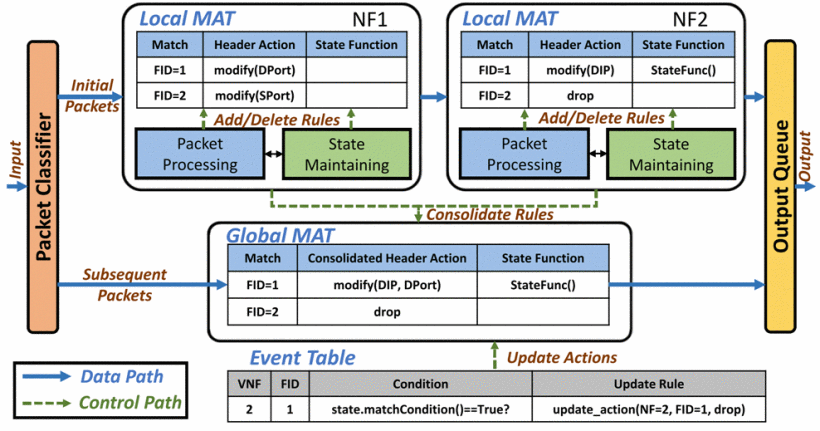
Fig. 1
上圖描繪出 SpeedyBox 的架構,最左邊是一個 Packet Classifier,會對封包中 5 組 tuple(沒明講哪五個)進行雜湊進而產出 20 bits 的 FID 用以表示這個封包屬於哪一個 flow,這組 FID 會直接附加在 pakcet 上當作 meta-data,並且不論在 VNF chain 過程中有遭遇到任何資料欄位的變動都不會影響其值,最後在離開鏈時移除 FID。根據作者所述這可以表示超過一百萬組(2^20)同時進來的 flow,對於此次進行的實驗已經足夠。
有個 FID 之後,每個 flow 的第一個封包會走上圖上方的路線,先經過 NF1 再經過 NF2。在 NF1 內可以看到如果 FID 的值為 1 的時候會透過 Header Action 修改 Destination port,在 NF2 內會修改 Destination IP address 還有透過 State Function 觸發 StateFunc。這些觸發都會在 Local MAT 中做紀錄,並且在 Global MAT 中結合起來,因此該 flow 中的第二個以後的封包都會走下面的路線,可以看到就沒有經過兩個 NF 了而是使用 SpeedyBox 所建立的 fast path,所有的操作都被合併了。
以 FID == 2 為例,在 NF2 中 drop 了,因此在 Global MAT 當中為了增加效率,直接把封包做 drop 處理。
至於最下方的 Event Table 則是當封包若滿足某個條件,則會觸發 Update Rule 來改變 Global MAT 的行為。值得注意的是,在 subsequent packets 中,都會先檢查是否有 event 被觸發,如果都沒有才會套用 Global MAT 的規則,若有則是先更新 Global MAT 中的規則,該封包再套用之。
接著來談一下 MAT 中的內部構造。
MATCH代表哪組 flow,也就是FIDHeader Action顧名思義是對封包的表頭進行修改,另外還有有關 drop 的判斷。- 分為五大項:
Forward:只會對封包做解析(用於 NF 內部狀態更新),不做任何修改即把封包傳出。Drop:把封包丟棄,並且將關聯的packet descriptor設為 nil。(例:防火牆)Modify:修改表頭欄位以達到特定的路由效果。(例:Gateways, Load Balancer, NAT)Encap&Decap:有些 NF 會對封包進行表頭的新增、移除。(例:VPN 會在傳輸過程中加上Authentication Header並且在到目的地時移除)
- 分為五大項:
State Function是針對 NF 內部的 state 做處理,也就是為何 NF 可以達到 stateful,因此也會檢查封包的 payload。(例:Snort 檢查到惡意封包時會對整個 flow 做 flag 標記)- 會將根據如何跟封包互動來做分類(type),總共三種:
- IGNORE:不讀也不寫(優先權最低)
- READ:只讀
- WRITE:會有寫入(優先權最高)
- 優先權高的會覆蓋掉優先權低的(如下圖),因此共有兩種搭配可以達成平行處理
- batch_1 跟 batch_2 都是 READ
- batch_1 是 WRITE 且 batch_2 是 IGNORE
- 有些 NF 不會把這些 state function 的程式邏輯包裝成 callback function,因此要移植到 SpeedyBox 時需要費更多時間來改寫
- 有些 state 是一群 flow 所共享的,有些 state function 是由一群 flow 所共享的。因此面對這種問題時必須要小心平行處理會造成的問題,以避免造成衝突或是錯誤的程式邏輯
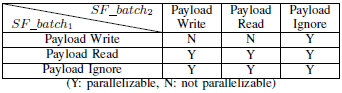
- 會將根據如何跟封包互動來做分類(type),總共三種:
適用範圍
一般情況可以,但 NF 會依賴一連串大量封包時則沒有很適合,像是 WAN optimizer 需要透過迴圈來收集封包,這種瓶頸會在等待封包的到來而不是封包處理的 overhead。
SpeedyBox 的強項是在針對單一封包的處理上,因此適合 large fraction of functions 的架構。
API
為了最小化 NFs 在套用 SpeedyBox 時所做的程式碼修改,作者設計了一些好用的 API。
Header action 中
- 有設計出標準化的 header actions
- 能夠附加參數,如需要修改的表頭欄位
void localmat_add_HA(int FID, HA header_action, args* arg_list)State function
- 有 handler function 當作參數
- 該 function 的 type(payload write/read/ignore)
- 該 function 所需的參數
void localmat_add_SF(int FID, function_heandler*, int function_type, args* arg_list)event
- 有 condition_handler function 當作參數、與其參數
- 需要被改的 action/function
void register_event(int FID, condition_handler*, args* arg_list, HA update_action, update_function_handler*)
有關於實作細節,為了保持邏輯順序上是正確的,作者使用 queue 的資料結構來儲存 actions 與 state function。
實作方式
作者認為對 L3 相關的 NF 而言,每個 flow 的第一個封包所觸發 function,與在後續到來的封包中會是相同的,除非有觸發到特定的 event,而 event 的觸發一定是內部某個 state 的改變使然。event 不常發生,但是發生了就很重要。
作者舉 Google Maglev 這個 load balancer 當作例子,平常時會對封包做 modify(DIP, origin_ip) 這樣的 header action 操作,但是當有個後台 server 失去連線,便會將其流量導向其他 server,這就是一個 event 的觸發,新的 action 為 modify(DIP, new_ip)。
彙整 Head Action
前面有提到 Header Action 共分成五種,作者在彙整的時候選擇忽略 forward 這個操作,因為在沒有其他 action 時作者把這個操作當作預設值。
接下來談談怎麼來彙整這些 action。作者利用一個 list 來儲存這些 action,再透過演算法來最佳化這個 list,下面是關於其餘四個 action 的特性:
Drop:只要 list 中有出現 drop,那棄包是必然的結果,同時作者也會把 packet descriptor 設為 null。Encap/Decap:用一個 stack 來模擬 header 的封裝與解封裝,封裝是 push 一個新的 header 到 stack 中,解封裝則是 pop,因此如果有兩個相鄰的封裝與解封裝操作的話那就可以相抵銷。Modify:如果有兩個 action 針對同一個 field 進行修改,則 list 中只會留下後者;如果那兩個 action 針對不同 field 進行修改,則會使用位元運算方式來整合。假設 P0 是原始封包,P1、P2 分別為被 action1、action2 修改過的封包,則可以利用下面式子表達:$$P_0 \oplus [(P_0 \oplus P_1) | (P_0 \oplus P_2)]$$
此外,其他欄位像是 checksum, TTL, MAC address 這些只會在彙整後的最後一刻處理,因為這些操作其實與 NF 的 action 關聯不大,因此在最後一刻處理也能確保最後的結果是正確的。
彙整 State Function
要執行一連串 state function 最重要的是確保新的快速 data path 的 stateful logic 能夠跟原本的鏈一樣。
與 Event Table 協作:
作者把一連串的 state function 當作一個 batch,這個 batch 執行時必須要依照順序執行以避免邏輯上的錯誤。NF 可以決定在什麼情況下 event 才能被觸發進而更新 action/function。
藉由 SpeedyBox 所提供的 register_event() ,可以自行選擇 condition_handler 來檢查這個 event 是否要被觸發。
平行運算:
上面有提過的 IGNORE, READ, WRITE。
下圖為 DOS 預防的 NF 示意圖。
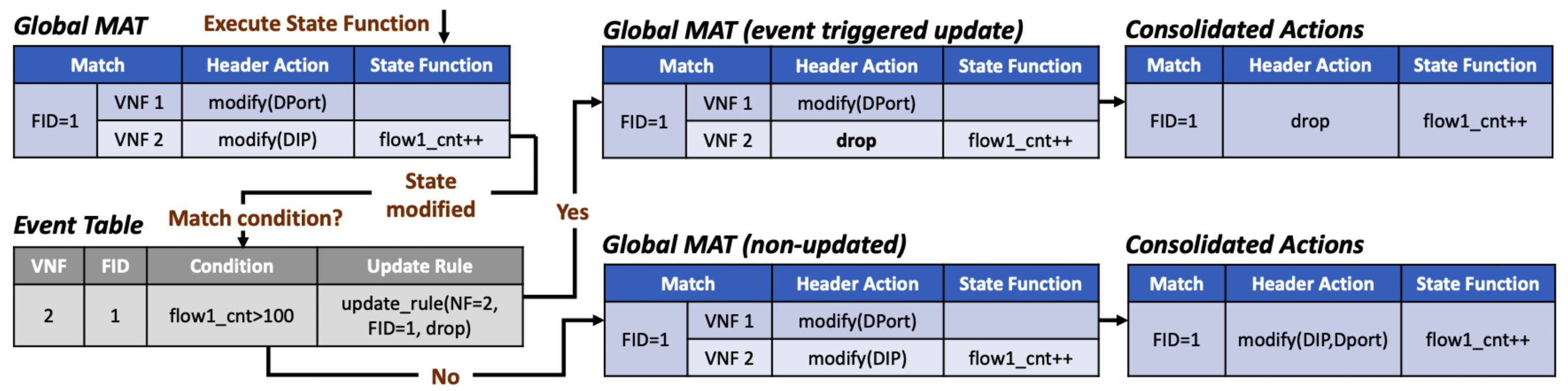
實作
環境
作者將此架構套用在 BESS、OpenNetVM 這兩套NFV 平台上。
- BESS
- entire service chain as a single process
- Global MAT as a global array (so can be accessed by Local MATs)
Taskclass as packet classifier- Global MAT executor as a new BESS module
- 1900 LOC for customization
- OpenNetVM
- each NF on one dedicated core
- Global MAT at the NF Manager
- packet classifier at the Manager’s RX queue thread
- use inter-core communication
- 2800 LOC for customization
Packet Classifier
- FID: 20 bits
- BESS & OpenNetVM 都有提供輕量級的 packet descriptor,因此在鏈中傳輸時不會有太大的 packet copying overhead
- 為了清理不需要的 flow 規則,也會去偵測
TCP_FIN、TCP_RST等 flag 來釋放記憶體資源
Network Functions
作者實作了五個熱門的 network function 並且整合進 SpeedyBox 中。
- Snort 是基於 libpcap 開發的,作者使之與 DPDK 相容。因為 Snort 並不會改變封,header action 只會是
forward,並把檢查封包的函式當作 state function。 - Maglev 是 Google 基於 consistent hashing 的 Load Balancer,由於官方沒有釋出 source code 因此作者自己按照 Google 的描述做了一個。為了避免後端 server 意外失聯,作者設定一個 event 去更新關於 destination IP address 的 header action,並且在 condition handler 中設定 random trigger 來模擬失聯。
- IPFilter 是一套防火牆,會檢查表頭欄位是否符合黑名單的規則,是的話就棄包。
- Monitor 是一套網路監視器,常用於學術界中,包含了 packet counter,預設 forward。
- MazuNAT 是一個在 Click 中的 NAT 模組相似的東西,可以進行 IP port 的轉譯。
評測
- Testbed: E5-2660 (14 cores), 32G RAM, Intel 82500ES 10-Gigabit NIC, Linux 4.4.0
- 在另一台機器以 DPDK 進行開發的 Packet Generator 進行測試,同樣有 10G 網卡,直接接到 testbed(因此可能採用跳線或是 Auto MDIX)
- 所有的測試都是使用 64B 封包
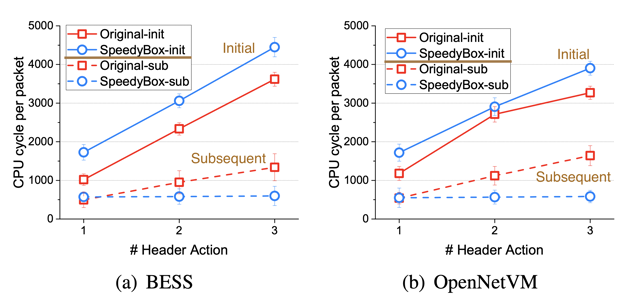
上圖針對使用 1~3 個 NF 進行 Header Action 的 CPU cycle 比較,封包大小為 64 bytes。
由於 BESS 結果與 OpenNetVM 雷同,因此作者接下來會專注在分析 BESS
作者說在 subsequent 中只有 1 個 header function 時,SBox 會比較高是因為 recording the processing rules into the Local MAT
編按:不懂
理論上加速要是 (N-1) / N,實際上 2NF 跟 3NF 只有降低 40.9%、57.7% CPU cycle
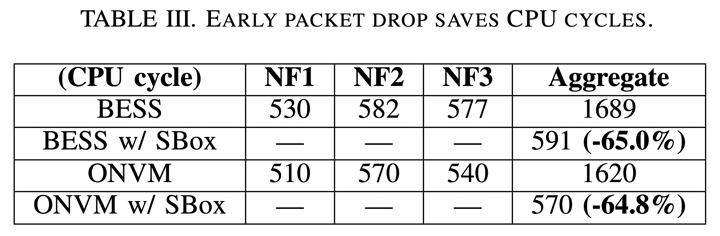
- 這是在講提早 drop
- 因為沒有 NF 了,只剩下 fast data path 因此沒有把 CPU cycle 顯示在上面面
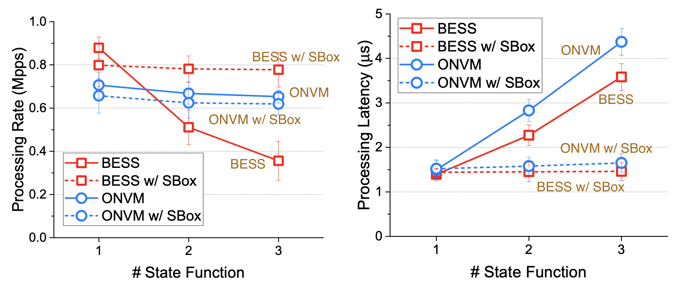
這是在講 state function 採用平行處理後的速度。沒有 header action,只有 state function
因為 ONVM 有 pipeline 處理機制,所以處理速度差不多
編按:是否因為作者的 BESS 只跑在單一核心上?
理論上來說延遲會降低 (N-1)/N,實際上在 BESS 中 3NF 時有降低 59%
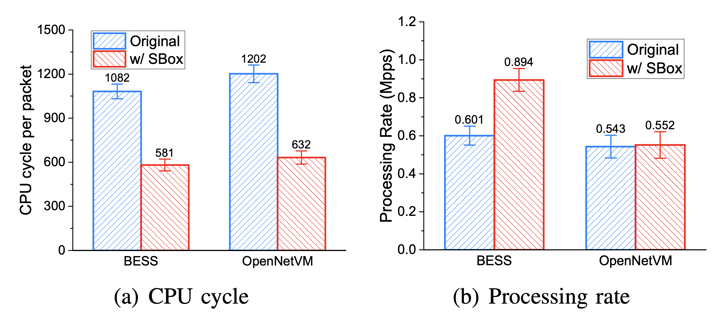
使用 Snort + Monitor 的效能表現
CPU Cycle 下降主因是 header action consolidatation
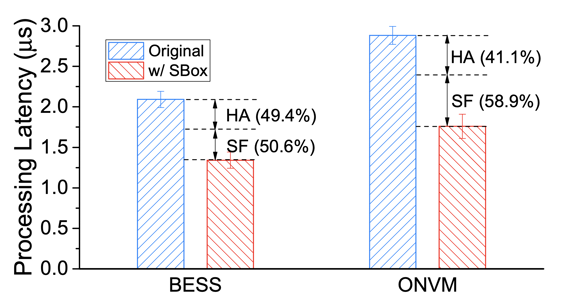
Snort + Monitor 的延遲
ONVM 的 SF 能有 58.9% 是因為 inter-core communication overhead,會造成額外的 CPU cycle,使得 header action 增益有所下降
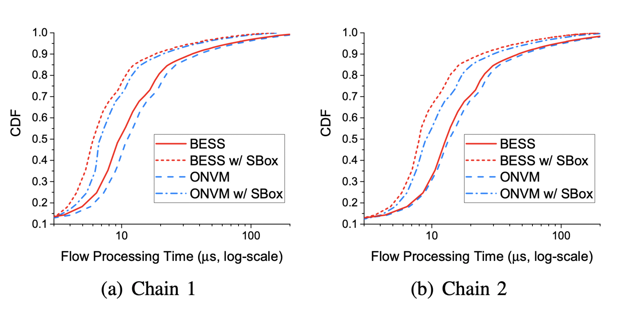
模擬真實環境的效能評測
- MazuNAT + Maglev + Monitor + IPFilter
- IPFilter + Snort + Monitor
comments powered by Disqus